ARF-RLHF: Adaptive Reward-Following for RLHF through Emotion-Driven Self-Supervision and Trace-Biased Dynamic Optimization
作者: YuXuan Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-03 (更新: 2025-10-25)
备注: This version fixes some minor typographical errors and adds more explanations to ensure clarity in presentation
💡 一句话要点
ARF-RLHF:通过情感驱动的自监督和轨迹偏置动态优化,实现自适应奖励跟随
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: RLHF 强化学习 自然语言处理 情感分析 大语言模型 偏好学习 自监督学习
📋 核心要点
- 现有RLHF方法依赖代价高昂且粗糙的二元偏好标签,忽略了个体用户反馈的细微差别。
- ARF通过情感分析将自然语言反馈转化为连续偏好轨迹,并使用TraceBias算法进行优化。
- 实验表明,ARF在多个LLM和偏好领域超越PPO和DPO,对齐效果提升高达7.6%。
📝 摘要(中文)
现有的RLHF方法,如PPO和DPO,通常将人类偏好简化为二元标签,这种标签获取成本高昂且过于粗糙,无法反映个体差异。我们观察到,用户表达满意和不满的情感在语言模式上具有稳定性,这意味着可以从自由形式的反馈中提取更具信息量的监督信号。基于此,我们引入了自适应奖励跟随(ARF),它将自然反馈转换为连续的偏好轨迹,并使用新颖的TraceBias算法对其进行优化。在不同的LLM和偏好领域中,ARF始终优于PPO和DPO,对齐效果提升高达7.6%。我们的结果表明,连续奖励建模为实现个性化和理论上可靠的RLHF提供了一条可扩展的路径。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法,如PPO和DPO,主要依赖于二元偏好标签。这些标签的获取需要大量的人工标注,成本高昂。更重要的是,二元标签过于简化了人类的偏好,无法捕捉到用户反馈中蕴含的丰富信息和个体差异,导致模型难以进行个性化对齐。
核心思路:ARF的核心思想是利用用户在自然语言反馈中表达的情感信息,将其转化为连续的偏好轨迹,从而提供更细粒度、更丰富的监督信号。这种方法避免了对二元标签的依赖,能够更好地反映用户的真实偏好,并支持模型的个性化对齐。
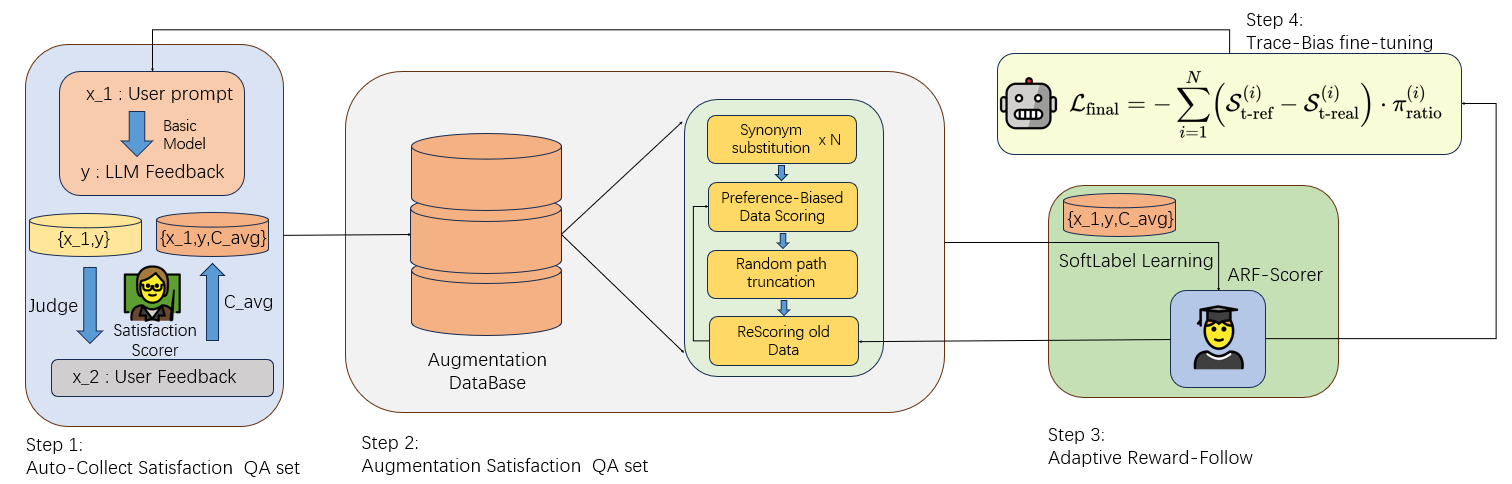
技术框架:ARF框架主要包含以下几个阶段:1) 情感分析:利用情感分析模型从用户的自然语言反馈中提取情感信息,例如满意度、不满意度等。2) 偏好轨迹生成:将提取的情感信息转化为连续的偏好轨迹,该轨迹表示用户在不同时间点对模型输出的偏好程度。3) TraceBias优化:使用TraceBias算法对偏好轨迹进行优化,该算法旨在平衡探索和利用,避免模型陷入局部最优。4) 模型训练:利用优化后的偏好轨迹作为奖励信号,训练LLM,使其更好地对齐用户的偏好。
