The Translation Barrier Hypothesis: Multilingual Generation with Large Language Models Suffers from Implicit Translation Failure
作者: Niyati Bafna, Tianjian Li, Kenton Murray, David R. Mortensen, David Yarowsky, Hale Sirin, Daniel Khashabi
分类: cs.CL
发布日期: 2025-06-28 (更新: 2025-10-20)
备注: 28 pages, incl. appendix
💡 一句话要点
提出翻译障碍假说以解决多语言生成质量低下问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言生成 翻译障碍 大型语言模型 低资源语言 任务解决 隐含翻译
📋 核心要点
- 现有大型语言模型在中低资源语言的多语言生成中质量较低,原因尚未得到充分理解。
- 论文提出翻译障碍假说,认为任务解决成功后翻译阶段的失败是导致低质量输出的关键因素。
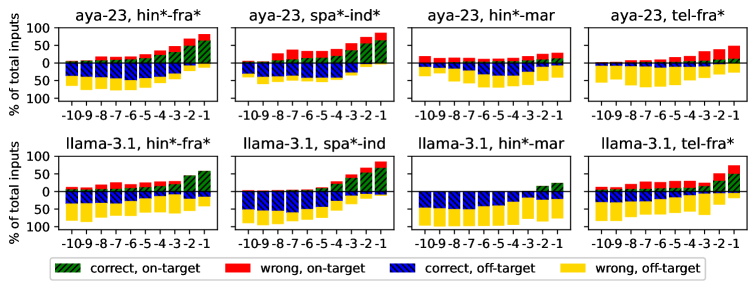
- 通过对108对语言的实验,发现翻译障碍在大多数语言对中占据了主要错误来源,尤其在低资源语言中表现明显。
📝 摘要(中文)
多语言生成在大型语言模型(LLMs)中对于中低资源语言的质量往往较差,但其原因尚不明确。本文首先展示了隐含的任务解决与翻译管道,模型在目标语言无关的方式下解决任务,然后将答案概念翻译为目标语言。我们假设翻译阶段的失败是导致最终输出质量低下的重要原因,并将其形式化为翻译障碍假说。通过对108对语言的词汇翻译任务进行量化分析,我们发现翻译障碍在大多数语言对中解释了显著的错误部分,尤其在低资源目标语言中更为严重。我们的结果突显了端到端多语言生成中的重要瓶颈,为未来提升LLMs的多语言性提供了参考。
🔬 方法详解
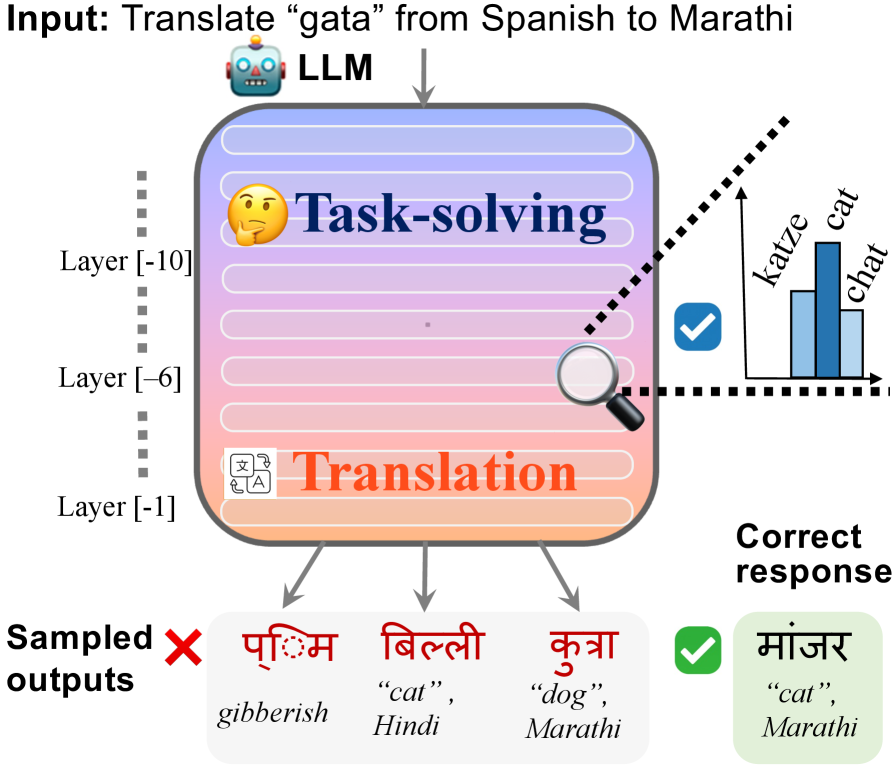
问题定义:本文旨在解决大型语言模型在多语言生成中对于中低资源语言输出质量低下的问题。现有方法未能有效识别任务解决与翻译之间的隐含关系,导致最终生成结果不理想。
核心思路:论文提出翻译障碍假说,认为在任务成功解决后,翻译阶段的失败是导致低质量输出的主要原因。通过量化分析,明确了翻译和任务解决两个阶段对最终结果的影响。
技术框架:整体架构包括两个主要阶段:首先是任务解决阶段,模型以目标语言无关的方式完成任务;其次是翻译阶段,将解决方案翻译为目标语言。通过对这两个阶段的分析,识别出翻译障碍的影响。
关键创新:最重要的技术创新在于将任务解决与翻译过程明确分开,并提出翻译障碍假说,揭示了其对多语言生成质量的影响。这一思路与现有方法的本质区别在于强调了翻译阶段的重要性。
关键设计:在实验中,使用了108对语言的词汇翻译任务,设计了相应的评估指标,以量化翻译障碍对错误的贡献。具体的参数设置和损失函数设计未在摘要中详细说明,需参考完整论文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,翻译障碍在大多数语言对中占据了显著的错误来源,尤其在低资源语言中表现得尤为明显。具体数据显示,翻译阶段的失败解释了大部分的生成错误,为提升多语言生成质量提供了重要的实证依据。
🎯 应用场景
该研究的潜在应用领域包括多语言翻译系统、跨语言信息检索和多语言对话系统等。通过识别和解决翻译障碍,未来的多语言生成模型可以在低资源语言上实现更高的生成质量,从而提升用户体验和应用效果。
📄 摘要(原文)
Multilingual generation with large language models (LLMs) is often of poor quality for mid- to low-resource languages, but the causes for this are not well-understood. We first demonstrate the existence of an implicit task-solving-->translation pipeline for generation, whereby the model first solves the required task in a largely target-language-agnostic manner, and subsequently translates answer concepts into the intended target language. We hypothesize that the failure of the translation stage, despite task-solving success, is an important culprit for the observed low quality of final outputs, and formalize this as the translation barrier hypothesis. We quantify the extent to which either stage in the pipeline is responsible for final failure for a word translation task across 108 language pairs, and find that the translation barrier explains a dominant portion of error for a majority of language pairs, and is especially severe for low-resource target languages. Our results highlight an important bottleneck for end-to-end multilingual generation, relevant for future work seeking to improve multilinguality in LLMs.