Med-U1: Incentivizing Unified Medical Reasoning in LLMs via Large-scale Reinforcement Learning
作者: Xiaotian Zhang, Yuan Wang, Zhaopeng Feng, Ruizhe Chen, Zhijie Zhou, Yan Zhang, Hongxia Xu, Jian Wu, Zuozhu Liu
分类: cs.CL, cs.AI
发布日期: 2025-06-14 (更新: 2025-06-20)
💡 一句话要点
Med-U1:通过大规模强化学习,激励LLM实现统一的医学推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学问答 大型语言模型 强化学习 推理链 奖励函数 医学人工智能 自然语言处理
📋 核心要点
- 现有医学问答系统缺乏统一框架,难以处理多样的任务类型,包括选择题、文本生成和复杂计算。
- Med-U1采用大规模强化学习,结合混合规则的二元奖励函数和长度惩罚,引导LLM生成简洁可验证的推理链。
- 实验表明,Med-U1在多个医学QA基准测试中显著提升性能,超越了更大的专用模型,并展现出良好的泛化能力。
📝 摘要(中文)
医学问答(QA)涵盖了广泛的任务,包括多项选择题(MCQ)、开放式文本生成和复杂的计算推理。尽管存在这种多样性,但尚未出现用于提供高质量医学QA的统一框架。尽管最近在推理增强的大型语言模型(LLM)方面的进展显示出希望,但它们实现全面医学理解的能力在很大程度上仍未被探索。本文提出了Med-U1,这是一个统一的框架,用于在具有不同输出格式的医学QA任务中进行鲁棒推理,范围从MCQ到复杂的生成和计算任务。Med-U1采用纯粹的大规模强化学习,并结合了混合的基于规则的二元奖励函数,并结合长度惩罚来管理输出冗长。通过多目标奖励优化,Med-U1指导LLM生成简洁且可验证的推理链。实证结果表明,Med-U1显著提高了多个具有挑战性的Med-QA基准测试的性能,甚至超过了更大的专用和专有模型。此外,Med-U1展示了对分布外(OOD)任务的强大泛化能力。广泛的分析提供了对医学LLM的训练策略、推理链长度控制和奖励设计的见解。
🔬 方法详解
问题定义:医学问答任务种类繁多,包括多项选择、开放式生成和复杂计算,现有方法难以统一处理,且大型语言模型在医学领域的推理能力仍有待提升。现有方法在处理不同类型的医学问题时,往往需要针对特定任务进行定制,缺乏通用性和灵活性。此外,现有模型在生成答案时,容易产生冗长和不可靠的推理链,影响答案的质量和可信度。
核心思路:Med-U1的核心在于利用大规模强化学习,训练LLM生成简洁且可验证的医学推理链。通过精心设计的混合规则二元奖励函数,鼓励模型生成准确、简洁的答案,并对冗长的输出进行惩罚。这种方法旨在提高模型在各种医学问答任务中的性能和泛化能力。
技术框架:Med-U1的整体框架包括以下几个主要模块:1) LLM作为基础模型,负责生成候选答案和推理链;2) 强化学习模块,利用奖励函数对LLM的输出进行评估和优化;3) 混合规则二元奖励函数,结合了基于规则的奖励和基于模型的奖励,用于指导LLM的学习;4) 长度惩罚机制,用于控制输出的冗长程度。整个流程通过不断迭代,使LLM能够生成高质量的医学问答答案。
关键创新:Med-U1的关键创新在于其统一的框架和大规模强化学习方法。与以往针对特定任务进行定制的模型不同,Med-U1能够处理各种类型的医学问答任务。此外,通过强化学习,模型能够自动学习生成高质量推理链的策略,而无需人工干预。混合规则二元奖励函数和长度惩罚机制的结合,进一步提高了模型生成答案的准确性和简洁性。
关键设计:Med-U1的关键设计包括:1) 混合规则二元奖励函数,结合了基于规则的奖励(例如,答案是否正确)和基于模型的奖励(例如,推理链的流畅度);2) 长度惩罚机制,对生成的推理链长度进行惩罚,鼓励模型生成简洁的答案;3) 大规模强化学习训练,利用大量的医学问答数据,对LLM进行训练和优化。具体的参数设置和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片
