ReliableMath: Benchmark of Reliable Mathematical Reasoning on Large Language Models
作者: Boyang Xue, Qi Zhu, Rui Wang, Sheng Wang, Hongru Wang, Minda Hu, Fei Mi, Yasheng Wang, Lifeng Shang, Qun Liu, Kam-Fai Wong
分类: cs.CL
发布日期: 2025-07-03 (更新: 2025-11-12)
备注: under review
💡 一句话要点
ReliableMath:评估大型语言模型在数学推理中可靠性的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 可靠性评估 不可解问题 数据集构建 对齐策略 LLM可靠性 基准测试
📋 核心要点
- 现有研究缺乏对LLM在数学推理中可靠性的系统评估,尤其是在不可解问题上的表现。
- 论文提出ReliableMath数据集,包含可解和不可解的数学问题,用于评估LLM的可靠性。
- 实验表明,大型LLM在可靠提示下能识别不可解问题,但小型LLM效果不佳,需对齐策略提升。
📝 摘要(中文)
大型语言模型(LLMs)在推理任务中表现出色,但面对无法解决或超出其能力范围的问题时,往往会捏造不可靠的答案,严重损害了可靠性。以往对LLM可靠性的研究主要集中在知识任务上,以识别无法回答的问题,而由于缺乏无法解决的数学问题,数学推理任务的研究仍未被探索。为了系统地研究LLM在数学推理任务中的可靠性,我们制定了可解和不可解问题的可靠性评估方法。然后,我们开发了一个ReliableMath数据集,该数据集包含开源的可解问题和通过我们提出的构建工作流程合成的高质量不可解问题,并经过人工评估。实验在各种LLM上进行,揭示了几个关键发现。LLM无法直接识别不可解的问题,并且总是生成捏造的答案。当指示LLM使用可靠的提示来指示不可解性时,较大型LLM在可解问题上的可靠性仍然存在,但在不可解问题上的可靠性显着提高,但仍未达到可解问题的水平。然而,尽管采用了可靠的提示,小型LLM几乎没有显示出任何进展。因此,我们进一步提出了一种对齐策略来增强小型LLM的可靠性,该策略可以显着提高LLM在领域内和领域外任务中的可靠性表现。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在数学推理任务中,面对不可解问题时,倾向于生成虚假答案的问题。现有方法主要关注LLM在知识型任务中的可靠性,而忽略了数学推理任务,并且缺乏高质量的不可解数学问题数据集,导致无法有效评估LLM在此方面的能力。
核心思路:论文的核心思路是通过构建包含可解和不可解问题的ReliableMath数据集,并设计相应的评估指标,来系统地评估LLM在数学推理中的可靠性。同时,针对小型LLM在识别不可解问题方面的不足,提出一种对齐策略来提升其可靠性。
技术框架:论文的技术框架主要包含三个部分:1) 构建ReliableMath数据集,包括开源的可解问题和通过特定工作流程合成的不可解问题;2) 设计可靠性评估指标,用于评估LLM在可解和不可解问题上的表现;3) 提出对齐策略,用于提升小型LLM在识别不可解问题方面的能力。整体流程为:输入数学问题,LLM生成答案,根据问题类型和答案判断LLM的可靠性,并使用对齐策略优化小型LLM。
关键创新:论文的关键创新点在于:1) 提出了一个系统性的框架来评估LLM在数学推理中的可靠性,尤其是在不可解问题上的表现;2) 构建了一个高质量的ReliableMath数据集,填补了现有研究中缺乏不可解数学问题数据集的空白;3) 提出了一种有效的对齐策略,能够显著提升小型LLM在识别不可解问题方面的能力。
关键设计:在数据集构建方面,论文设计了一个包含多个步骤的工作流程来合成高质量的不可解问题,并进行人工评估以确保质量。在对齐策略方面,具体的技术细节(例如损失函数、网络结构等)在论文中未详细描述,属于未知信息。
🖼️ 关键图片

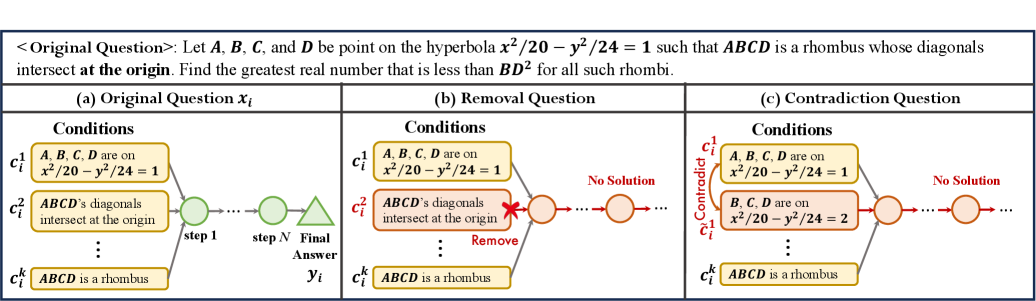