关键创新:ARF的关键创新在于:1) 连续奖励建模:将人类反馈转化为连续的偏好轨迹,提供了更细粒度的监督信号。2) TraceBias算法:设计了一种新的优化算法,用于平衡探索和利用,避免模型陷入局部最优。3) 情感驱动的自监督:利用情感分析模型自动提取情感信息,减少了对人工标注的依赖。
关键设计:在情感分析阶段,可以使用预训练的情感分类模型,并根据具体任务进行微调。偏好轨迹的生成可以采用线性插值或其他平滑方法。TraceBias算法的具体实现需要仔细调整参数,例如探索率和学习率。损失函数的设计需要考虑偏好轨迹的形状和幅度,以确保模型能够准确地学习用户的偏好。
🖼️ 关键图片
📊 实验亮点
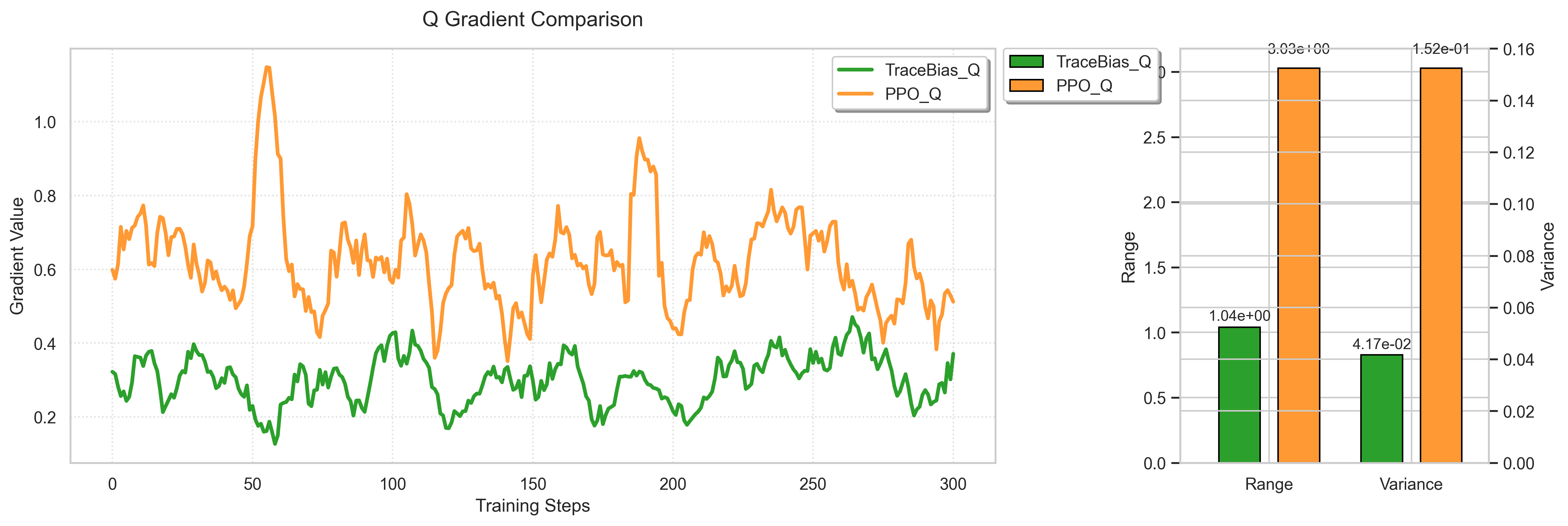
ARF在多个LLM和偏好领域中进行了实验,结果表明ARF始终优于PPO和DPO。具体而言,ARF在对齐效果方面提升高达7.6%。这些结果表明,连续奖励建模是一种有效的RLHF方法,能够更好地利用人类反馈,提高LLM的性能。此外,ARF还具有较好的可扩展性,可以应用于不同的LLM和偏好领域。
🎯 应用场景
ARF-RLHF具有广泛的应用前景,可以应用于各种需要个性化对齐的LLM应用场景,例如智能客服、个性化推荐、创意写作等。通过利用用户的情感反馈,ARF能够使LLM更好地理解用户的需求和偏好,从而提供更符合用户期望的服务。此外,ARF还可以应用于其他类型的AI系统,例如机器人和游戏AI,以提高其与人类用户的交互体验。
📄 摘要(原文)
Current RLHF methods such as PPO and DPO typically reduce human preferences to binary labels, which are costly to obtain and too coarse to reflect individual variation. We observe that expressions of satisfaction and dissatisfaction follow stable linguistic patterns across users, indicating that more informative supervisory signals can be extracted from free-form feedback. Building on this insight, we introduce Adaptive Reward-Following (ARF), which converts natural feedback into continuous preference trajectories and optimizes them using the novel TraceBias algorithm. Across diverse LLMs and preference domains, ARF consistently outperforms PPO and DPO, improving alignment by up to 7.6%. Our results demonstrate that continuous reward modeling provides a scalable path toward personalized and theoretically grounded RLHF.