Intrinsic Fingerprint of LLMs: Continue Training is NOT All You Need to Steal A Model!
作者: Do-hyeon Yoon, Minsoo Chun, Thomas Allen, Hans Müller, Min Wang, Rajesh Sharma
分类: cs.CR, cs.CL, cs.LG
发布日期: 2025-07-02
备注: This paper flags a potential case of model plagiarism, copyright violation, and information fabrication in arXiv:2505.21411
💡 一句话要点
提出基于注意力参数分布指纹的LLM溯源方法,可有效应对持续训练攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型指纹 模型溯源 版权保护 持续训练 注意力机制 参数分布 模型安全
📋 核心要点
- 现有LLM水印技术难以抵抗持续训练,模型溯源和版权保护面临挑战。
- 利用注意力参数矩阵标准差分布的稳定性,构建模型固有指纹。
- 实验表明该方法能有效识别模型血统,甚至发现潜在抄袭行为。
📝 摘要(中文)
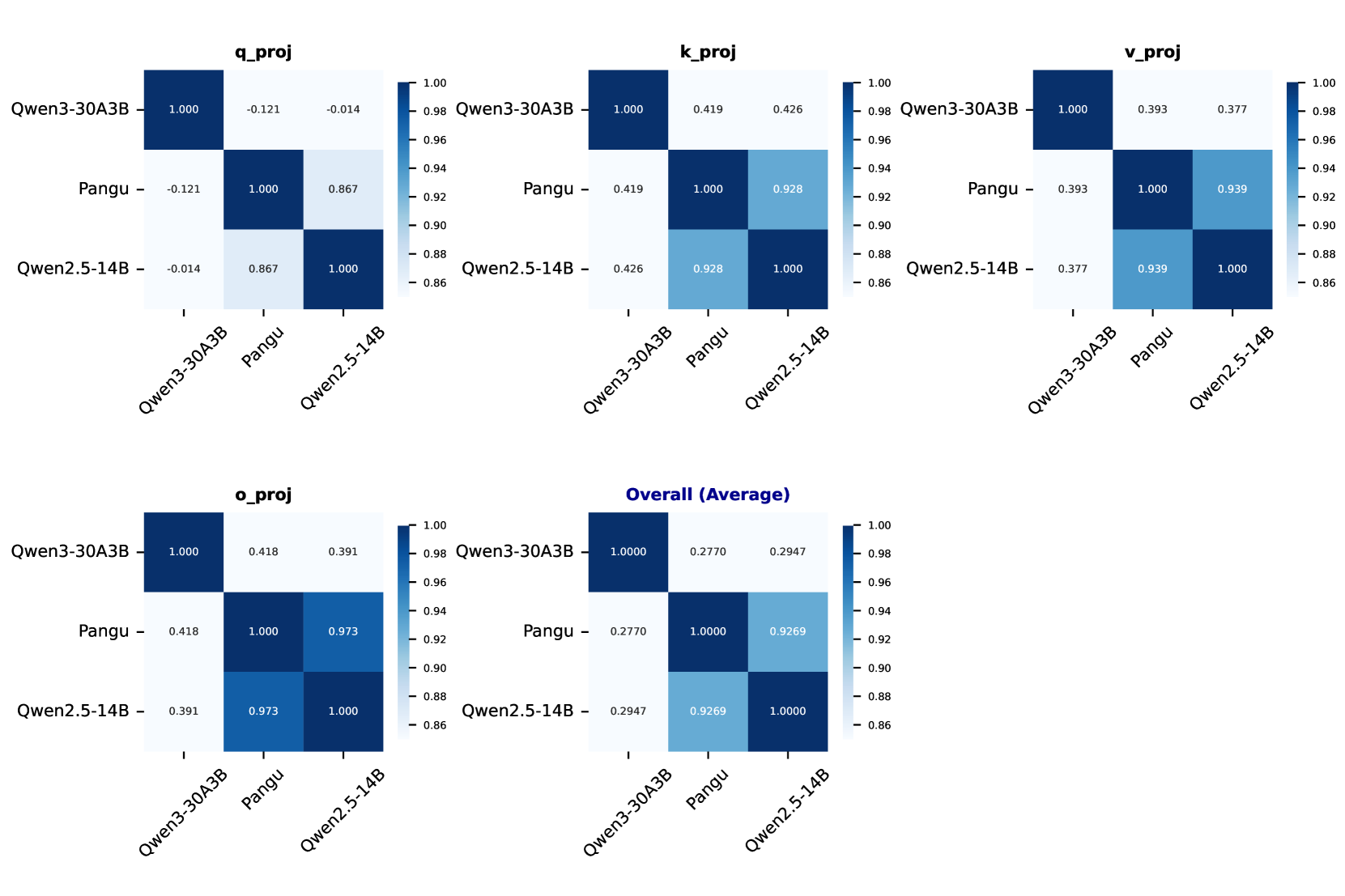
大型语言模型(LLM)面临着日益严峻的版权和知识产权挑战,因为训练成本不断增加,模型复用变得普遍。虽然水印技术已被提出来保护模型所有权,但它们可能无法抵抗持续训练和开发,从而对模型归属和版权保护构成严重威胁。本文介绍了一种简单而有效的LLM指纹识别方法,该方法基于模型固有的特征。我们发现,不同层注意力参数矩阵的标准差分布呈现出独特的模式,即使在经过大量的持续训练后仍然保持稳定。这些参数分布签名作为鲁棒的指纹,可以可靠地识别模型谱系并检测潜在的版权侵权行为。我们在多个模型家族上的实验验证证明了我们方法的有效性。值得注意的是,我们的调查发现,华为最近发布的盘古Pro MoE模型是通过升级改造技术从Qwen-2.5 14B模型派生而来,而不是从头开始训练,这突出了潜在的模型抄袭、侵犯版权和信息捏造的案例。