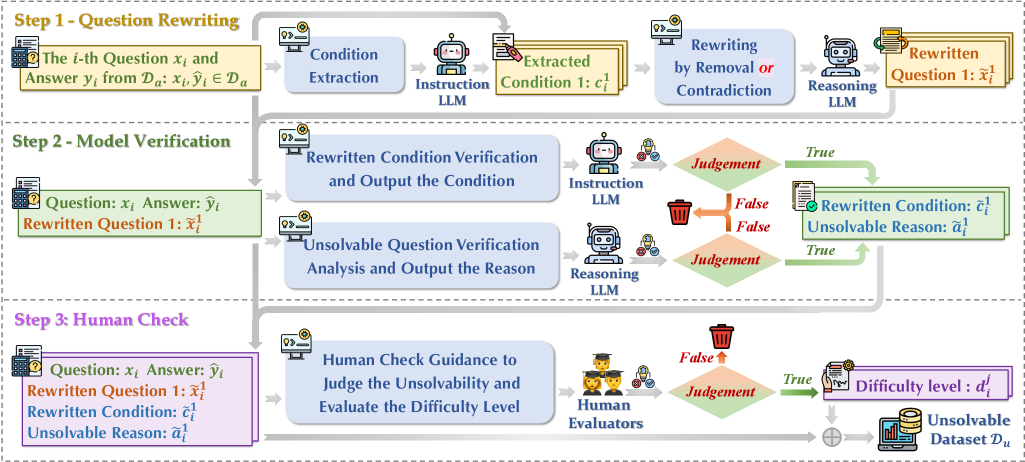
📊 实验亮点
实验结果表明,大型LLM在可靠提示下,在不可解问题上的可靠性得到显著提升,但仍低于可解问题。小型LLM在未采用对齐策略时,几乎无法识别不可解问题。通过提出的对齐策略,小型LLM在领域内和领域外任务中的可靠性均得到显著提升,具体提升幅度未知。
🎯 应用场景
该研究成果可应用于提升LLM在数学教育、科学研究等领域的可靠性。通过提高LLM识别和处理不可解问题的能力,可以避免其生成错误的答案,从而提高用户对LLM的信任度。此外,该数据集和评估方法也可用于评估和比较不同LLM在数学推理方面的能力。
📄 摘要(原文)
Although demonstrating remarkable performance on reasoning tasks, Large Language Models (LLMs) still tend to fabricate unreliable responses when confronted with problems that are unsolvable or beyond their capability, severely undermining the reliability. Prior studies of LLM reliability have primarily focused on knowledge tasks to identify unanswerable questions, while mathematical reasoning tasks have remained unexplored due to the dearth of unsolvable math problems. To systematically investigate LLM reliability in mathematical reasoning tasks, we formulate the reliability evaluation for both solvable and unsolvable problems. We then develop a ReliableMath dataset which incorporates open-source solvable problems and high-quality unsolvable problems synthesized by our proposed construction workflow with human evaluations. Experiments are conducted on various LLMs with several key findings uncovered. LLMs fail to directly identify unsolvable problems and always generate fabricated responses. When instructing LLMs to indicate unsolvability using a reliable prompt, the reliability of larger-sized LLMs remains on solvable problems, but notably improves on unsolvable problems yet still falls short of solvable problems. However, small LLMs rarely show any progress despite employing reliable prompts. Therefore, we further propose an alignment strategy to enhance small LLMs' reliability, which can significantly improve LLM reliability performances on both in-domain and out-of-domain tasks.