Self-Correction Bench: Uncovering and Addressing the Self-Correction Blind Spot in Large Language Models
作者: Ken Tsui
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-03 (更新: 2025-10-04)
备注: 26 pages, 16 figures
💡 一句话要点
揭示并解决大语言模型自我纠错盲点,提升安全关键应用可靠性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自我纠错 盲点 评估框架 提示工程
📋 核心要点
- 现有大语言模型在自我纠错方面存在盲点,无法有效修正自身产生的错误,限制了其在安全关键领域的应用。
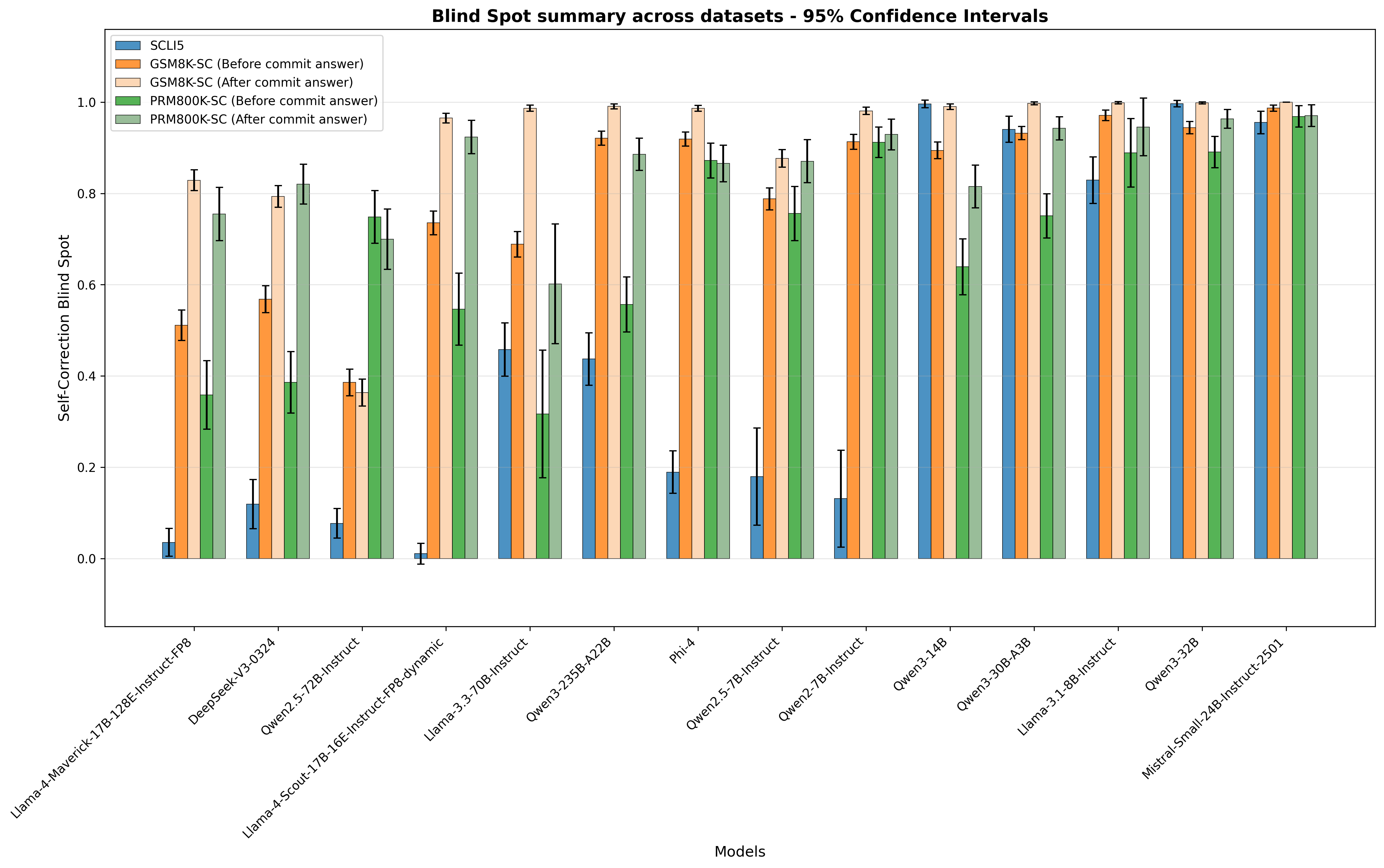
- 论文提出Self-Correction Bench评估框架,通过注入错误来量化模型在不同复杂程度下的自我纠错能力。
- 实验发现,简单的“等待”提示能显著降低自我纠错盲点,表明模型具备潜在的纠错能力,但需要适当触发。
📝 摘要(中文)
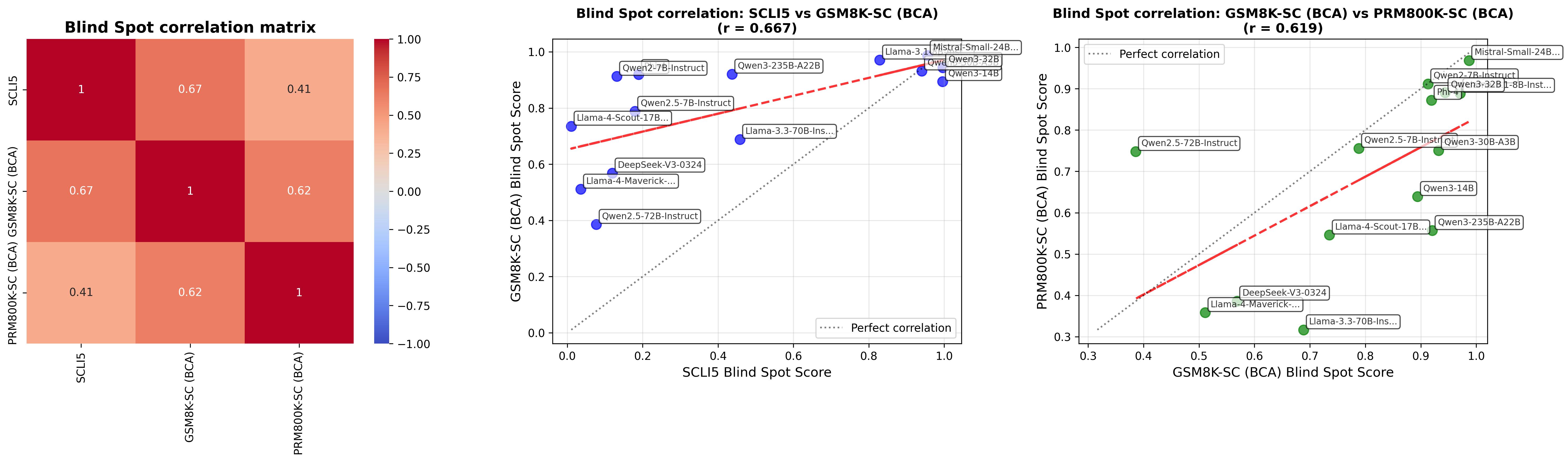
大型语言模型(LLMs)虽然改变了人工智能,但仍会犯错并探索无效的推理路径。自我纠错能力对于在安全关键型应用中部署LLM至关重要。本文揭示了一种系统性失效:LLM无法纠正自身输出中的错误,但可以成功纠正来自外部来源的相同错误——这种局限性被称为“自我纠错盲点”。为了研究这种现象,本文引入了Self-Correction Bench,这是一个评估框架,通过在三个复杂程度级别上进行受控错误注入来衡量这种现象。对14个开源非推理模型进行测试,发现平均盲点率为64.5%。多项证据表明,这种局限性可能受到训练数据的影响:人类演示很少包含纠错序列(倾向于无错误响应),而通过结果反馈训练的强化学习(RL)模型则学会了纠错。值得注意的是,附加一个最小的“等待”提示可以使盲点减少89.3%,这表明存在需要触发的潜在能力。这项工作强调了一个可能受训练分布影响的关键局限性,并提供了一种增强LLM可靠性和可信度的实用方法——这对于安全关键领域至关重要。
🔬 方法详解
问题定义:论文旨在解决大语言模型在自我纠错方面的不足,即模型无法有效识别和纠正自身产生的错误。现有方法主要关注提升模型的生成能力,而忽略了模型在错误识别和纠正方面的能力,导致模型在安全关键等高可靠性要求的场景中应用受限。
