High-Layer Attention Pruning with Rescaling
作者: Songtao Liu, Peng Liu
分类: cs.CL, cs.LG
发布日期: 2025-07-02
💡 一句话要点
提出高层注意力头剪枝与重缩放方法,提升LLM生成任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型剪枝 注意力机制 模型压缩 推理加速
📋 核心要点
- 现有结构化剪枝方法忽略了注意力头在网络中的位置,采用启发式指标进行无差别剪枝。
- 该论文提出一种策略性剪枝高层注意力头的方法,并引入自适应重缩放参数来校准表示尺度。
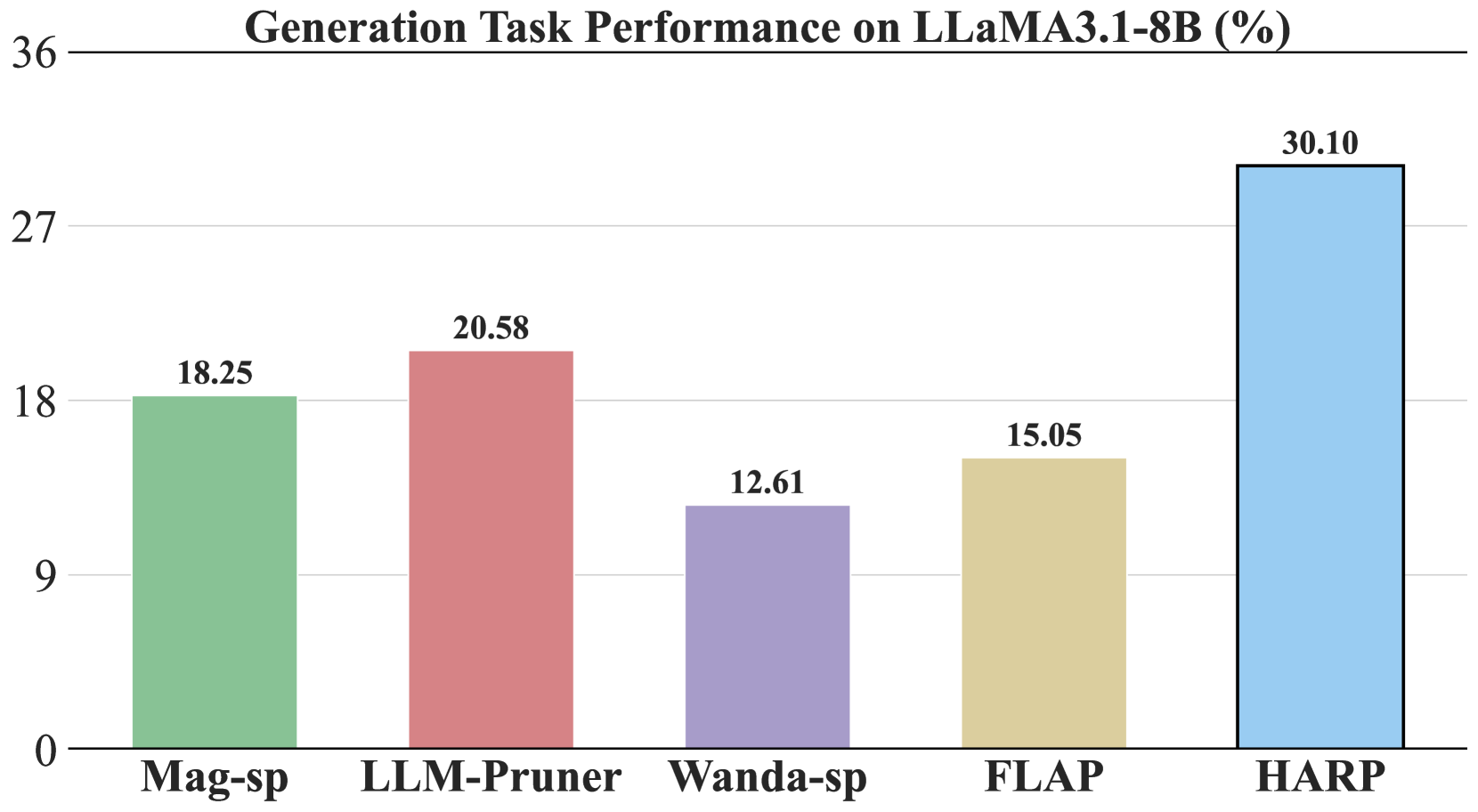
- 实验结果表明,该方法在多种LLM和数据集上优于现有方法,尤其在生成任务中提升显著。
📝 摘要(中文)
剪枝是压缩大型语言模型(LLMs)的有效方法,能显著降低推理延迟。然而,传统的免训练结构化剪枝方法通常采用启发式指标,不加区分地移除所有剪枝层中的一些注意力头,而没有考虑它们在网络架构中的位置。本文提出了一种新的剪枝算法,策略性地剪枝模型较高层的注意力头。由于移除注意力头会改变token表示的幅度,我们引入了一个自适应重缩放参数,用于校准剪枝后的表示尺度,以抵消这种影响。我们在包括LLaMA3.1-8B、Mistral-7B-v0.3、Qwen2-7B和Gemma2-9B在内的各种LLM上进行了全面的实验。我们的评估包括跨27个数据集的生成和判别任务。结果一致表明,我们的方法优于现有的结构化剪枝方法。这种改进在生成任务中尤为显著,我们的方法明显优于现有的基线。
🔬 方法详解
问题定义:现有的大型语言模型剪枝方法,特别是结构化剪枝,通常采用一种启发式的度量标准,在所有层中不加区分地移除一些注意力头。这种方法没有考虑到不同层中注意力头的重要性差异,以及移除注意力头后对token表示的影响。因此,现有的方法可能导致次优的剪枝结果,尤其是在生成任务中。
核心思路:该论文的核心思路是策略性地剪枝模型较高层的注意力头。作者认为,高层注意力头对模型的性能影响更大,因此更有必要进行选择性剪枝。此外,移除注意力头会改变token表示的幅度,因此需要引入一种机制来校准剪枝后的表示尺度,以抵消这种影响。通过这种方式,可以在保证模型性能的同时,实现更高的压缩率。
技术框架:该论文提出的剪枝算法主要包含两个步骤:首先,选择要剪枝的层,作者聚焦于较高层。其次,确定要剪枝的注意力头。具体如何选择注意力头,论文中未明确说明,属于未知细节。在剪枝之后,引入一个自适应重缩放参数来校准表示尺度。这个重缩放参数是针对每个token表示进行调整的,以确保剪枝后的表示与原始表示的幅度尽可能接近。
关键创新:该论文的关键创新在于两个方面:一是策略性地剪枝高层注意力头,而不是像现有方法那样进行无差别剪枝;二是引入自适应重缩放参数来校准剪枝后的表示尺度。这两个创新点共同作用,使得该方法能够在保证模型性能的同时,实现更高的压缩率。
关键设计:关于如何选择高层注意力头进行剪枝,论文中没有给出明确的算法或策略,属于未知细节。自适应重缩放参数的具体计算方式也未详细描述,属于未知细节。损失函数方面,论文没有提及专门设计的损失函数,可能直接使用了预训练模型的原始损失函数。网络结构方面,该方法适用于Transformer架构的LLM,没有对网络结构进行修改。
🖼️ 关键图片