这些发现强调了开发鲁棒的指纹识别方法对于保护大规模模型开发中的知识产权至关重要,并强调仅靠有意的持续训练不足以完全掩盖模型的来源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的版权保护和溯源问题。现有的水印技术在面对持续训练时容易失效,使得恶意使用者可以通过持续训练来掩盖模型的来源,从而逃避版权追责。因此,需要一种鲁棒的指纹识别方法,即使在经过大量持续训练后,也能准确地识别模型的原始来源。
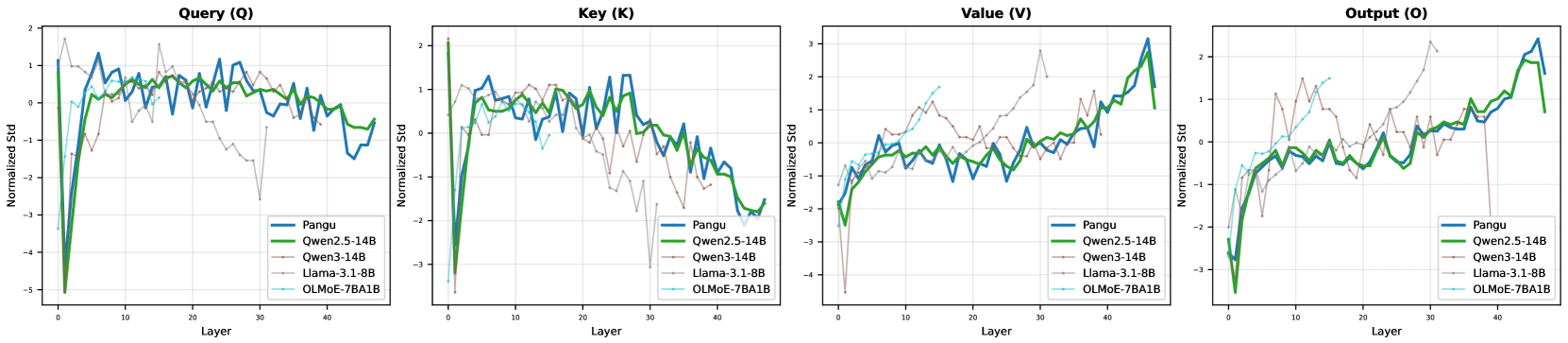
核心思路:论文的核心思路是利用LLM中注意力参数矩阵的统计特性作为模型的固有指纹。具体来说,论文发现不同层注意力参数矩阵的标准差分布呈现出独特的模式,并且这种模式在经过大量的持续训练后仍然保持稳定。因此,可以通过比较不同模型的注意力参数矩阵标准差分布来判断它们是否具有相同的来源。
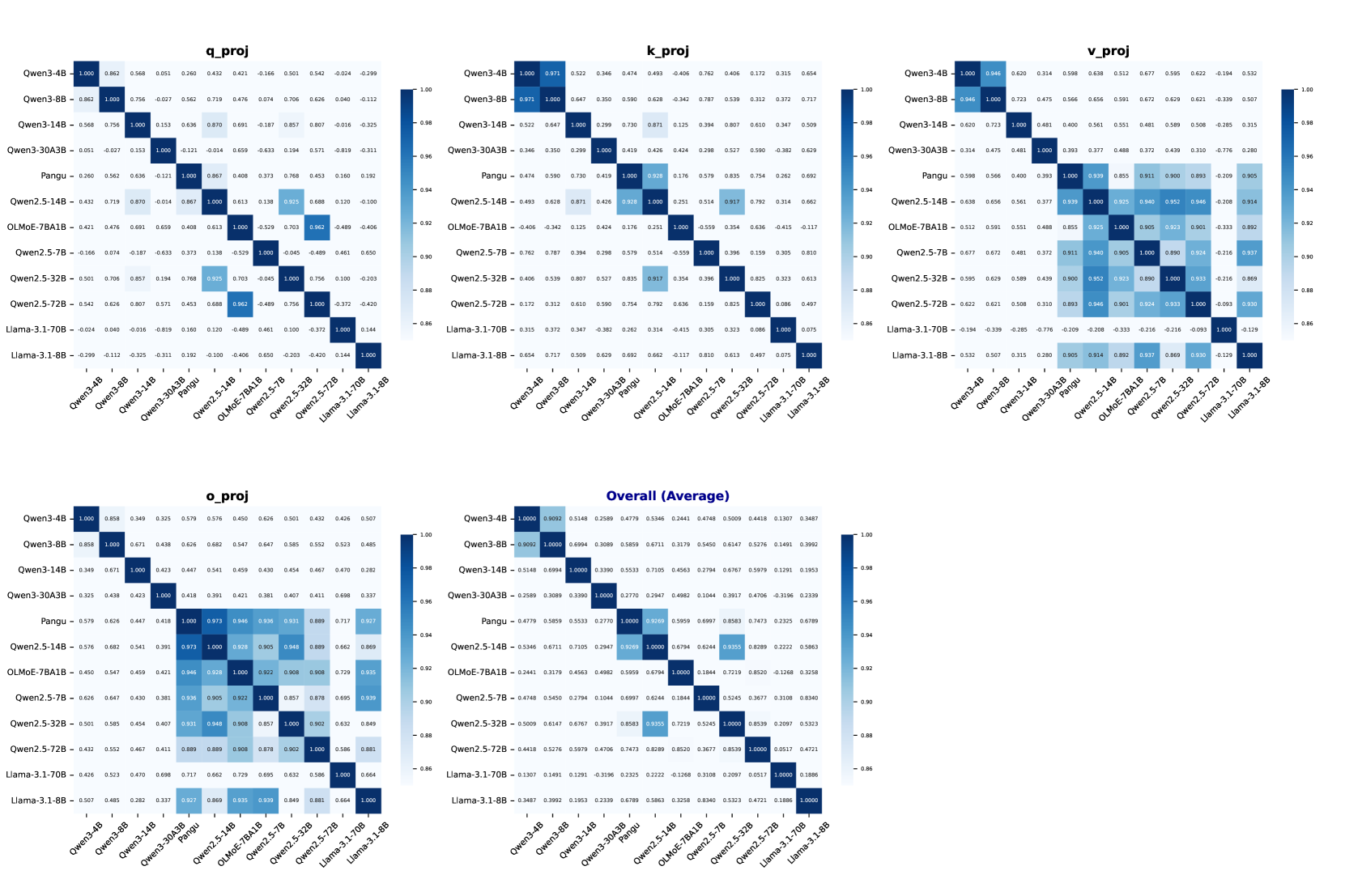
技术框架:该方法主要包含以下几个步骤:1) 提取目标LLM各层注意力参数矩阵;2) 计算每个注意力参数矩阵的标准差;3) 统计所有层注意力参数矩阵标准差的分布;4) 将该分布作为模型的指纹;5) 通过比较不同模型的指纹来判断它们的相似度,从而推断它们的来源关系。
关键创新:该方法最重要的创新点在于发现了LLM注意力参数矩阵标准差分布的稳定性。与传统的水印方法不同,该方法不需要在模型中嵌入任何额外的信息,而是利用模型固有的统计特性作为指纹,因此更加鲁棒,难以被篡改或移除。此外,该方法不需要访问模型的训练数据,只需要访问模型的参数即可,因此更加方便实用。
关键设计:该方法的关键设计在于选择注意力参数矩阵的标准差作为指纹的特征。注意力机制是LLM的核心组成部分,其参数矩阵包含了模型学习到的重要知识。标准差可以反映参数矩阵的离散程度,从而捕捉到模型在训练过程中形成的独特模式。