A Comparative Study of Competency Question Elicitation Methods from Ontology Requirements
作者: Reham Alharbi, Valentina Tamma, Terry R. Payne, Jacopo de Berardinis
分类: cs.CL
发布日期: 2025-07-01
💡 一句话要点
对比本体需求中能力问题获取方法,揭示LLM生成CQ的优劣势。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 能力问题 本体工程 大型语言模型 知识工程 实证研究
📋 核心要点
- 现有能力问题(CQ)的生成方法缺乏系统性的比较和评估,难以指导实际应用。
- 该研究对比了人工、模式实例化和LLM三种CQ生成方法,分析其在不同维度上的优劣。
- 实验表明,LLM可以初步生成CQ,但需根据具体模型进行调整,并进行后续优化。
📝 摘要(中文)
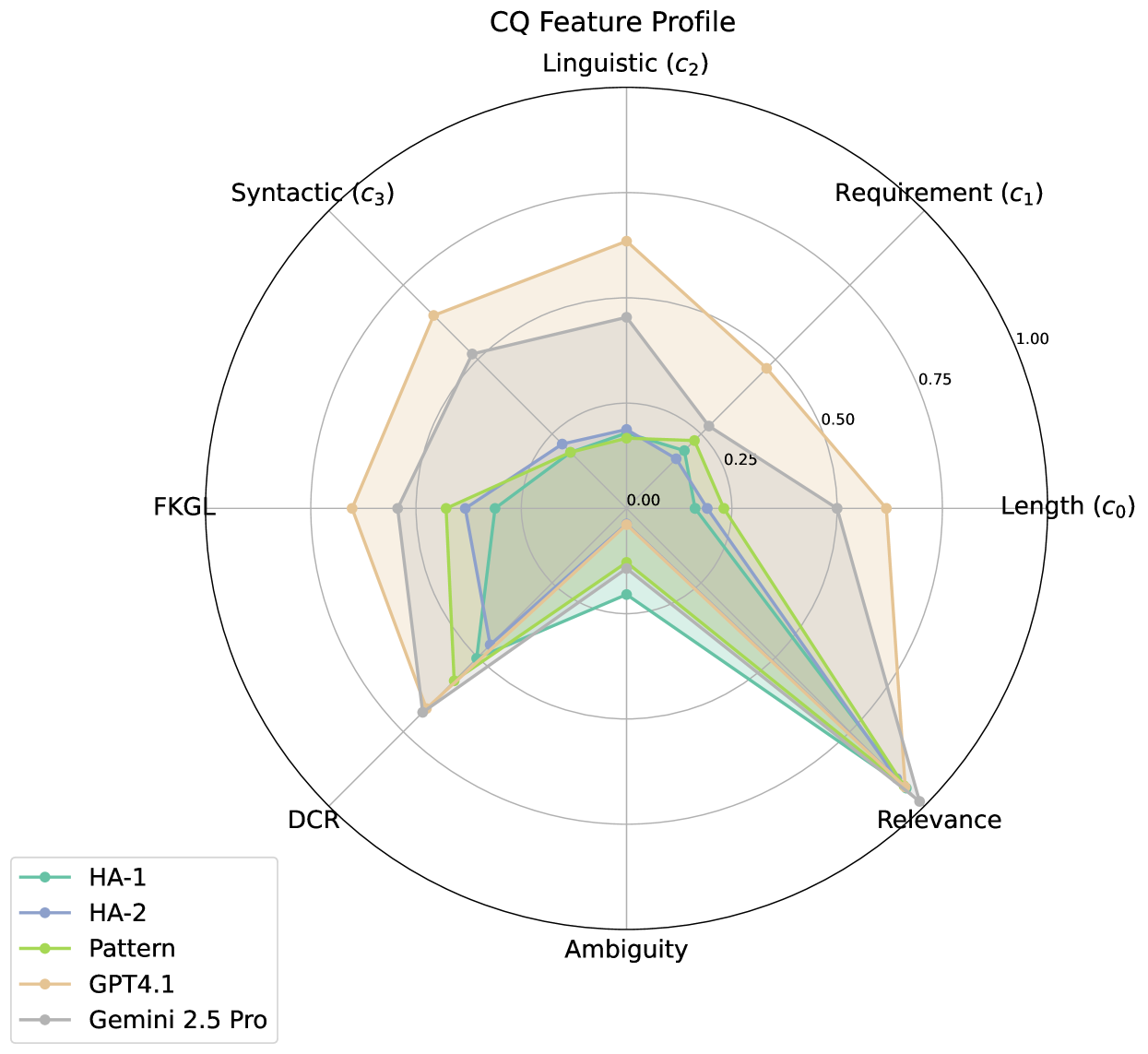
能力问题(CQs)在知识工程中至关重要,它指导着本体的设计、验证和测试。文献中提出了许多不同的制定方法,从完全手动到大型语言模型(LLM)驱动的方法。然而,对这些方法的输出进行表征和系统比较的尝试却很少。本文对三种不同的CQ制定方法进行了实证比较评估:本体工程师的手动制定、CQ模式的实例化以及使用最先进的LLM生成。我们使用每种方法从文化遗产的一组需求中生成CQ,并从不同维度评估它们:可接受程度、模糊性、相关性、可读性和复杂性。我们的贡献有两方面:(i)第一个使用不同方法从相同来源生成的CQ的多注释者数据集;(ii)对每种方法产生的CQ特征进行系统比较。我们的研究表明,不同的CQ生成方法具有不同的特征,LLM可以作为最初获取CQ的一种方式,但这些方法对用于生成CQ的模型很敏感,并且通常需要进一步的细化步骤才能用于建模需求。
🔬 方法详解
问题定义:论文旨在解决本体工程中能力问题(CQ)生成方法选择的问题。现有方法,如人工编写,耗时且依赖专家知识;而新兴的LLM方法,其生成CQ的质量和适用性尚缺乏系统评估,难以判断其是否能有效满足本体需求。因此,需要一种方法来比较和评估不同CQ生成方法的优劣,为本体工程师提供选择依据。
核心思路:论文的核心思路是通过实证研究,对比分析三种不同的CQ生成方法:人工编写、CQ模式实例化和LLM生成。通过多维度(可接受性、模糊性、相关性、可读性和复杂性)的评估,揭示不同方法的特点和适用场景,从而为本体工程师选择合适的CQ生成方法提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 从文化遗产领域的需求文档中提取本体需求;2) 使用三种不同的方法(人工、模式、LLM)生成CQ;3) 招募多名注释者对生成的CQ进行多维度评估;4) 对评估结果进行统计分析和比较,得出不同方法的优劣势结论。
关键创新:该研究的关键创新在于:1) 构建了一个多注释者数据集,包含使用不同方法从相同来源生成的CQ,为后续研究提供了benchmark;2) 对比分析了三种不同的CQ生成方法,并从多个维度评估了它们的特点,为本体工程师选择合适的CQ生成方法提供了依据。
关键设计:在LLM方法中,论文使用了state-of-the-art的LLM模型(具体模型未知)进行CQ生成。为了保证评估的客观性,论文招募了多名注释者,并设计了详细的评估指标,包括可接受性、模糊性、相关性、可读性和复杂性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于LLM模型本身的固有属性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的CQ生成方法在不同维度上表现出不同的特点。LLM可以作为初步生成CQ的一种方式,但其生成结果对模型敏感,且通常需要进一步的细化。人工编写的CQ质量较高,但耗时且依赖专家知识。模式实例化的方法则介于两者之间,具有一定的效率和质量。
