La RoSA: Enhancing LLM Efficiency via Layerwise Rotated Sparse Activation
作者: Kai Liu, Bowen Xu, Shaoyu Wu, Xin Chen, Hao Zhou, Yongliang Tao, Lulu Hu
分类: cs.CL
发布日期: 2025-07-02 (更新: 2026-01-04)
备注: ICML 2025 Acceptance
💡 一句话要点
La RoSA:通过层级旋转稀疏激活提升大语言模型效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 激活稀疏化 推理加速 正交旋转 Top-K选择
📋 核心要点
- 现有激活稀疏化方法通常需要耗时训练或依赖经验性剪枝,导致部署困难和推理速度不稳定。
- LaRoSA通过层级正交旋转激活,并结合Top-K选择,无需额外训练即可实现稳定的模型稀疏性。
- 实验表明,LaRoSA在多种LLM上实现了显著的推理加速,同时保持了较小的性能损失,优于现有稀疏化方法。
📝 摘要(中文)
激活稀疏性可以减少大语言模型(LLM)推理前向传播过程中的计算开销和内存传输。现有方法面临局限性,要么需要耗时的恢复训练,阻碍了实际应用,要么依赖于基于经验的幅度剪枝,导致稀疏性波动和不稳定的推理加速。本文提出LaRoSA(Layerwise Rotated Sparse Activation),一种新颖的激活稀疏化方法,旨在提高LLM效率,无需额外的训练或基于幅度的剪枝。我们利用层级正交旋转将输入激活转换为更适合稀疏化的旋转形式。通过在旋转激活中采用Top-K选择方法,我们实现了模型层面上的一致稀疏性和可靠的实际时间加速。LaRoSA在各种大小和类型的LLM中都有效,表现出最小的性能下降和强大的推理加速。具体而言,对于LLaMA2-7B在40%稀疏度下,LaRoSA仅实现了0.17的困惑度差距,并实现了1.30倍的实际时间加速,并将零样本任务中的准确率差距与密集模型相比降低至0.54%,同时超过TEAL 1.77%,超过CATS 17.14%。
🔬 方法详解
问题定义:现有大语言模型的激活稀疏化方法存在两个主要问题。一是需要额外的恢复训练来弥补稀疏化带来的性能损失,这增加了部署成本和时间。二是依赖于基于幅度的剪枝,这种方法容易导致稀疏性的波动,进而影响推理速度的稳定性。因此,需要一种无需额外训练且能保证稳定稀疏性的激活稀疏化方法。
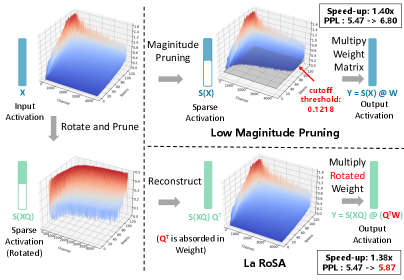
核心思路:LaRoSA的核心思路是通过层级正交旋转,将原始激活转换为更适合稀疏化的表示形式。这种旋转旨在将重要的激活信息集中到少数几个维度上,使得Top-K选择能够更有效地保留关键信息,从而在不损失过多性能的前提下实现高效的稀疏化。
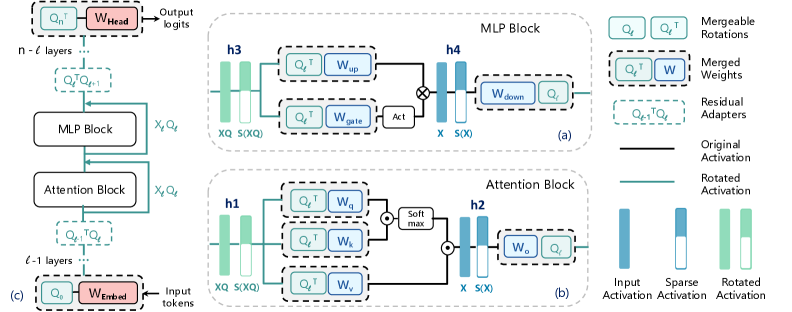
技术框架:LaRoSA方法主要包含两个阶段:旋转阶段和稀疏化阶段。在旋转阶段,对每一层的激活应用一个正交旋转矩阵,将激活向量转换到新的空间。在稀疏化阶段,对旋转后的激活向量进行Top-K选择,保留幅度最大的K个激活值,其余激活值置零。整个过程无需额外的训练,可以直接应用于预训练好的大语言模型。
关键创新:LaRoSA的关键创新在于利用层级正交旋转来改善激活的稀疏性。与传统的幅度剪枝方法不同,LaRoSA通过旋转操作改变了激活的分布,使得Top-K选择能够更有效地保留重要的信息。这种方法避免了幅度剪枝带来的稀疏性波动问题,并减少了对额外训练的需求。
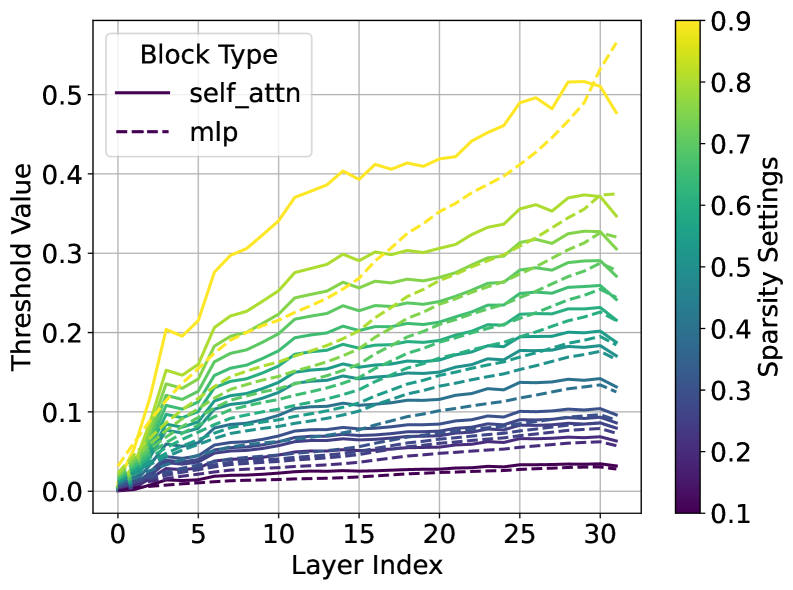
关键设计:LaRoSA的关键设计包括正交旋转矩阵的选择和Top-K选择的比例。正交旋转矩阵可以通过随机初始化或学习得到。Top-K选择的比例决定了模型的稀疏程度,需要在性能和效率之间进行权衡。论文中实验表明,在40%的稀疏度下,LaRoSA能够取得较好的性能和效率平衡。