此外,标准差的计算简单高效,易于实现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个模型家族上都具有良好的指纹识别效果,即使在经过大量的持续训练后,也能准确地识别模型的原始来源。更令人惊讶的是,该方法还成功地揭示了华为盘古Pro MoE模型可能来源于Qwen-2.5 14B模型,这表明该方法具有很强的实际应用价值。
🎯 应用场景
该研究成果可应用于LLM的版权保护、模型溯源和安全审计等领域。例如,可以利用该方法来检测是否存在模型抄袭或侵权行为,从而保护模型开发者的知识产权。此外,还可以利用该方法来追踪模型的演化过程,了解模型在不同阶段的学习情况,从而提高模型的安全性和可靠性。该技术还有助于构建更透明、可信的AI生态系统。
📄 摘要(原文)
Large language models (LLMs) face significant copyright and intellectual property challenges as the cost of training increases and model reuse becomes prevalent. While watermarking techniques have been proposed to protect model ownership, they may not be robust to continue training and development, posing serious threats to model attribution and copyright protection. This work introduces a simple yet effective approach for robust LLM fingerprinting based on intrinsic model characteristics. We discover that the standard deviation distributions of attention parameter matrices across different layers exhibit distinctive patterns that remain stable even after extensive continued training. These parameter distribution signatures serve as robust fingerprints that can reliably identify model lineage and detect potential copyright infringement. Our experimental validation across multiple model families demonstrates the effectiveness of our method for model authentication. Notably, our investigation uncovers evidence that a recently Pangu Pro MoE model released by Huawei is derived from Qwen-2.5 14B model through upcycling techniques rather than training from scratch, highlighting potential cases of model plagiarism, copyright violation, and information fabrication. These findings underscore the critical importance of developing robust fingerprinting methods for protecting intellectual property in large-scale model development and emphasize that deliberate continued training alone is insufficient to completely obscure model origins.