DuaShepherd: Integrating Stepwise Correctness and Potential Rewards for Mathematical Reasoning
作者: Yuanhao Wu, Juntong Song, Hanning Zhang, Tong Zhang, Cheng Niu
分类: cs.CL
发布日期: 2025-06-21
💡 一句话要点
DuaShepherd:融合逐步正确性和潜在奖励,提升LLM的数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 奖励模型 大型语言模型 强化学习 步骤正确性 潜在奖励 多任务学习 复合概率
📋 核心要点
- 现有LLM在数学推理中缺乏对中间步骤的有效监督,难以识别和纠正推理过程中的错误。
- DuaShepherd融合了基于步骤正确性的奖励和基于最终答案潜在性的奖励,提供更全面的反馈信号。
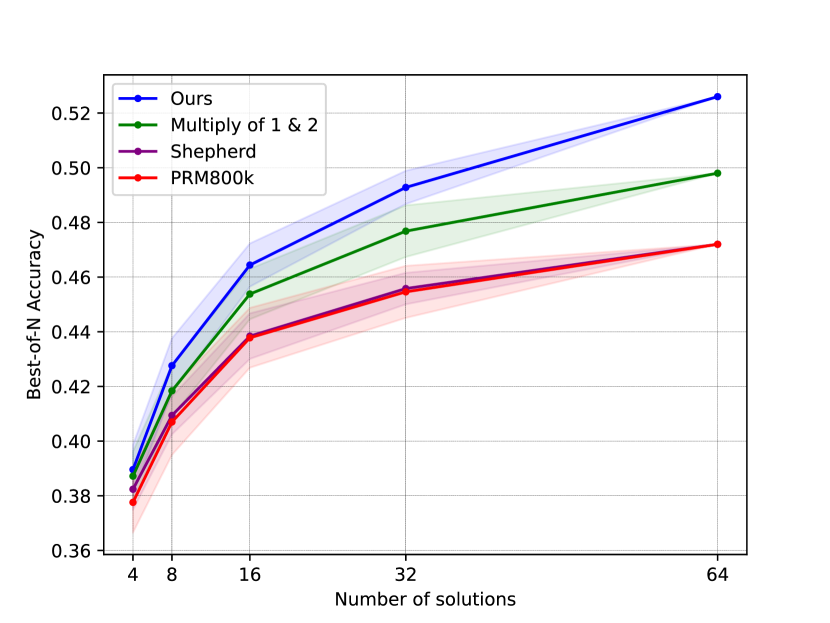
- 实验表明,DuaShepherd在MATH500和ProcessBench上显著提升了LLM的数学推理性能,优于单一奖励模型。
📝 摘要(中文)
本文提出了DuaShepherd,一种新颖的奖励建模框架,它整合了两种互补的奖励信号:正确性和潜在性,以增强大型语言模型(LLM)的数学推理能力。基于正确性的信号强调识别逐步错误,而基于潜在性的信号则侧重于达到正确最终答案的可能性。我们开发了一个自动化的流程,用于构建具有这两种信号的大规模奖励建模数据集。探索了一种统一的多头架构,以在多任务设置中训练这两个奖励模型,证明了并行学习正确性和潜在性的好处。通过将这两种信号组合成一个复合概率,我们的模型在多个基准测试中实现了持续的性能改进。在MATH500和ProcessBench上的实证评估证实,这种组合奖励明显优于仅在任一奖励类型上训练的模型,在可比的资源约束下实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在数学推理任务中表现不佳的问题。现有方法通常只关注最终答案的正确性,忽略了中间步骤的推理过程,导致模型难以发现和纠正推理过程中的错误。这种缺乏细粒度反馈的训练方式限制了LLM在复杂数学问题上的表现。
核心思路:DuaShepherd的核心思路是将数学推理过程分解为多个步骤,并对每个步骤的正确性以及最终答案的潜在正确性进行评估。通过结合基于步骤正确性的奖励和基于最终答案潜在性的奖励,DuaShepherd为LLM提供更全面、更细粒度的反馈信号,引导模型学习正确的推理路径。
技术框架:DuaShepherd框架包含以下几个主要模块:1) 数据集构建:构建包含数学问题、推理步骤、正确性标签和潜在性标签的大规模数据集。2) 奖励模型训练:使用统一的多头架构,并行训练基于步骤正确性的奖励模型和基于最终答案潜在性的奖励模型。3) 奖励信号融合:将两种奖励信号组合成一个复合概率,作为LLM训练的奖励信号。4) LLM训练:使用强化学习或其他方法,基于复合奖励信号训练LLM。
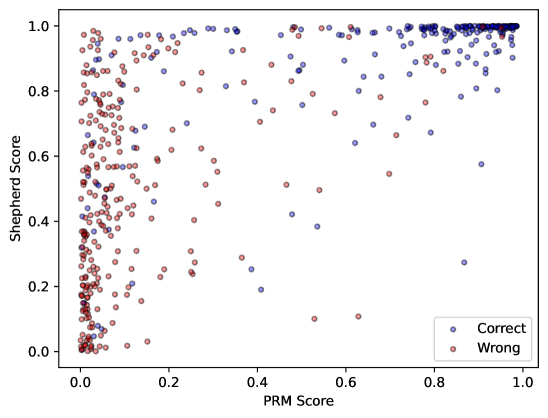
关键创新:DuaShepherd的关键创新在于同时考虑了步骤正确性和潜在奖励。与现有方法相比,DuaShepherd不仅关注最终答案的正确性,还关注中间步骤的推理过程,从而提供更全面、更细粒度的反馈信号。这种双重奖励机制能够更有效地引导LLM学习正确的推理路径,提高其在数学推理任务中的表现。
关键设计:在奖励模型训练方面,论文采用了一种统一的多头架构,其中一个头部用于预测步骤正确性,另一个头部用于预测最终答案的潜在正确性。损失函数方面,可以采用交叉熵损失函数或均方误差损失函数。在奖励信号融合方面,论文采用了一种复合概率的方法,将两种奖励信号进行加权平均。具体的权重参数可以通过实验进行调整。
🖼️ 关键图片

📊 实验亮点
DuaShepherd在MATH500和ProcessBench两个基准测试中取得了显著的性能提升。实验结果表明,DuaShepherd明显优于仅使用步骤正确性奖励或潜在奖励的模型,在可比的资源约束下实现了最先进的性能。具体的数据提升幅度在论文中进行了详细的展示。
🎯 应用场景
DuaShepherd可应用于各种需要数学推理能力的场景,例如自动解题系统、智能辅导系统、科学研究等。通过提升LLM的数学推理能力,DuaShepherd可以帮助人们更高效地解决数学问题,促进科学研究的进展,并为教育领域带来新的可能性。
📄 摘要(原文)
In this paper, we propose DuaShepherd, a novel reward modeling framework that integrates two complementary reward signals, correctness and potential, to enhance the mathematical reasoning capabilities of Large Language Models (LLMs). While correctness-based signals emphasize identification of stepwise errors, potential-based signals focus on the likelihood of reaching the correct final answer. We developed an automated pipeline for constructing large-scale reward modeling dataset with both signals. A unified, multi-head architecture was explored to train the two reward models in a multi-task setup, demonstrating benefits from learning both correctness and potential in parallel. By combining these two signals into a compound probability, our model achieves consistent performance improvements across multiple benchmarks. Empirical evaluations on MATH500 and ProcessBench confirm that this combined reward significantly outperforms models trained on either reward type alone, achieving state-of-the-art performance under comparable resource constraints.