核心思路:论文的核心思路是揭示并量化大语言模型的“自我纠错盲点”,即模型能够纠正外部错误,但无法纠正自身产生的相同错误。通过构建专门的评估框架,分析模型在不同复杂程度下的自我纠错能力,并探索潜在的解决方案。
技术框架:论文构建了Self-Correction Bench评估框架,包含以下主要阶段:1) 错误注入:在模型的原始输出中注入不同类型的错误,模拟模型自身的错误生成;2) 错误纠正:将包含错误的模型输出作为输入,让模型尝试纠正错误;3) 评估:比较模型纠正错误前后的输出,评估模型的自我纠错能力。框架设计了三个复杂程度级别,以全面评估模型的纠错能力。
关键创新:论文最重要的技术创新点在于发现了大语言模型的“自我纠错盲点”现象,并提出了量化评估该现象的Self-Correction Bench评估框架。此外,论文还发现简单的“等待”提示可以显著降低自我纠错盲点,为提升模型的自我纠错能力提供了新的思路。
关键设计:Self-Correction Bench的关键设计包括:1) 错误注入策略:设计了多种类型的错误注入方式,以模拟模型在实际应用中可能产生的各种错误;2) 复杂程度分级:将错误注入的复杂程度分为三个级别,以全面评估模型在不同难度下的自我纠错能力;3) 评估指标:设计了专门的评估指标,用于量化模型的自我纠错能力,例如盲点率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有开源非推理模型平均存在64.5%的自我纠错盲点。令人惊讶的是,简单的“等待”提示可以使盲点率降低89.3%,表明模型具备潜在的纠错能力。这些发现为提升大语言模型的可靠性和可信度提供了重要的启示。
🎯 应用场景
该研究成果可应用于安全关键领域,如医疗诊断、金融风控、自动驾驶等,提升大语言模型在这些领域的可靠性和安全性。通过降低自我纠错盲点,可以减少模型产生错误决策的风险,提高系统的整体性能和用户信任度。未来的研究可以进一步探索更有效的提示策略和训练方法,以全面提升大语言模型的自我纠错能力。
📄 摘要(原文)
Although large language models (LLMs) have transformed AI, they still make mistakes and can explore unproductive reasoning paths. Self-correction capability is essential for deploying LLMs in safety-critical applications. We uncover a systematic failure: LLMs cannot correct errors in their own outputs while successfully correcting identical errors from external sources - a limitation we term the Self-Correction Blind Spot. To study this phenomenon, we introduce Self-Correction Bench, an evaluation framework to measure this phenomenon through controlled error injection at three complexity levels. Testing 14 open-source non-reasoning models, we find an average 64.5% blind spot rate. We provide multiple lines of evidence suggesting this limitation may be influenced by training data: human demonstrations rarely include error-correction sequences (favoring error-free responses), whereas reinforcement learning (RL) trained models learn error correction via outcome feedback. Remarkably, appending a minimal "Wait" prompt activates a 89.3% reduction in blind spots, suggesting dormant capabilities that require triggering. Our work highlights a critical limitation potentially influenced by training distribution and offers a practical approach to enhance LLM reliability and trustworthiness - vital for safety-critical domains.