🎯 应用场景
该研究成果可应用于知识工程、本体构建、语义搜索等领域。通过选择合适的CQ生成方法,可以更高效地构建高质量的本体,提升知识表示和推理能力。未来,该研究可以扩展到其他领域,并探索更有效的LLM驱动的CQ生成方法。
📄 摘要(原文)
Competency Questions (CQs) are pivotal in knowledge engineering, guiding the design, validation, and testing of ontologies. A number of diverse formulation approaches have been proposed in the literature, ranging from completely manual to Large Language Model (LLM) driven ones. However, attempts to characterise the outputs of these approaches and their systematic comparison are scarce. This paper presents an empirical comparative evaluation of three distinct CQ formulation approaches: manual formulation by ontology engineers, instantiation of CQ patterns, and generation using state of the art LLMs. We generate CQs using each approach from a set of requirements for cultural heritage, and assess them across different dimensions: degree of acceptability, ambiguity, relevance, readability and complexity. Our contribution is twofold: (i) the first multi-annotator dataset of CQs generated from the same source using different methods; and (ii) a systematic comparison of the characteristics of the CQs resulting from each approach. Our study shows that different CQ generation approaches have different characteristics and that LLMs can be used as a way to initially elicit CQs, however these are sensitive to the model used to generate CQs and they generally require a further refinement step before they can be used to model requirements.