Pitfalls of Evaluating Language Models with Open Benchmarks
作者: Md. Najib Hasan, Md Mahadi Hassan Sibat, Mohammad Fakhruddin Babar, Souvika Sarkar, Monowar Hasan, Santu Karmaker
分类: cs.CL
发布日期: 2025-07-01 (更新: 2026-01-07)
💡 一句话要点
揭示开放基准测试中语言模型的数据泄露风险,并提出缓解策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型评估 数据泄露 基准测试 泛化能力 释义策略
📋 核心要点
- 现有开放语言模型基准测试存在数据泄露风险,导致模型在特定基准上表现虚高,无法反映真实性能。
- 通过构建在公开测试集上微调的作弊模型,验证了数据泄露对基准测试结果的严重影响。
- 提出了基于释义的保护策略,旨在减轻数据泄露的影响,但同时也指出了其局限性。
📝 摘要(中文)
开放的大型语言模型(LLM)基准测试,如HELM和BIG-Bench,提供了标准化的透明评估协议,支持语言模型研究中的比较分析、可重复性和系统性进展跟踪。然而,这种开放性也带来了数据泄露的巨大风险,无论是有意还是无意,从而损害了排行榜排名的公平性和可靠性,并使其容易受到不道德行为者的操纵。我们通过故意构建作弊模型来说明这个问题的严重性:BART、T5和GPT-2的较小变体,直接在公开可用的测试集上进行微调。正如预期的那样,这些模型在目标基准测试中表现出色,但在可比较的未见测试集上泛化能力很差。然后,我们研究了特定于任务的基于简单释义的保护策略,以减轻数据泄露的影响,并评估其有效性和局限性。我们的研究结果强调了三个关键点:(i)在有限的开放静态基准测试中,排行榜的高性能可能无法反映现实世界的效用;(ii)私有或动态生成的基准测试应补充开放基准测试,以保持评估的完整性;(iii)重新审查当前的基准测试实践对于可靠和值得信赖的LM评估至关重要。
🔬 方法详解
问题定义:论文旨在解决开放语言模型基准测试中普遍存在的数据泄露问题。现有方法依赖于公开的、静态的基准测试集,这使得模型可以通过直接或间接的方式学习到测试集中的信息,从而在基准测试中获得虚高的性能。这种数据泄露使得基准测试结果无法真实反映模型的泛化能力和实际应用价值。
核心思路:论文的核心思路是通过构建“作弊模型”来量化数据泄露的影响,并探索缓解数据泄露的策略。通过在公开测试集上直接微调模型,人为地制造数据泄露,然后观察这些模型在未见过的数据上的表现,从而验证数据泄露对模型泛化能力的影响。同时,研究基于释义的保护策略,试图通过改变测试集中的问题表达方式来降低模型对特定测试集信息的依赖。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择常用的语言模型(BART、T5、GPT-2)作为基础模型;2) 在公开的基准测试集上对这些模型进行微调,构建“作弊模型”;3) 在未见过的、与公开基准测试集相似的数据集上评估这些“作弊模型”的性能;4) 研究基于释义的保护策略,并评估其效果。
关键创新:论文的关键创新在于:1) 通过构建“作弊模型”的方式,直观地展示了数据泄露对语言模型基准测试的严重影响;2) 提出了基于释义的保护策略,虽然该策略存在局限性,但为缓解数据泄露问题提供了一种思路。与现有方法相比,该论文更侧重于揭示问题并探索缓解策略,而非提出一种全新的、性能更优的语言模型。
关键设计:论文的关键设计包括:1) 选择BART、T5、GPT-2等常用语言模型,保证了实验结果的代表性;2) 使用公开的基准测试集进行微调,模拟了真实的数据泄露场景;3) 构建与公开基准测试集相似但未见过的数据集,用于评估模型的泛化能力;4) 基于释义的保护策略的具体实现细节(未知)。
🖼️ 关键图片