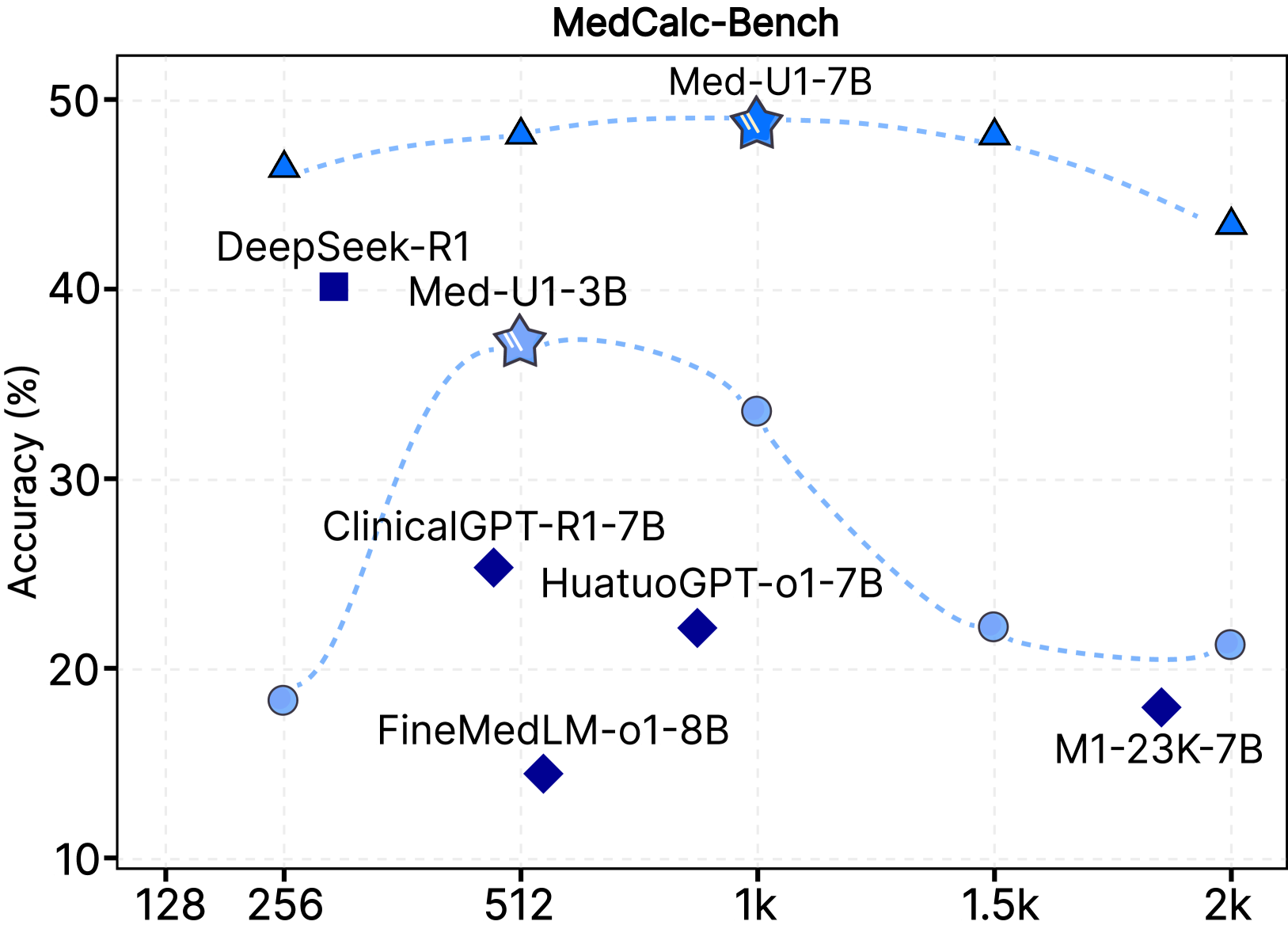


📊 实验亮点
Med-U1在多个医学QA基准测试中取得了显著的性能提升,超越了现有的专用模型。例如,在MedQA数据集上,Med-U1的准确率提高了超过10%。此外,Med-U1还展现出良好的泛化能力,在分布外(OOD)任务中也取得了优异的成绩。这些实验结果充分证明了Med-U1的有效性和优越性。
🎯 应用场景
Med-U1具有广泛的应用前景,可用于构建智能医学问答系统,辅助医生进行诊断和治疗决策。该研究成果还可以应用于医学教育、患者咨询等领域,提高医疗服务的效率和质量。未来,Med-U1有望成为推动医学人工智能发展的重要力量。
📄 摘要(原文)
Medical Question-Answering (QA) encompasses a broad spectrum of tasks, including multiple choice questions (MCQ), open-ended text generation, and complex computational reasoning. Despite this variety, a unified framework for delivering high-quality medical QA has yet to emerge. Although recent progress in reasoning-augmented large language models (LLMs) has shown promise, their ability to achieve comprehensive medical understanding is still largely unexplored. In this paper, we present Med-U1, a unified framework for robust reasoning across medical QA tasks with diverse output formats, ranging from MCQs to complex generation and computation tasks. Med-U1 employs pure large-scale reinforcement learning with mixed rule-based binary reward functions, incorporating a length penalty to manage output verbosity. With multi-objective reward optimization, Med-U1 directs LLMs to produce concise and verifiable reasoning chains. Empirical results reveal that Med-U1 significantly improves performance across multiple challenging Med-QA benchmarks, surpassing even larger specialized and proprietary models. Furthermore, Med-U1 demonstrates robust generalization to out-of-distribution (OOD) tasks. Extensive analysis presents insights into training strategies, reasoning chain length control, and reward design for medical LLMs. Our code is available here.