Mixture of Reasonings: Teach Large Language Models to Reason with Adaptive Strategies
作者: Tao Xiong, Xavier Hu, Wenyan Fan, Shengyu Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-01 (更新: 2025-07-03)
💡 一句话要点
提出混合推理(MoR)框架,提升大语言模型在复杂任务中的自适应推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理策略 自适应推理 混合推理 思维链 提示工程 监督微调
📋 核心要点
- 现有大语言模型依赖人工设计的任务特定提示进行复杂推理,缺乏通用性和效率。
- MoR框架将多种推理策略嵌入模型,实现任务自适应推理,无需人工提示工程。
- 实验表明,MoR显著提升模型性能,在多个基准测试中优于现有方法。
📝 摘要(中文)
本文提出了一种名为混合推理(MoR)的训练框架,旨在提升大语言模型(LLMs)的推理能力。现有方法依赖于手动设计的、特定于任务的提示,限制了模型的适应性和效率。MoR通过将多样化的推理策略嵌入到LLM中,实现自主的、任务自适应的推理,无需外部提示工程。MoR包含两个阶段:思维生成阶段,利用GPT-4o等模型创建推理链模板;以及SFT数据集构建阶段,将模板与基准数据集配对,用于监督微调。实验结果表明,MoR显著提高了性能,MoR150在使用CoT提示时达到了0.730的准确率(提升2.2%),相比基线模型提升了13.5%。MoR消除了对特定任务提示的需求,为各种任务的鲁棒推理提供了一种通用的解决方案。
🔬 方法详解
问题定义:现有的大语言模型在解决复杂任务时,通常依赖于诸如Chain-of-Thought (CoT) 和 Tree-of-Thought (ToT) 等高级提示技术。然而,这些方法需要人工设计特定于任务的提示,这限制了模型的泛化能力和效率。针对不同任务,都需要专家知识来设计有效的提示,成本高昂且难以自动化。
核心思路:MoR的核心思路是通过训练让大语言模型自身具备多种推理策略,并能够根据不同的任务自适应地选择合适的策略。通过将不同的推理“思维链”模板嵌入到模型中,使其不再依赖于外部的、人工设计的提示,从而实现更通用、更高效的推理能力。这种方法类似于让模型学习成为一个“推理专家”,能够根据问题的特点选择合适的“思考方式”。
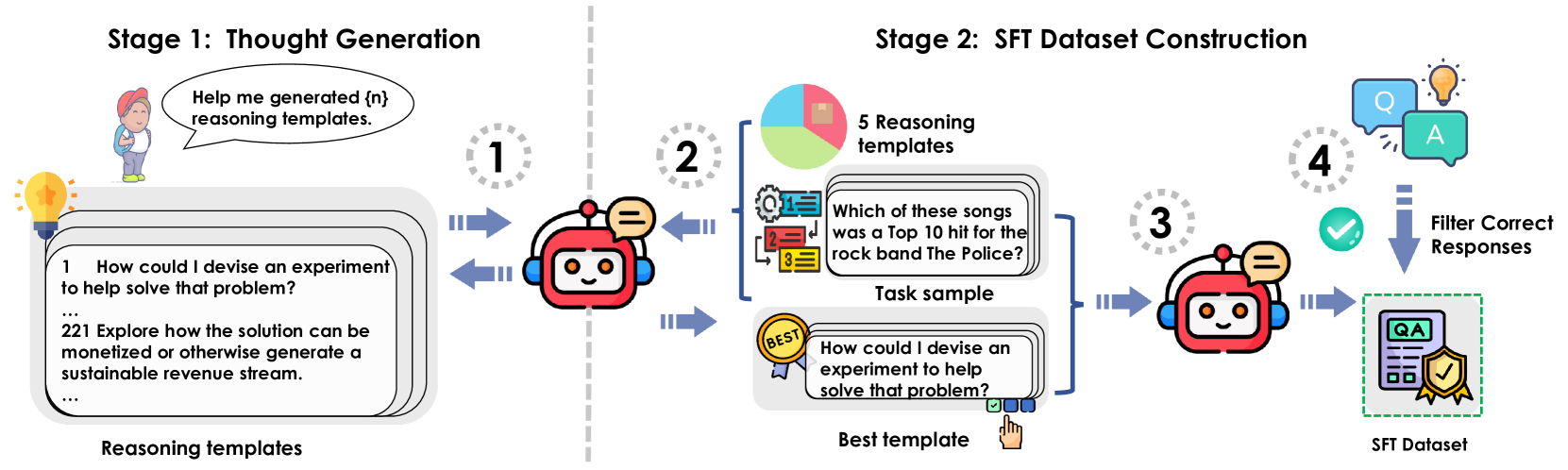
技术框架:MoR框架包含两个主要阶段:1) 思维生成阶段 (Thought Generation):利用强大的语言模型(如GPT-4o)生成多样化的推理链模板。这些模板代表了不同的推理策略和思考路径。2) SFT数据集构建阶段 (SFT Dataset Construction):将生成的推理链模板与现有的基准数据集进行配对,构建一个用于监督微调(SFT)的数据集。然后,使用这个数据集对大语言模型进行微调,使其学习到如何根据任务选择和应用合适的推理策略。
关键创新:MoR的关键创新在于它能够让大语言模型自主学习和选择推理策略,而无需人工干预。与传统的提示工程方法相比,MoR提供了一种更通用、更自动化的解决方案。它通过将推理策略嵌入到模型本身,提高了模型的适应性和鲁棒性。此外,MoR还能够生成多样化的推理链模板,从而丰富了模型的推理能力。
