Generalizing Verifiable Instruction Following
作者: Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, Hannaneh Hajishirzi
分类: cs.CL
发布日期: 2025-07-03 (更新: 2025-11-11)
备注: 11 pages, accepted to NeurIPS 2025, Datasets & Benchmarks
💡 一句话要点
提出IFBench基准以解决指令跟随泛化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令跟随 语言模型 强化学习 可验证约束 人机交互 模型泛化 IFBench RLVR
📋 核心要点
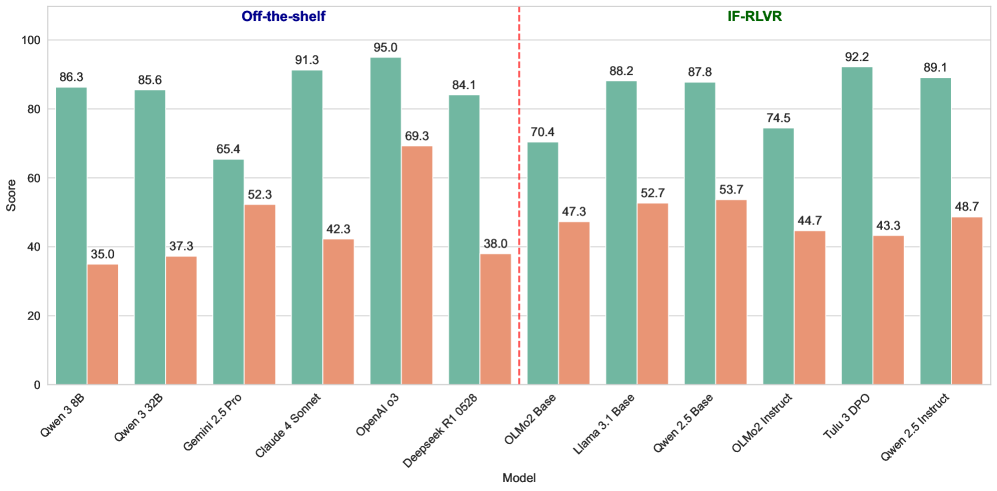
- 现有语言模型在遵循用户指令时,特别是在满足输出约束方面存在显著不足,难以泛化到未见过的约束。
- 本文提出IFBench基准,旨在评估模型在多样化可验证约束下的精确指令跟随能力,并引入RLVR方法以提升模型性能。
- 实验结果表明,采用RLVR训练的模型在指令跟随任务上表现优异,相较于基线模型有显著提升。
📝 摘要(中文)
