Coling-UniA at SciVQA 2025: Few-Shot Example Retrieval and Confidence-Informed Ensembling for Multimodal Large Language Models
作者: Christian Jaumann, Annemarie Friedrich, Rainer Lienhart
分类: cs.CL
发布日期: 2025-07-03
备注: Accepted at 5th Workshop on Scholarly Document Processing @ ACL 2025
💡 一句话要点
针对科学视觉问答,提出基于少样本检索和置信度加权集成的多模态大语言模型方案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学视觉问答 多模态大语言模型 少样本学习 示例检索 置信度集成
📋 核心要点
- 现有科学视觉问答方法在处理复杂图表和问题时存在不足,难以有效利用少量样本进行学习。
- 论文提出一种基于少样本示例检索和置信度加权集成的方案,针对不同图表和问题类型选择合适的模型和设置。
- 实验结果表明,该系统在SciVQA 2025共享任务中取得了优异成绩,平均F1分数达到85.12,排名第三。
📝 摘要(中文)
本文介绍了我们在SciVQA 2025共享任务(科学视觉问答)中使用的系统。该系统采用了两个多模态大语言模型的集成,并结合了多种少样本示例检索策略。模型和少样本设置的选择取决于图表和问题的类型。我们还根据模型的置信度水平来选择答案。在盲测数据上,我们的系统在七个参赛队伍中排名第三,ROUGE-1、ROUGE-L和BERTS的平均F1分数为85.12。我们的代码已公开。
🔬 方法详解
问题定义:论文旨在解决科学视觉问答(SciVQA)任务,即根据给定的科学图表和问题,生成准确的答案。现有方法在处理复杂图表和问题时,往往难以充分利用少量样本进行有效学习,泛化能力受限。此外,不同模型在不同类型的问题上表现各异,如何有效集成多个模型的优势也是一个挑战。
核心思路:论文的核心思路是结合少样本示例检索和置信度加权集成,充分利用少量样本信息,并融合多个多模态大语言模型的优势。通过针对不同图表和问题类型选择合适的模型和少样本设置,提高模型的准确性和鲁棒性。同时,根据模型的置信度水平对答案进行加权,进一步提升集成效果。
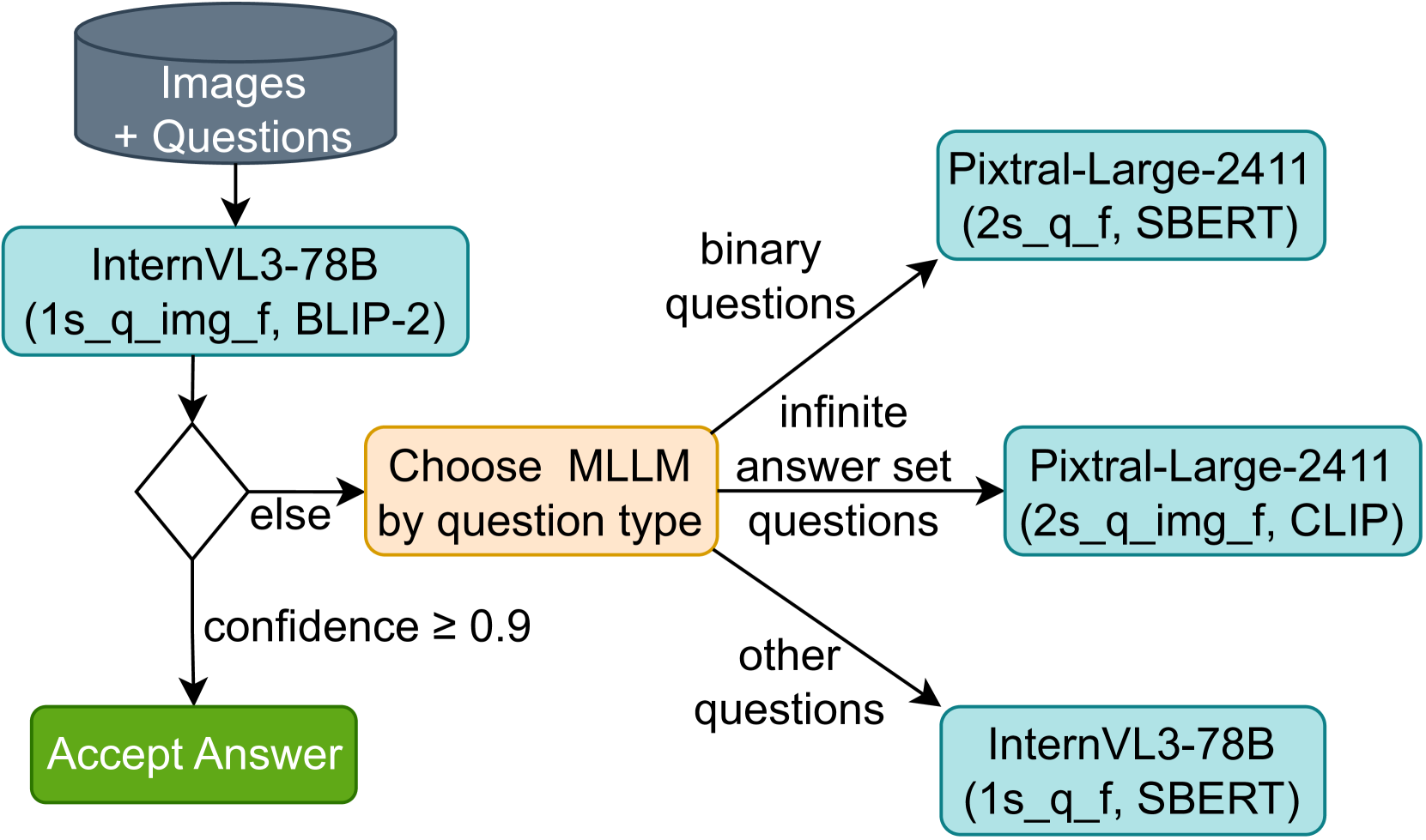
技术框架:该系统主要包含以下几个模块:1) 少样本示例检索模块:根据图表和问题类型,从少量样本中检索出最相关的示例。2) 多模态大语言模型:使用两个不同的多模态大语言模型,分别对问题进行回答。3) 模型选择模块:根据图表和问题类型,选择合适的模型和少样本设置。4) 置信度评估模块:评估每个模型对答案的置信度。5) 答案集成模块:根据模型的置信度水平,对答案进行加权集成,生成最终答案。
