OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
作者: Vineeth Dorna, Anmol Mekala, Wenlong Zhao, Andrew McCallum, Zachary C. Lipton, J. Zico Kolter, Pratyush Maini
分类: cs.CL
发布日期: 2025-06-14 (更新: 2025-11-09)
💡 一句话要点
OpenUnlearning:通过统一的方法和指标基准测试加速LLM的不可学习性研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不可学习性 基准测试 数据隐私 模型安全 评估指标 元评估
📋 核心要点
- 现有LLM不可学习方法缺乏统一的评估标准,难以衡量和比较不同方法的有效性。
- OpenUnlearning框架旨在提供标准化的基准测试,统一评估方法和指标,促进LLM不可学习研究。
- 该框架集成了多种算法和评估方法,并提供了大量预训练检查点,方便研究人员进行实验和分析。
📝 摘要(中文)
为了在数据隐私、模型安全和法规遵从至关重要的环境中安全地部署大型语言模型(LLM),强大的不可学习性至关重要。然而,这项任务本质上具有挑战性,部分原因是难以可靠地衡量是否真正发生了不可学习。此外,当前方法论的碎片化和不一致的评估指标阻碍了比较分析和可重复性。为了统一和加速研究工作,我们引入了OpenUnlearning,这是一个标准化的、可扩展的框架,专门用于基准测试LLM不可学习方法和指标。OpenUnlearning集成了13种不可学习算法和16种不同的评估方法,涵盖了3个领先的基准(TOFU、MUSE和WMDP),并且能够分析我们公开发布的450多个检查点的遗忘行为。利用OpenUnlearning,我们提出了一个新的元评估基准,专门用于评估评估指标本身的忠实性和鲁棒性。我们还对不同的不可学习方法进行了基准测试,并针对广泛的评估套件进行了比较分析。总而言之,我们为LLM不可学习研究的严格发展建立了一条清晰的、社区驱动的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的不可学习性问题,即如何有效地从模型中移除特定数据的影响,以满足数据隐私、模型安全和法规遵从的要求。现有方法存在碎片化、评估指标不一致等问题,难以进行比较和复现,缺乏统一的基准测试框架。