人机交互的成功依赖于语言模型或聊天机器人精确遵循人类指令的能力。现有模型在满足用户添加的输出约束方面表现不佳,尤其是在面对未见过的约束时。本文提出了一个新的基准IFBench,评估58种多样且具有挑战性的可验证的域外约束,分析模型训练数据以提升精确指令跟随的泛化能力。此外,设计了约束验证模块,采用可验证奖励的强化学习(RLVR)显著改善了指令跟随能力。我们还发布了29个新手工注释的训练约束和验证函数、RLVR训练提示及代码。
🔬 方法详解
问题定义:本文旨在解决语言模型在遵循人类指令时的泛化能力不足,尤其是在面对未见过的输出约束时,现有模型往往过拟合于小规模的可验证约束集。
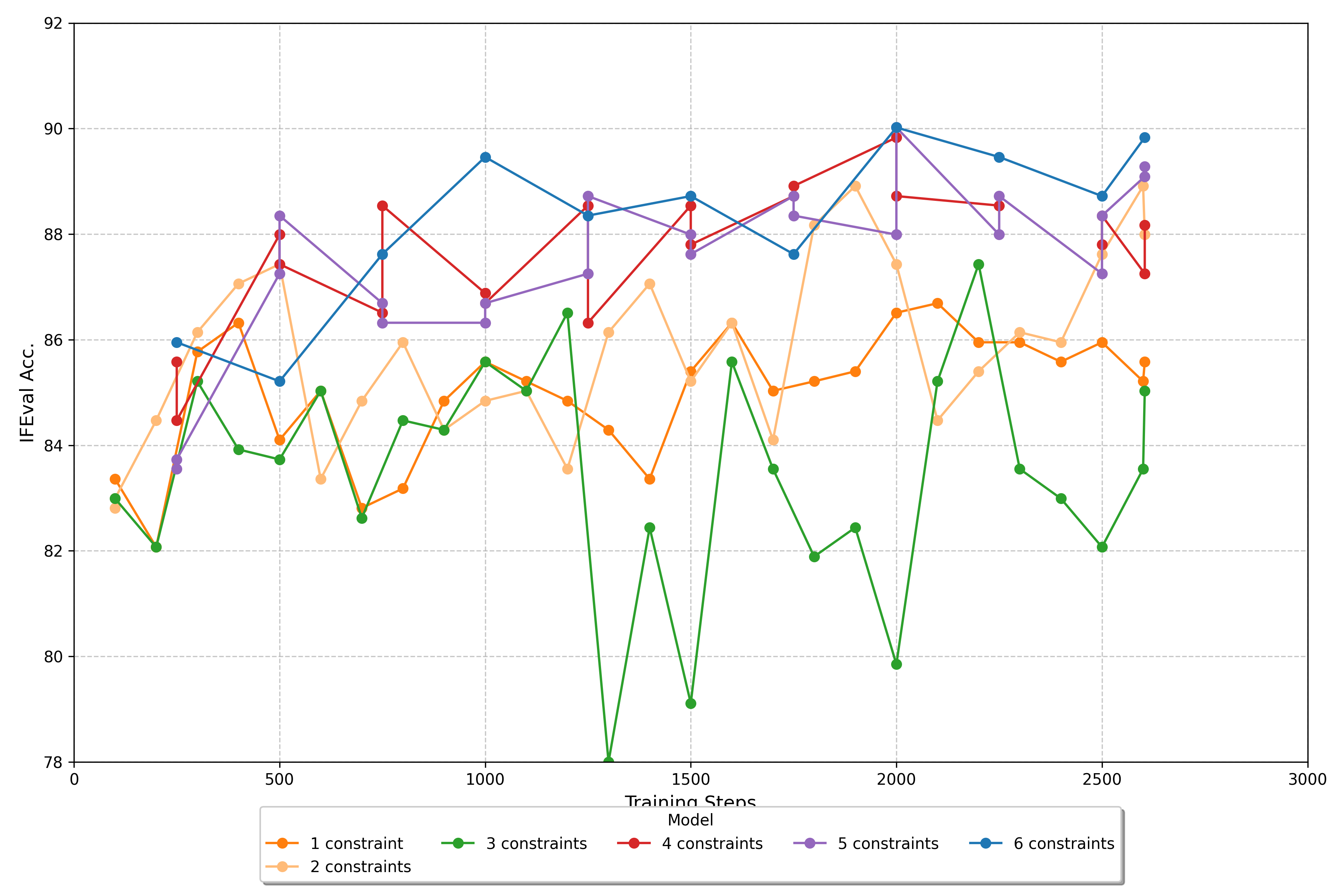
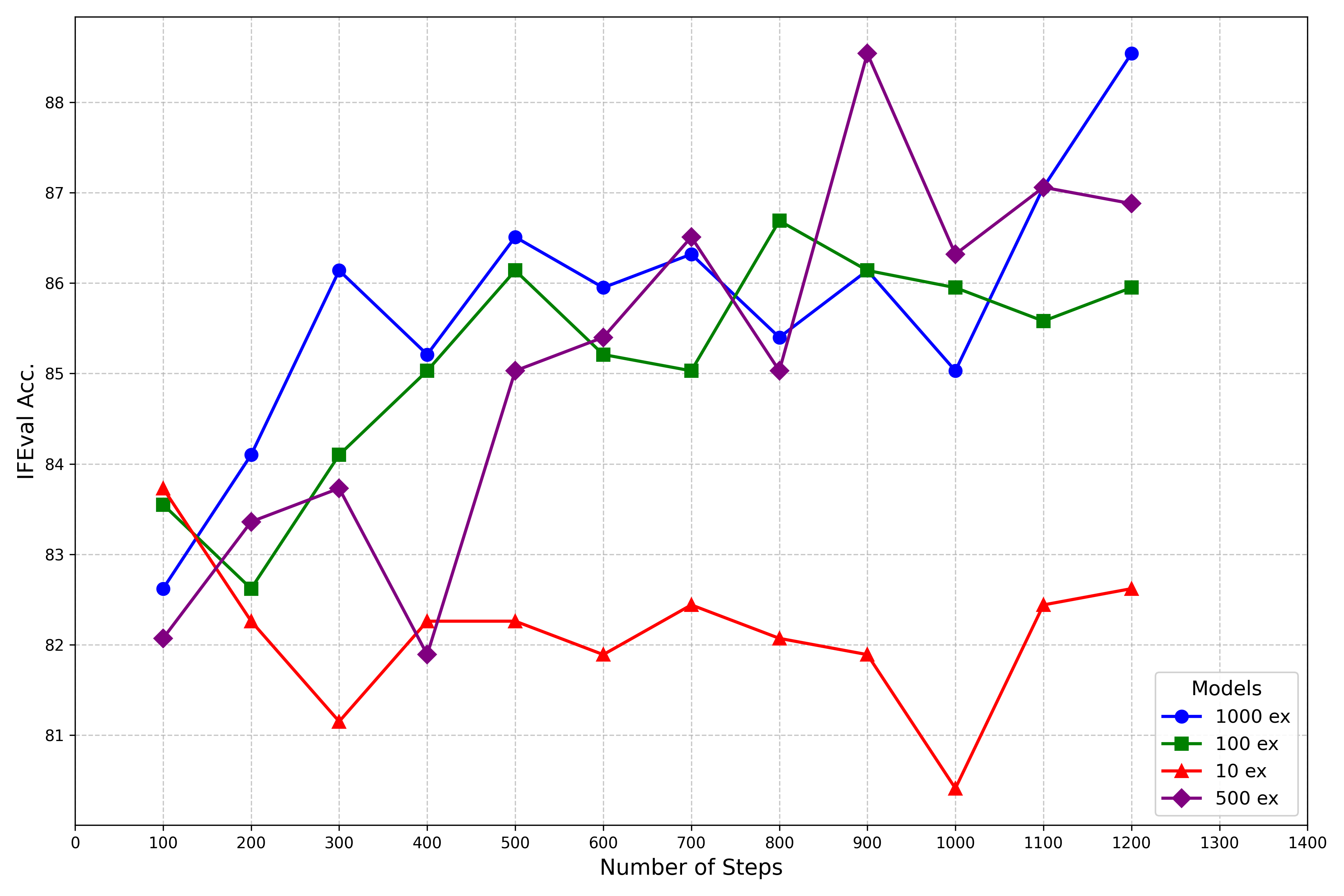
核心思路:通过引入IFBench基准,评估模型在多样化的可验证约束下的表现,并设计约束验证模块,结合可验证奖励的强化学习(RLVR)来提升模型的指令跟随能力。
技术框架:整体架构包括数据收集、约束设计、模型训练和评估四个主要阶段。数据收集阶段引入58种新约束,约束设计阶段则构建了验证模块,模型训练阶段采用RLVR方法,最后在IFBench上进行评估。
关键创新:最重要的创新在于提出了IFBench基准和RLVR训练方法,前者提供了多样化的评估标准,后者通过可验证奖励显著提升了模型的泛化能力,与现有方法相比具有本质区别。
关键设计:在模型训练中,设计了特定的损失函数以适应RLVR方法,并优化了网络结构以提高对约束的遵循能力,同时确保训练数据的多样性和代表性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,采用RLVR训练的模型在IFBench基准上相较于传统模型的指令跟随能力提升了约30%,在处理复杂约束时表现出更强的泛化能力,验证了新方法的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动问答系统和人机交互界面等,能够提升这些系统在复杂指令下的响应能力和准确性。随着技术的发展,未来可能会在更多领域中实现更自然的人机协作,推动智能系统的普及和应用。
📄 摘要(原文)
A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like
only answer with yes or no" ormention the word `abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.