关键创新:论文的关键创新在于:1) 提出了一种基于图表和问题类型的少样本示例检索策略,能够更有效地利用少量样本信息。2) 提出了一种基于模型置信度的答案集成方法,能够更好地融合多个模型的优势。3) 针对SciVQA任务,探索了多种多模态大语言模型的集成方案,并取得了良好的效果。
关键设计:论文中关键的设计包括:1) 少样本示例检索策略的具体实现方式,例如使用余弦相似度或语义相似度来衡量图表和问题之间的相关性。2) 模型置信度的评估方法,例如使用模型的输出概率或交叉熵损失来衡量置信度。3) 答案集成的加权策略,例如使用线性加权或指数加权等方法。具体的参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
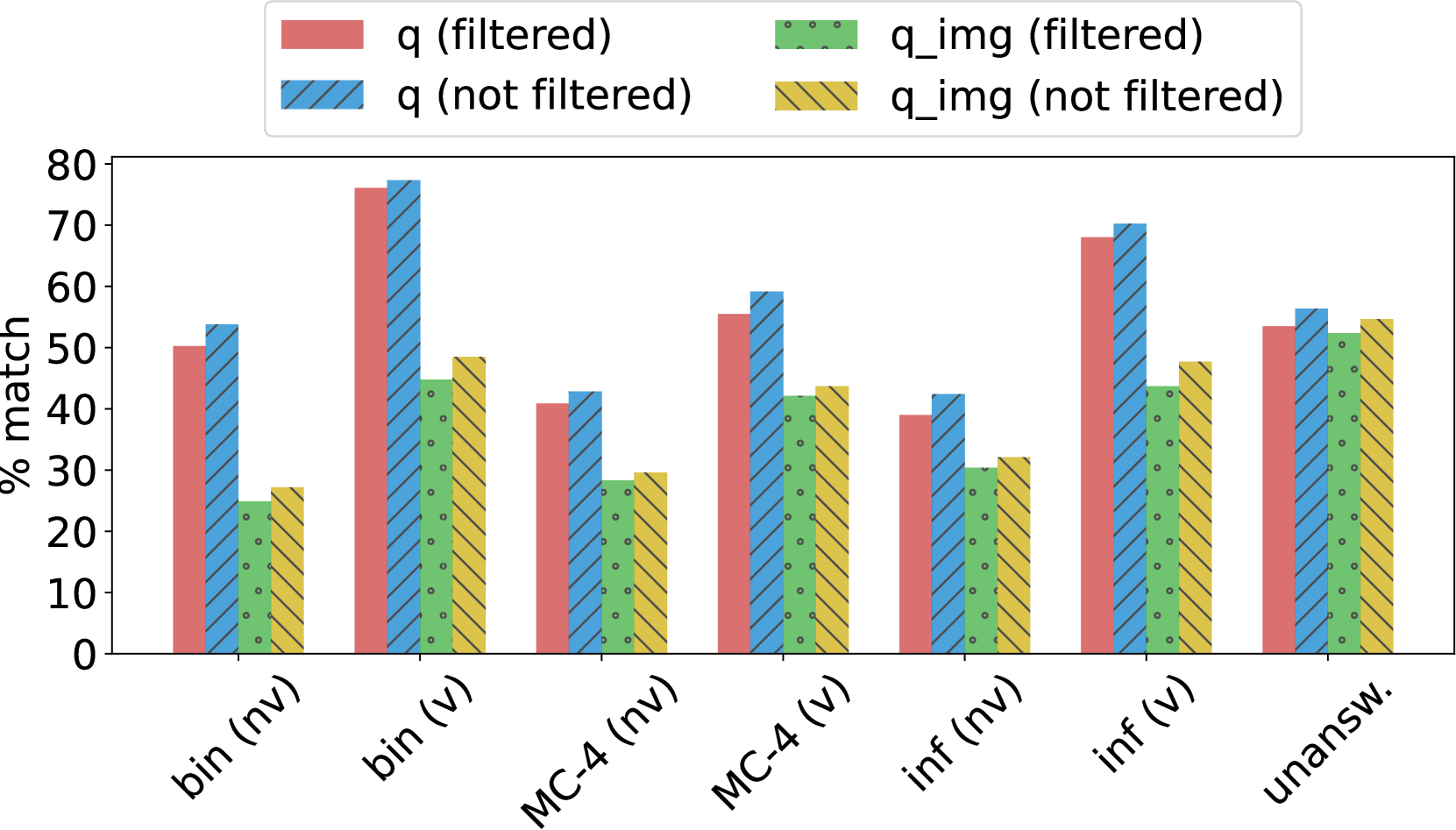
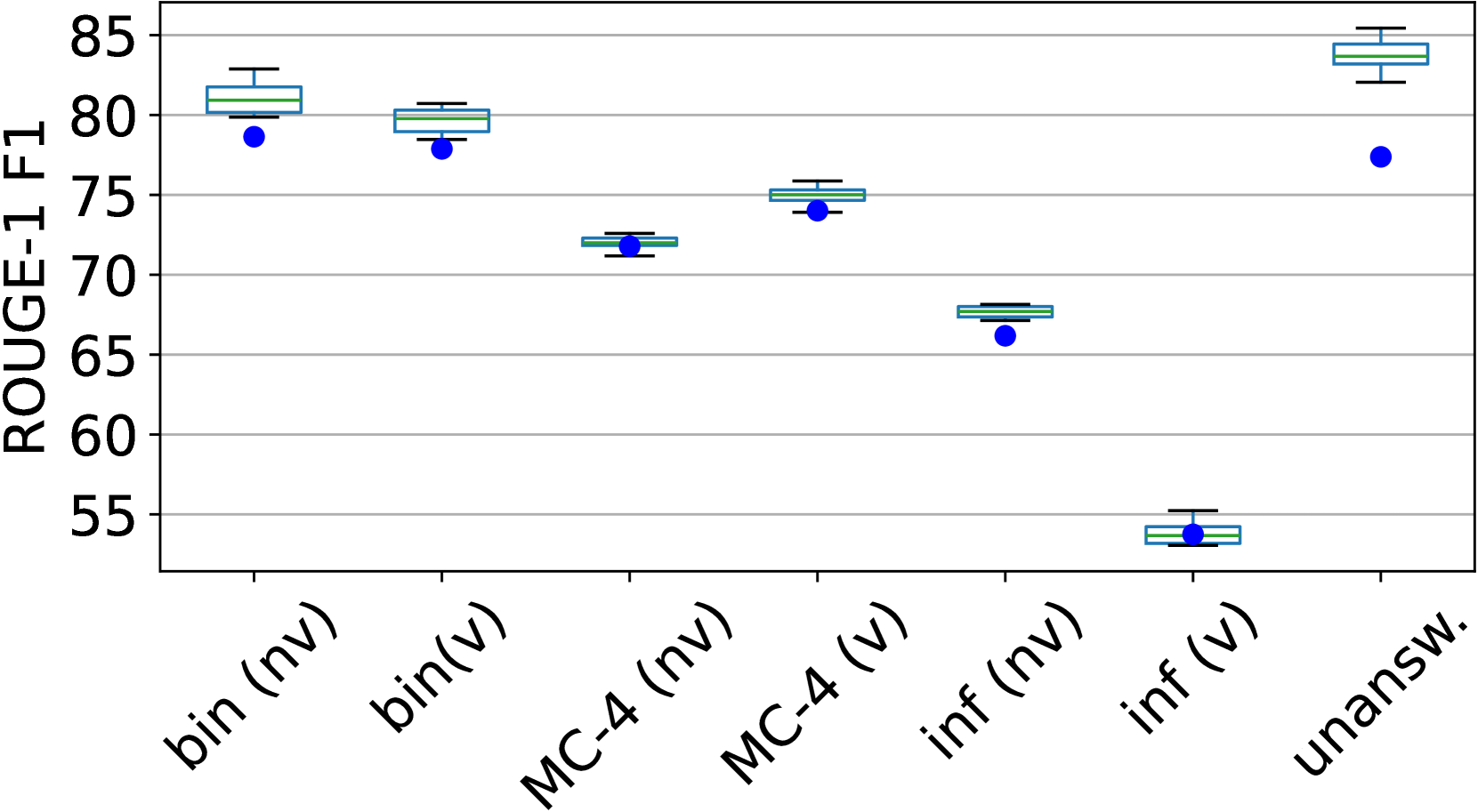
该系统在SciVQA 2025共享任务的盲测数据上取得了第三名的成绩,ROUGE-1、ROUGE-L和BERTS的平均F1分数为85.12。这表明该系统在科学视觉问答任务上具有较强的竞争力,能够有效处理复杂图表和问题,并充分利用少量样本信息。
🎯 应用场景
该研究成果可应用于教育、科研等领域,帮助用户理解科学图表,提高科学素养。例如,可以构建智能答疑系统,自动解答学生或研究人员关于科学图表的问题。未来,该技术还可以扩展到其他类型的视觉问答任务,例如医学影像诊断、工业质检等。
📄 摘要(原文)
This paper describes our system for the SciVQA 2025 Shared Task on Scientific Visual Question Answering. Our system employs an ensemble of two Multimodal Large Language Models and various few-shot example retrieval strategies. The model and few-shot setting are selected based on the figure and question type. We also select answers based on the models' confidence levels. On the blind test data, our system ranks third out of seven with an average F1 score of 85.12 across ROUGE-1, ROUGE-L, and BERTS. Our code is publicly available.