Exploring Cultural Variations in Moral Judgments with Large Language Models
作者: Hadi Mohammadi, Ayoub Bagheri
分类: cs.CL
发布日期: 2025-06-14 (更新: 2026-01-04)
💡 一句话要点
探讨大语言模型在道德判断中的文化差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 道德判断 文化差异 指令调优 相关性分析 伦理研究 跨文化交流
📋 核心要点
- 现有的大语言模型在捕捉文化多样性道德价值方面存在不足,尤其是在不同地区的道德态度反映上。
- 本文通过比较不同规模和类型的语言模型,提出使用道德可辩护性评分来评估模型输出与人类道德判断的相关性。
- 实验结果表明,先进的指令调优模型在道德判断的相关性上显著高于早期模型,尤其是在W.E.I.R.D.国家的表现更佳。
📝 摘要(中文)
大语言模型(LLMs)在多项任务中表现出色,但其捕捉文化多样性道德价值的能力尚不明确。本文研究LLMs是否反映世界价值调查(WVS)和皮尤研究中心全球态度调查(PEW)中报告的道德态度差异。通过对比小型单语和多语模型(如GPT-2、OPT、BLOOMZ和Qwen)与最新的指令调优模型(如GPT-4o、GPT-4o-mini、Gemma-2-9b-it和Llama-3.3-70B-Instruct),我们使用基于对数概率的道德可辩护性评分,分析模型输出与涵盖广泛伦理主题的调查数据之间的相关性。结果显示,早期或小型模型与人类判断的相关性接近零或为负,而先进的指令调优模型则显著提高了正相关性,表明它们更好地反映现实世界的道德态度。我们还进行了详细的区域分析,发现模型在西方、受过教育、工业化、富裕和民主(W.E.I.R.D.)国家的表现优于其他地区。尽管模型规模和指令调优提高了与跨文化道德规范的对齐,但某些主题和地区仍面临挑战。我们讨论了这些发现与偏见分析、训练数据多样性、信息检索影响及提高LLMs文化敏感性的策略之间的关系。
🔬 方法详解
问题定义:本文旨在解决大语言模型在道德判断中对文化多样性反映不足的问题,现有模型在不同文化背景下的道德态度表现不佳。
核心思路:通过对比不同规模的语言模型,特别是指令调优模型,评估其在道德判断上的表现,旨在提高模型对文化道德规范的敏感性。
技术框架:研究采用了对比实验的方法,分析了多种语言模型的输出,并与WVS和PEW的调查数据进行相关性分析,主要模块包括模型选择、数据收集和相关性计算。
关键创新:本研究的创新点在于使用道德可辩护性评分来量化模型输出与人类道德判断的相关性,揭示了指令调优模型在道德判断上的优势。
关键设计:在实验中,模型的选择涵盖了小型和大型模型,使用了对数概率作为评分标准,确保了评估的准确性和可靠性。
🖼️ 关键图片
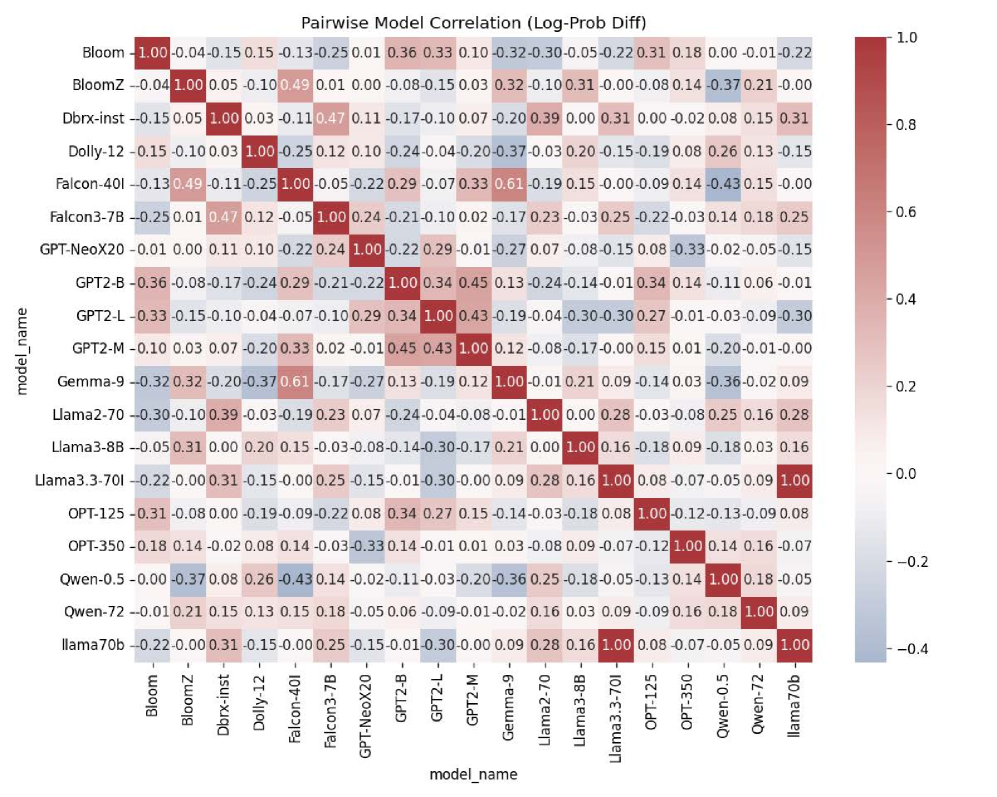
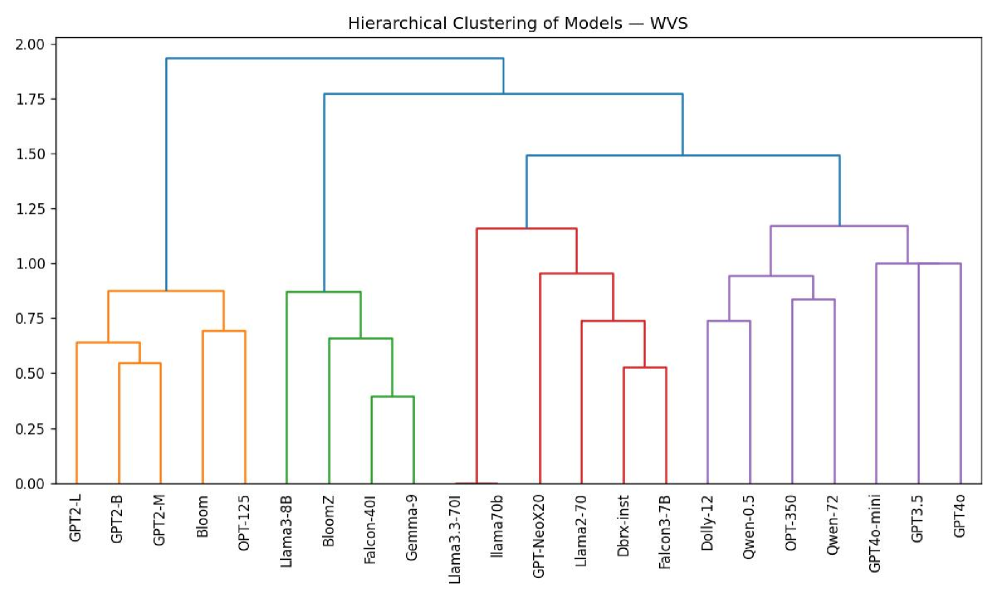
📊 实验亮点
实验结果显示,指令调优模型在道德判断的相关性上显著高于早期模型,尤其在W.E.I.R.D.国家的相关性达到了显著的正值,表明这些模型更能反映真实的道德态度。
🎯 应用场景
该研究的潜在应用领域包括道德决策支持系统、文化适应性AI助手以及跨文化交流平台。通过提高大语言模型对文化道德规范的理解,能够更好地服务于多元文化背景下的用户需求,促进文化间的理解与交流。
