TPTT: Transforming Pretrained Transformers into Titans
作者: Fabien Furfaro
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-06-21 (更新: 2025-08-31)
备注: 14 pages, 2 figure
🔗 代码/项目: GITHUB
💡 一句话要点
TPTT框架:通过线性化注意力与内部记忆门控增强预训练Transformer模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 线性化注意力 记忆门控 参数高效微调 长文本处理 预训练模型 Transformer 大型语言模型
📋 核心要点
- 大型语言模型在长文本处理中面临计算和内存瓶颈,尤其是在自注意力机制上。
- TPTT框架通过引入线性化注意力(LiZA)和记忆门控(MaG),在不完全重新训练的情况下增强预训练模型。
- 实验表明,TPTT在约10亿参数的模型上,如Llama-1B,在MMLU基准测试中实现了效率和准确性的潜在提升。
📝 摘要(中文)
基于Transformer的大型语言模型(LLMs)在许多自然语言处理任务中表现出色。然而,其二次方的计算和内存需求,尤其是在自注意力层中,对长上下文的高效推理以及在资源受限环境中的部署提出了挑战。我们提出了TPTT(Transforming Pretrained Transformers into Titans)框架,旨在通过线性化注意力(LiZA)和通过Memory as Gate(MaG)实现的内部记忆门控来增强预训练的Transformer模型,而无需完全重新训练。TPTT支持参数高效的微调(LoRA),并与Hugging Face Transformers等标准工具包集成。我们评估了TPTT在包括Llama-1B、OlMoE-1B-7B、Qwen2.5-1.5B、Gemma3-270m、OpenELM-1.3B和Mistral-7B在内的多个预训练模型上的效果,以评估其在不同规模架构中的适用性。在约10亿参数的模型上进行的实验,主要在MMLU基准上评估,表明与基线模型相比,效率和准确性都有潜在的提高。例如,Titans-Llama-1B在一次性评估中表现出高达20%的Exact Match分数相对增长。另一个发现是,可以使用DeltaProduct机制将二次注意力模型转换为纯线性注意力模型。所有训练运行均使用适度的计算资源进行。这些初步发现表明,TPTT可能有助于以有限的开销调整预训练的LLM以适应长上下文任务。需要对更大的模型和更广泛的基准进行进一步研究,以评估该框架的通用性和鲁棒性。
🔬 方法详解
问题定义:大型Transformer模型在处理长序列时,自注意力机制的计算复杂度呈二次方增长,导致计算和内存开销巨大,限制了其在资源受限环境中的应用。现有方法通常需要大量的计算资源进行重新训练,成本高昂。
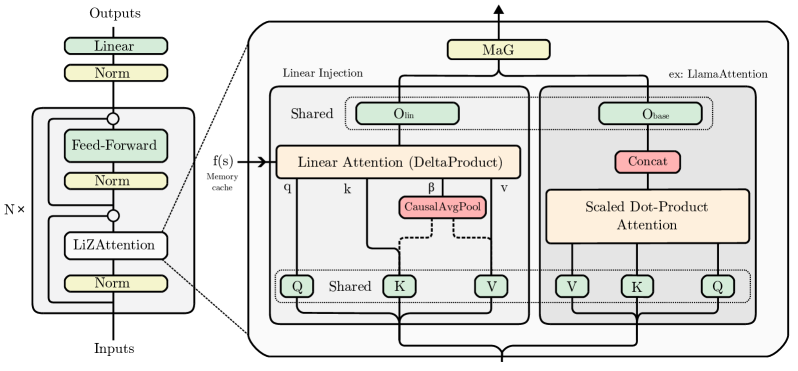
核心思路:TPTT框架的核心在于利用线性化注意力(LiZA)降低计算复杂度,并引入记忆门控(MaG)来增强模型对长序列信息的处理能力。通过参数高效的微调(LoRA),在不完全重新训练的情况下,将预训练的Transformer模型转化为更高效的“Titans”模型。
技术框架:TPTT框架主要包含两个核心模块:LiZA和MaG。LiZA通过线性化注意力机制,将计算复杂度从O(n^2)降低到O(n),从而显著减少计算和内存需求。MaG则通过引入内部记忆单元,并使用门控机制控制信息的流入和流出,增强模型对长序列信息的记忆和利用能力。TPTT框架可以与Hugging Face Transformers等标准工具包集成,方便使用和扩展。
关键创新:TPTT的关键创新在于将线性化注意力和记忆门控机制结合起来,并采用参数高效的微调方法,实现了在不完全重新训练的情况下,显著提升预训练Transformer模型在长序列处理任务中的效率和性能。此外,DeltaProduct机制的引入使得将二次注意力模型转换为纯线性注意力模型成为可能。
关键设计:TPTT框架的关键设计包括:LiZA的具体实现方式(例如,使用核函数近似注意力权重),MaG中记忆单元的结构和门控机制的设计,以及LoRA微调策略的参数设置。此外,DeltaProduct机制的具体实现也需要仔细设计,以保证转换后的模型性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TPTT框架在多个预训练模型上取得了显著的性能提升。例如,Titans-Llama-1B在MMLU基准测试中,一次性评估的Exact Match分数相对增长高达20%。此外,研究还发现可以使用DeltaProduct机制将二次注意力模型转换为纯线性注意力模型。这些结果表明,TPTT框架具有很大的潜力,可以帮助开发更高效、更强大的大型语言模型。
🎯 应用场景
TPTT框架可应用于各种需要处理长文本序列的自然语言处理任务,例如长文档摘要、机器翻译、问答系统等。该框架尤其适用于资源受限的环境,例如移动设备或边缘计算平台,可以帮助部署更高效、更轻量级的大型语言模型。此外,TPTT还可以用于加速模型训练和推理,降低计算成本。
📄 摘要(原文)
Transformer-based large language models (LLMs) have achieved strong performance across many natural language processing tasks. Nonetheless, their quadratic computational and memory requirements, particularly in self-attention layers, pose challenges for efficient inference on long contexts and for deployment in resource-limited environments. We present TPTT (Transforming Pretrained Transformers into Titans), a framework designed to augment pretrained Transformers with linearized attention (LiZA) and internal memory gating via Memory as Gate (MaG), applied without full retraining. TPTT supports parameter-efficient fine-tuning (LoRA) and integrates with standard toolkits such as Hugging Face Transformers. We evaluated TPTT on several pretrained models, including Llama-1B, OlMoE-1B-7B, Qwen2.5-1.5B, Gemma3-270m, OpenELM-1.3B, and Mistral-7B, in order to assess applicability across architectures of different scales. Experiments on models with approximately 1 billion parameters, evaluated primarily on the MMLU benchmark, suggest potential improvements in both efficiency and accuracy compared to baseline models. For example, Titans-Llama-1B exhibited up to a 20\% relative increase in Exact Match scores in one-shot evaluation. An additional finding is that it is possible to convert a quadratic-attention model into a purely linear-attention model using the DeltaProduct mechanism. All training runs were carried out with modest computational resources. These preliminary findings indicate that TPTT may help adapt pretrained LLMs for long-context tasks with limited overhead. Further studies on larger models and a broader set of benchmarks will be necessary to evaluate the generality and robustness of the framework. Code is available at https://github.com/fabienfrfr/tptt . Python package at https://pypi.org/project/tptt/ .