🖼️ 关键图片
📊 实验亮点
LaRoSA在LLaMA2-7B模型上实现了显著的性能提升。在40%的稀疏度下,LaRoSA仅造成0.17的困惑度损失,同时实现了1.30倍的实际推理加速。在零样本任务中,LaRoSA将准确率差距与密集模型相比降低至0.54%,并且优于TEAL 1.77%,优于CATS 17.14%,证明了其在保持性能的同时实现高效加速的能力。
🎯 应用场景
LaRoSA可广泛应用于大语言模型的推理加速,尤其是在资源受限的场景下,如移动设备或边缘计算平台。通过降低计算开销和内存需求,LaRoSA能够使LLM在这些平台上更高效地运行,从而推动LLM在自然语言处理、智能助手、机器翻译等领域的应用。
📄 摘要(原文)
Activation sparsity can reduce the computational overhead and memory transfers during the forward pass of Large Language Model (LLM) inference. Existing methods face limitations, either demanding time-consuming recovery training that hinders real-world adoption, or relying on empirical magnitude-based pruning, which causes fluctuating sparsity and unstable inference speed-up. This paper introduces LaRoSA (Layerwise Rotated Sparse Activation), a novel method for activation sparsification designed to improve LLM efficiency without requiring additional training or magnitude-based pruning. We leverage layerwise orthogonal rotations to transform input activations into rotated forms that are more suitable for sparsification. By employing a Top-K selection approach within the rotated activations, we achieve consistent model-level sparsity and reliable wall-clock time speed-up. LaRoSA is effective across various sizes and types of LLMs, demonstrating minimal performance degradation and robust inference acceleration. Specifically, for LLaMA2-7B at 40% sparsity, LaRoSA achieves a mere 0.17 perplexity gap with a consistent 1.30x wall-clock time speed-up, and reduces the accuracy gap in zero-shot tasks compared to the dense model to just 0.54%, while surpassing TEAL by 1.77% and CATS by 17.14%.