Efficient Code LLM Training via Distribution-Consistent and Diversity-Aware Data Selection
作者: Weijie Lyu, Sheng-Jun Huang, Xuan Xia
分类: cs.CL
发布日期: 2025-07-03
💡 一句话要点
提出基于分布一致性和多样性感知的数据选择方法,提升代码大语言模型训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 数据选择 分布一致性 多样性 高效训练
📋 核心要点
- 现有代码大语言模型训练主要依赖大量数据,忽略了数据质量,导致训练效率降低。
- 论文提出一种参数化模型的数据选择方法,保证选择子集的分布一致性和多样性。
- 实验表明,该方法仅用少量数据即可超越全量数据训练的基线,显著提升训练效率。
📝 摘要(中文)
本文提出了一种利用参数化模型进行代码数据选择的方法,旨在提高代码大语言模型(LLM)的训练效率和模型性能。该方法优化参数化模型,以确保所选子集中的分布一致性和多样性,从而保证高质量的数据。实验结果表明,仅使用1万个样本,该方法在HumanEval和MBPP上分别实现了2.4%和2.3%的增益,优于9.2万个全量样本的基线,并且在性能和效率上均优于其他采样方法。这表明该方法有效地提升了模型性能,同时显著降低了计算成本。
🔬 方法详解
问题定义:现有代码大语言模型训练方法主要依赖于增加数据量来提升模型性能,但忽略了数据质量,导致训练效率低下。如何在保证数据质量的前提下,减少训练数据量,提升训练效率是一个关键问题。
核心思路:论文的核心思路是通过一个参数化模型来选择训练数据子集。该模型的目标是选择一个既能保持原始数据分布,又具有足够多样性的子集。通过优化这个参数化模型,可以筛选出高质量的训练数据,从而提高训练效率和模型性能。
技术框架:该方法包含以下几个主要阶段:1) 使用参数化模型对原始代码数据集进行评分;2) 基于评分选择一个数据子集;3) 优化参数化模型,使其选择的子集满足分布一致性和多样性要求。整个框架旨在找到一个平衡点,既能保证数据质量,又能减少数据量。
关键创新:该方法最重要的创新点在于同时考虑了数据子集的分布一致性和多样性。传统的采样方法往往只关注数据量或者简单的数据质量指标,而忽略了数据分布的重要性。通过显式地建模数据分布,并将其作为优化目标的一部分,可以更有效地选择出高质量的训练数据。
关键设计:论文的关键设计包括:1) 使用一个可学习的参数化模型来对数据进行评分,例如可以使用一个小型的神经网络;2) 定义了分布一致性损失函数,用于衡量选择的数据子集与原始数据集之间的分布差异;3) 定义了多样性损失函数,用于鼓励选择的数据子集包含更多不同的样本。通过联合优化这两个损失函数,可以得到一个既能保持数据分布,又具有足够多样性的数据子集。
🖼️ 关键图片

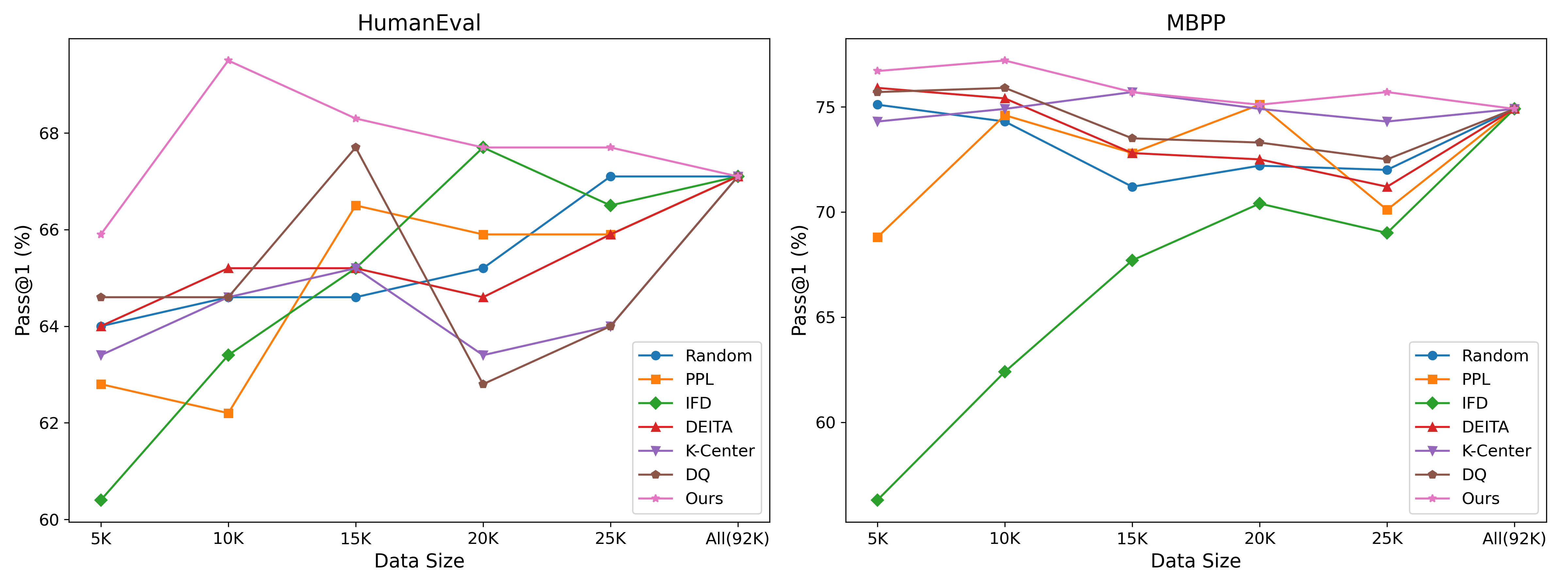
📊 实验亮点
实验结果表明,使用该方法选择的1万个样本,在HumanEval和MBPP代码生成任务上,分别取得了2.4%和2.3%的性能提升,超过了使用9.2万个全量样本训练的基线模型。这表明该方法能够以更少的计算资源,获得更好的模型性能,验证了其有效性。
🎯 应用场景
该研究成果可应用于各种代码大语言模型的预训练和微调阶段,尤其是在计算资源有限的情况下,可以显著提高训练效率和模型性能。此外,该方法也可以推广到其他类型的数据集,例如文本、图像等,用于提高其他类型模型的训练效率。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have significantly improved code generation and program comprehension, accelerating the evolution of software engineering. Current methods primarily enhance model performance by leveraging vast amounts of data, focusing on data quantity while often overlooking data quality, thereby reducing training efficiency. To address this, we introduce an approach that utilizes a parametric model for code data selection, aimed at improving both training efficiency and model performance. Our method optimizes the parametric model to ensure distribution consistency and diversity within the selected subset, guaranteeing high-quality data. Experimental results demonstrate that using only 10K samples, our method achieves gains of 2.4% (HumanEval) and 2.3% (MBPP) over 92K full-sampled baseline, outperforming other sampling approaches in both performance and efficiency. This underscores that our method effectively boosts model performance while significantly reducing computational costs.