📊 实验亮点
该论文在LLaMA3.1-8B、Mistral-7B-v0.3、Qwen2-7B和Gemma2-9B等多个LLM上进行了实验,并在27个数据集上进行了评估。实验结果表明,该方法在生成和判别任务中均优于现有的结构化剪枝方法。尤其是在生成任务中,该方法的提升尤为显著,具体提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要压缩大型语言模型的场景,例如移动设备上的自然语言处理、边缘计算等。通过剪枝,可以显著降低模型的推理延迟和存储空间,从而使得LLM能够在资源受限的环境中部署和应用。此外,该方法还可以用于模型蒸馏,将大型模型压缩成小型模型,以提高模型的效率。
📄 摘要(原文)
Pruning is a highly effective approach for compressing large language models (LLMs), significantly reducing inference latency. However, conventional training-free structured pruning methods often employ a heuristic metric that indiscriminately removes some attention heads across all pruning layers, without considering their positions within the network architecture. In this work, we propose a novel pruning algorithm that strategically prunes attention heads in the model's higher layers. Since the removal of attention heads can alter the magnitude of token representations, we introduce an adaptive rescaling parameter that calibrates the representation scale post-pruning to counteract this effect. We conduct comprehensive experiments on a wide range of LLMs, including LLaMA3.1-8B, Mistral-7B-v0.3, Qwen2-7B, and Gemma2-9B. Our evaluation includes both generation and discriminative tasks across 27 datasets. The results consistently demonstrate that our method outperforms existing structured pruning methods. This improvement is particularly notable in generation tasks, where our approach significantly outperforms existing baselines.