关键设计:在思维生成阶段,需要设计合适的提示语来引导GPT-4o等模型生成高质量的推理链模板。这些提示语应该能够鼓励模型探索不同的推理策略和思考路径。在SFT数据集构建阶段,需要仔细选择基准数据集,并确保生成的推理链模板与数据集中的问题相匹配。在模型微调阶段,可以使用标准的监督学习方法,例如交叉熵损失函数。论文中提到的MoR150可能指的是使用了150个不同的推理链模板进行训练。
🖼️ 关键图片

📊 实验亮点
MoR框架在多个基准测试中取得了显著的性能提升。例如,MoR150在使用CoT提示时达到了0.730的准确率,相比基线模型提升了2.2%。在某些任务上,MoR甚至取得了13.5%的显著提升。这些结果表明,MoR能够有效地提升大语言模型的推理能力,并使其在各种复杂任务中表现出色。
🎯 应用场景
MoR框架具有广泛的应用前景,可用于提升大语言模型在各种复杂任务中的性能,例如数学问题求解、常识推理、代码生成等。该方法能够降低对人工提示工程的依赖,提高模型的通用性和自动化程度,从而加速大语言模型在实际场景中的应用。未来,MoR有望应用于智能客服、自动化报告生成、智能决策支持等领域。
📄 摘要(原文)
Large language models (LLMs) excel in complex tasks through advanced prompting techniques like Chain-of-Thought (CoT) and Tree-of-Thought (ToT), but their reliance on manually crafted, task-specific prompts limits adaptability and efficiency. We introduce Mixture of Reasoning (MoR), a training framework that embeds diverse reasoning strategies into LLMs for autonomous, task-adaptive reasoning without external prompt engineering. MoR has two phases: Thought Generation, creating reasoning chain templates with models like GPT-4o, and SFT Dataset Construction, pairing templates with benchmark datasets for supervised fine-tuning. Our experiments show that MoR significantly enhances performance, with MoR150 achieving 0.730 (2.2% improvement) using CoT prompting and 0.734 (13.5% improvement) compared to baselines. MoR eliminates the need for task-specific prompts, offering a generalizable solution for robust reasoning across diverse tasks.