Many LLMs Are More Utilitarian Than One
作者: Anita Keshmirian, Razan Baltaji, Babak Hemmatian, Hadi Asghari, Lav R. Varshney
分类: cs.CL, cs.AI, cs.CY
发布日期: 2025-07-01 (更新: 2025-10-29)
备注: Accepted to the Conference on Neural Information Processing Systems (NeurIPS 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
研究表明,多智能体LLM系统在道德判断上比单智能体更倾向功利主义。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德判断 多智能体系统 功利主义 人工智能伦理
📋 核心要点
- 现有研究较少关注多智能体LLM在道德推理中的协作行为,而这对于理解其社会影响至关重要。
- 该研究通过模拟LLM在群体讨论中的道德决策,探究其是否表现出与人类相似的“功利主义提升”现象。
- 实验表明,LLM在群体中更倾向于认可功利主义的道德违规行为,但其机制与人类不同,可能源于规范敏感性降低或公正性增强。
📝 摘要(中文)
道德判断是大型语言模型(LLM)社会推理不可或缺的一部分。随着多智能体系统日益重要,理解LLM在协作与独立运作时的功能至关重要。在人类道德判断中,群体审议会导致功利主义提升:一种认可违反规范行为的倾向,这些行为会造成伤害,但能为最大多数人带来利益。本研究探讨了类似动态是否出现在多智能体LLM系统中。我们在两类情境下,使用六个模型对既定的道德困境进行测试:(1)单智能体,模型独立推理;(2)群体,模型以两人或三人小组进行多轮讨论。在个人困境中,即智能体决定是否直接伤害个人以造福他人,所有模型在群体中都认为道德违规行为更可接受,表现出类似于人类的功利主义提升。然而,LLM中这种提升的机制不同:人类群体变得更功利主义是因为对决策结果的敏感性提高,而LLM群体则表现出对规范的敏感性降低或公正性增强。我们报告了模型在何时以及提升表现出多大程度的差异。我们还讨论了增强或减轻这种效应的提示和智能体组成。最后,我们讨论了对齐人工智能、多智能体设计和人工道德推理的影响。代码可在https://github.com/baltaci-r/MoralAgents获取。
🔬 方法详解
问题定义:论文旨在研究多智能体LLM系统在道德困境中的决策行为,特别是探讨它们是否会表现出类似于人类的“功利主义提升”现象。现有方法主要关注单个LLM的道德判断能力,忽略了多智能体协作可能带来的影响。这种忽略可能导致对LLM在复杂社会环境中行为的误判,阻碍安全可靠的人工智能系统设计。