核心思路:论文的核心思路是构建一个标准化的、可扩展的基准测试框架OpenUnlearning,用于统一评估LLM的不可学习方法和评估指标。通过提供统一的评估标准和工具,促进该领域的研究和发展。
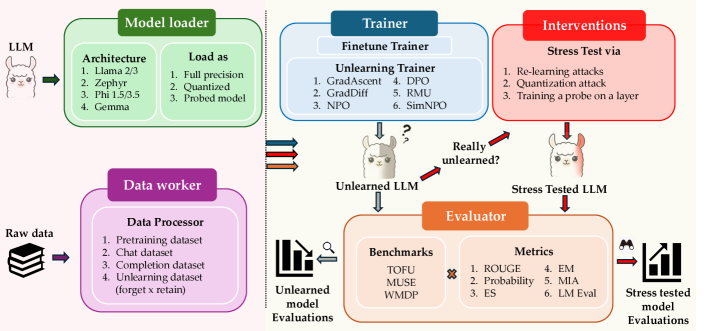
技术框架:OpenUnlearning框架主要包含以下几个部分:1) 集成了13种不可学习算法;2) 提供了16种不同的评估方法,涵盖了3个领先的基准(TOFU、MUSE和WMDP);3) 公开了450多个检查点,用于分析遗忘行为;4) 提出了一个新的元评估基准,用于评估评估指标本身的质量。
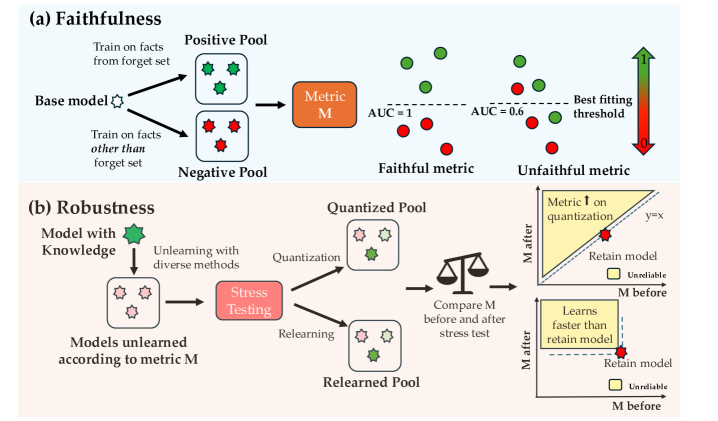
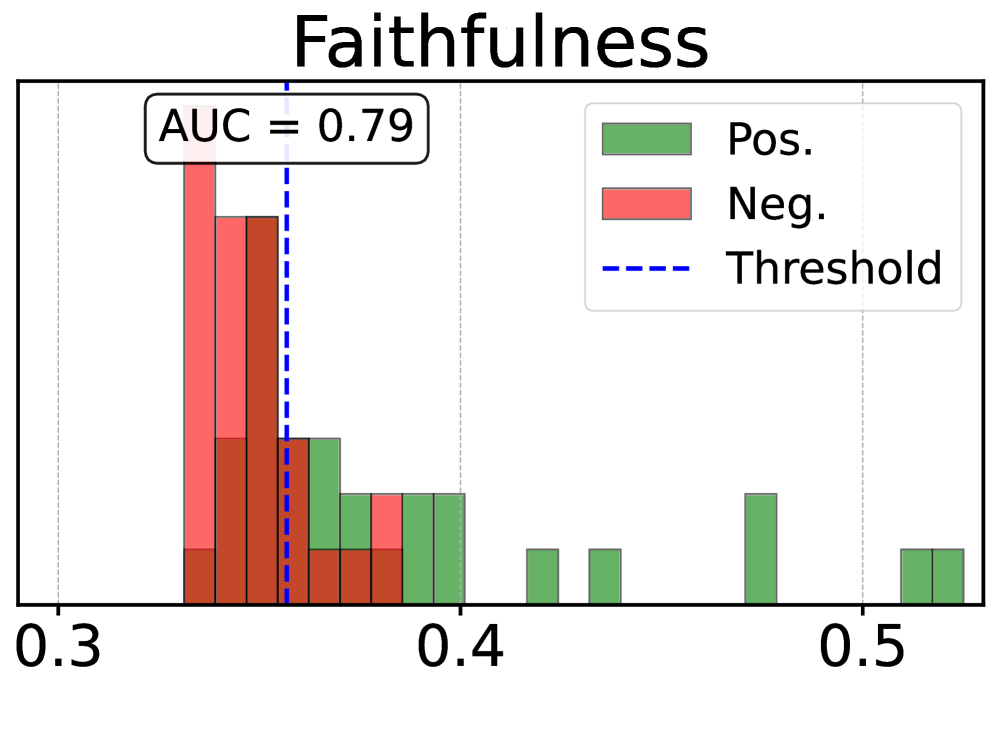
关键创新:该论文的关键创新在于提出了OpenUnlearning框架,这是一个统一的、标准化的基准测试平台,可以用于评估不同的LLM不可学习方法和评估指标。此外,论文还提出了一个元评估基准,用于评估评估指标本身的忠实性和鲁棒性,这在之前的研究中很少被关注。
关键设计:OpenUnlearning框架的关键设计包括:1) 选择了具有代表性的不可学习算法和评估指标;2) 提供了易于使用的API,方便研究人员进行实验和评估;3) 构建了元评估基准,用于评估评估指标的质量;4) 公开了大量预训练检查点,方便研究人员进行分析和比较。
🖼️ 关键图片
📊 实验亮点
OpenUnlearning框架集成了13种不可学习算法和16种评估方法,涵盖了3个领先的基准(TOFU、MUSE和WMDP),并提供了450多个检查点。论文还提出了一个元评估基准,用于评估评估指标本身的质量。通过OpenUnlearning框架,可以对不同的不可学习方法进行基准测试和比较分析,从而更好地理解和改进LLM的不可学习性。
🎯 应用场景
OpenUnlearning框架可应用于各种需要确保数据隐私和模型安全的场景,例如金融、医疗、法律等领域。通过该框架,可以更好地评估和改进LLM的不可学习方法,从而降低模型泄露敏感信息的风险,并满足法规遵从的要求。该研究的未来影响在于推动LLM不可学习技术的进步,促进LLM在安全敏感领域的应用。
📄 摘要(原文)
Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 13 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.