📄 摘要(原文)
Large Language Models (LLMs) have shown strong performance across many tasks, but their ability to capture culturally diverse moral values remains unclear. In this paper, we examine whether LLMs mirror variations in moral attitudes reported by the World Values Survey (WVS) and the Pew Research Center's Global Attitudes Survey (PEW). We compare smaller monolingual and multilingual models (GPT-2, OPT, BLOOMZ, and Qwen) with recent instruction-tuned models (GPT-4o, GPT-4o-mini, Gemma-2-9b-it, and Llama-3.3-70B-Instruct). Using log-probability-based \emph{moral justifiability} scores, we correlate each model's outputs with survey data covering a broad set of ethical topics. Our results show that many earlier or smaller models often produce near-zero or negative correlations with human judgments. In contrast, advanced instruction-tuned models achieve substantially higher positive correlations, suggesting they better reflect real-world moral attitudes. We provide a detailed regional analysis revealing that models align better with Western, Educated, Industrialized, Rich, and Democratic (W.E.I.R.D.) nations than with other regions. While scaling model size and using instruction tuning improves alignment with cross-cultural moral norms, challenges remain for certain topics and regions. We discuss these findings in relation to bias analysis, training data diversity, information retrieval implications, and strategies for improving the cultural sensitivity of LLMs.