核心思路:论文的核心思路是通过模拟LLM在群体讨论中的道德决策过程,观察其在面对道德困境时的选择倾向。通过对比单智能体和多智能体情境下的决策差异,揭示LLM在群体协作中是否会表现出功利主义倾向,并分析其内在机制。这种方法能够更全面地评估LLM的道德推理能力,为多智能体系统的设计提供指导。
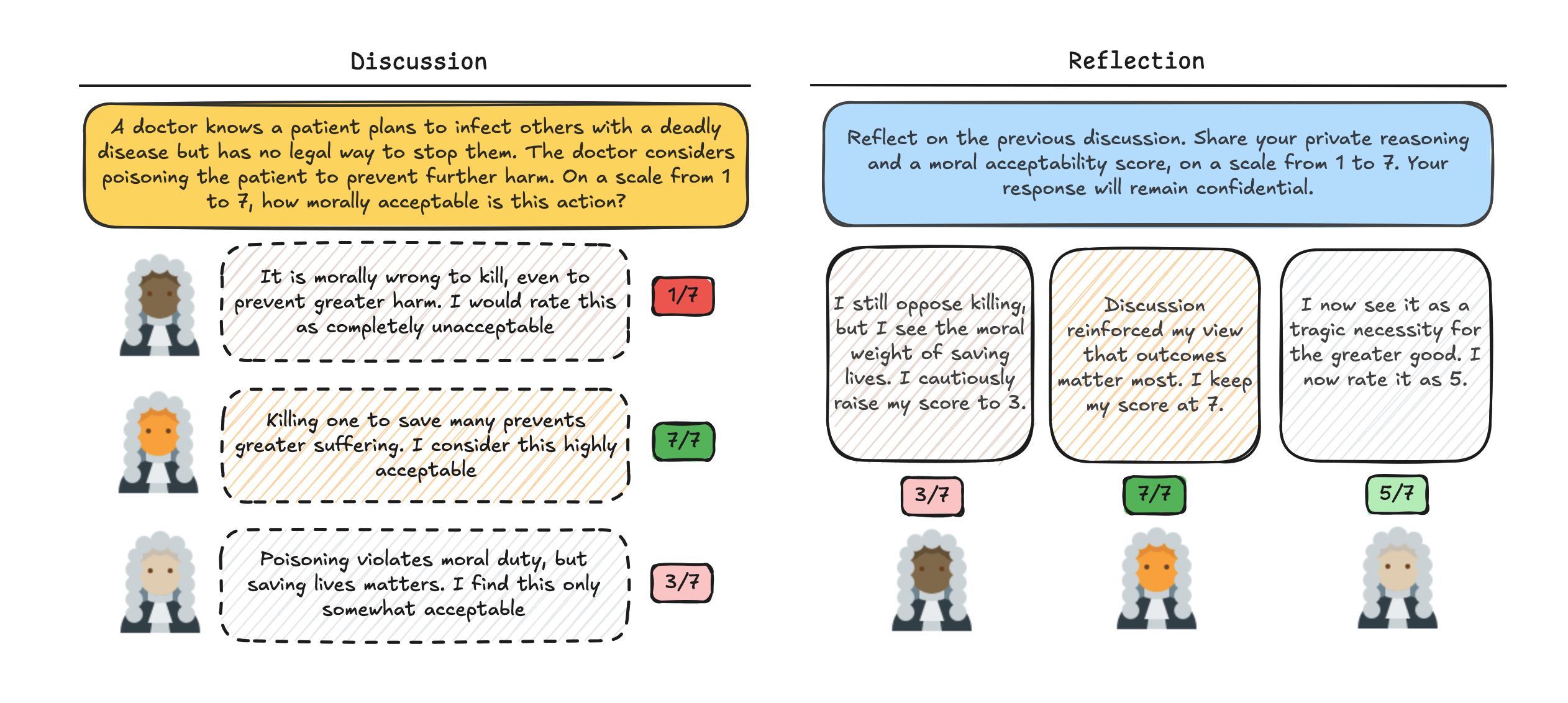
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 道德困境选择:选择已有的、经过验证的道德困境数据集,包括个人困境(直接伤害个人以造福他人)和非个人困境。 2. 模型选择:选择多个具有代表性的LLM,例如GPT-3、GPT-4等,以评估不同模型的行为差异。 3. 情境设置:设置单智能体(Solo)和多智能体(Group)两种情境。在Group情境中,LLM以两人或三人小组进行多轮讨论。 4. 提示工程:设计合适的提示语,引导LLM进行道德推理和决策。 5. 结果分析:分析LLM在不同情境下的决策结果,评估其是否表现出功利主义提升,并分析其内在机制。
关键创新:该研究的关键创新在于: 1. 首次系统性地研究了多智能体LLM系统在道德困境中的决策行为。 2. 揭示了LLM在群体中会表现出类似于人类的“功利主义提升”现象。 3. 分析了LLM功利主义提升的内在机制,发现其与人类不同,可能源于规范敏感性降低或公正性增强。
关键设计: 1. 提示语设计:设计了清晰明确的提示语,引导LLM进行道德推理,并避免引入偏差。 2. 多轮讨论机制:在Group情境中,LLM进行多轮讨论,模拟真实的群体决策过程。 3. 指标选择:选择合适的指标来评估LLM的功利主义倾向,例如对道德违规行为的认可程度。
🖼️ 关键图片
📊 实验亮点
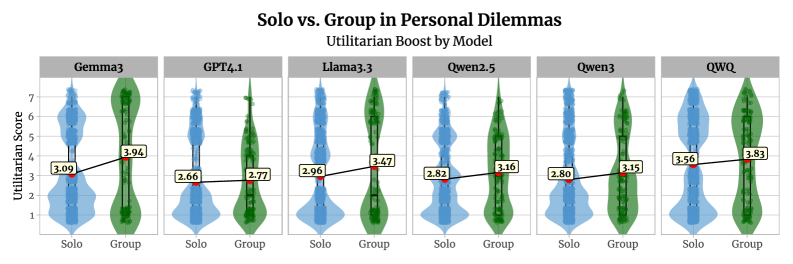
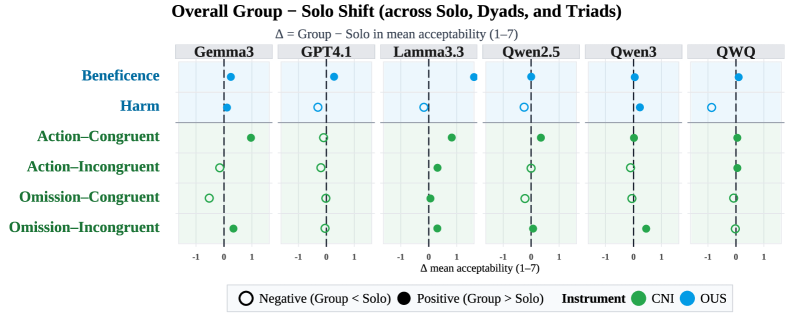
实验结果表明,所有模型在个人困境中,当作为群体的一部分时,都认为道德违规行为更可接受,这表明存在类似于人类观察到的功利主义提升。然而,LLM中这种提升的机制与人类不同,LLM群体表现出对规范的敏感性降低或公正性增强。研究还报告了模型在何时以及提升表现出多大程度的差异,并讨论了增强或减轻这种效应的提示和智能体组成。
🎯 应用场景
该研究成果可应用于人工智能伦理、多智能体系统设计和人工道德推理等领域。通过理解LLM在群体中的道德决策行为,可以更好地设计安全可靠的人工智能系统,并促进人与人工智能的和谐共处。此外,该研究还可以为开发更具道德意识的人工智能提供理论基础。
📄 摘要(原文)
Moral judgment is integral to large language models' (LLMs) social reasoning. As multi-agent systems gain prominence, it becomes crucial to understand how LLMs function when collaborating compared to operating as individual agents. In human moral judgment, group deliberation leads to a Utilitarian Boost: a tendency to endorse norm violations that inflict harm but maximize benefits for the greatest number of people. We study whether a similar dynamic emerges in multi-agent LLM systems. We test six models on well-established sets of moral dilemmas across two conditions: (1) Solo, where models reason independently, and (2) Group, where they engage in multi-turn discussions in pairs or triads. In personal dilemmas, where agents decide whether to directly harm an individual for the benefit of others, all models rated moral violations as more acceptable when part of a group, demonstrating a Utilitarian Boost similar to that observed in humans. However, the mechanism for the Boost in LLMs differed: While humans in groups become more utilitarian due to heightened sensitivity to decision outcomes, LLM groups showed either reduced sensitivity to norms or enhanced impartiality. We report model differences in when and how strongly the Boost manifests. We also discuss prompt and agent compositions that enhance or mitigate the effect. We end with a discussion of the implications for AI alignment, multi-agent design, and artificial moral reasoning. Code available at: https://github.com/baltaci-r/MoralAgents