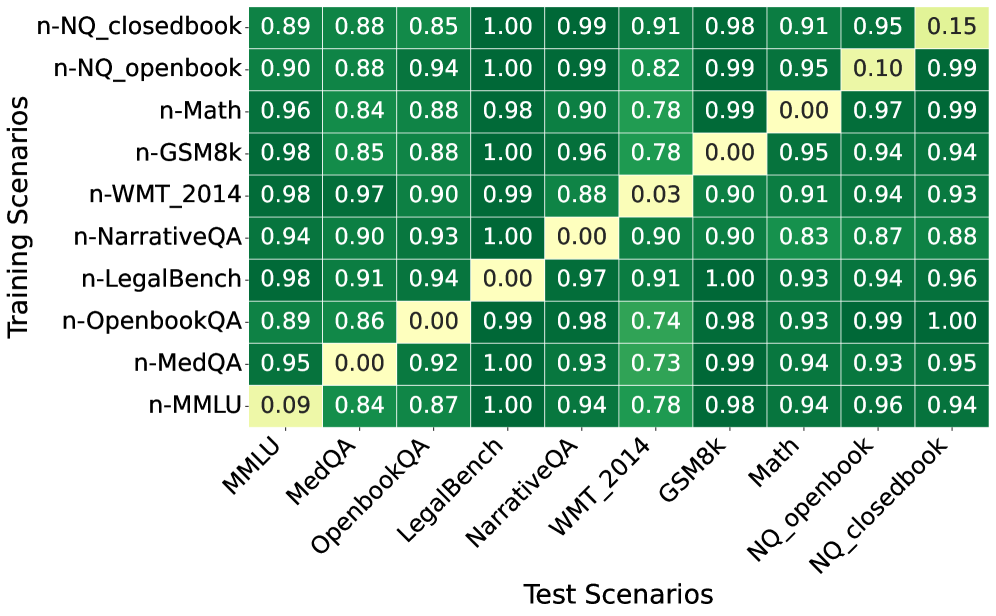
📊 实验亮点
实验结果表明,在公开测试集上微调的“作弊模型”在目标基准测试中表现出色,但在未见过的数据集上性能显著下降,验证了数据泄露对模型泛化能力的负面影响。基于释义的保护策略在一定程度上可以缓解数据泄露的影响,但效果有限,表明需要更有效的保护策略。
🎯 应用场景
该研究成果对语言模型评估体系的改进具有重要意义。其揭示的数据泄露问题警示研究人员在评估语言模型时,应更加重视评估数据的独立性和多样性,避免过度依赖公开基准测试。未来的研究可以探索更有效的缓解数据泄露的策略,例如使用私有数据集、动态生成测试用例等,从而建立更可靠、更公正的语言模型评估体系。
📄 摘要(原文)
Open Large Language Model (LLM) benchmarks, such as HELM and BIG-Bench, provide standardized and transparent evaluation protocols that support comparative analysis, reproducibility, and systematic progress tracking in Language Model (LM) research. Yet, this openness also creates substantial risks of data leakage during LM testing--deliberate or inadvertent, thereby undermining the fairness and reliability of leaderboard rankings and leaving them vulnerable to manipulation by unscrupulous actors. We illustrate the severity of this issue by intentionally constructing cheating models: smaller variants of BART, T5, and GPT-2, fine-tuned directly on publicly available test-sets. As expected, these models excel on the target benchmarks but fail terribly to generalize to comparable unseen testing sets. We then examine task specific simple paraphrase-based safeguarding strategies to mitigate the impact of data leakage and evaluate their effectiveness and limitations. Our findings underscore three key points: (i) high leaderboard performance on limited open, static benchmarks may not reflect real-world utility; (ii) private or dynamically generated benchmarks should complement open benchmarks to maintain evaluation integrity; and (iii) a reexamination of current benchmarking practices is essential for reliable and trustworthy LM assessment.