Can LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
作者: Yuhan Cao, Zian Chen, Kun Quan, Ziliang Zhang, Yu Wang, Xiaoning Dong, Yeqi Feng, Guanzhong He, Jingcheng Huang, Jianhao Li, Yixuan Tan, Jiafu Tang, Yilin Tang, Junlei Wu, Qianyu Xiao, Can Zheng, Shouchen Zhou, Yuxiang Zhu, Yiming Huang, Tianxing He
分类: cs.CL, cs.AI, cs.SE
发布日期: 2025-06-07 (更新: 2026-01-14)
备注: 37 pages, 22 figures
💡 一句话要点
TCGBench:评估大语言模型在竞赛级编程问题中生成可靠测试用例生成器的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试用例生成 代码调试 竞赛级编程 TCGBench
📋 核心要点
- 现有方法难以利用LLM进行代码调试,缺乏对LLM生成测试用例能力的深入探索,尤其是在竞赛级编程问题中。
- 提出TCGBench基准,包含生成有效测试用例生成器和针对性测试用例生成器两个任务,评估LLM在竞赛级编程问题中的测试能力。
- 实验表明,LLM能生成有效测试用例生成器,但难以生成针对性测试用例,人工数据集能有效提升LLM的针对性测试能力。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面表现出了卓越的能力,能够在推理过程中处理复杂的任务。然而,LLMs通过生成测试用例来进行代码检查或调试的潜力在很大程度上尚未被探索。我们从竞赛级编程(CP)程序的角度研究了这个问题,并提出了TCGBench,一个用于(LLM生成)测试用例生成器的基准。该基准包括两个任务,旨在研究LLMs在以下方面的能力:(1)为给定的CP问题生成有效的测试用例生成器,以及(2)生成有针对性的测试用例生成器,以暴露人工编写代码中的错误。实验结果表明,虽然最先进的LLMs可以在大多数情况下生成有效的测试用例生成器,但大多数LLMs难以生成能够有效揭示人工代码缺陷的有针对性的测试用例。特别是,即使是高级推理模型(例如,o3-mini)在生成有针对性的生成器方面也远低于人类的表现。此外,我们构建了一个高质量、人工策划的指令数据集,用于生成有针对性的生成器。分析表明,通过提示和微调,借助该数据集可以提高LLMs的性能。
🔬 方法详解
问题定义:论文旨在解决如何评估和提升大型语言模型(LLMs)在竞赛级编程(CP)问题中生成可靠测试用例生成器的能力。现有方法缺乏对LLMs在代码调试方面的有效利用,尤其是在生成能够暴露人工编写代码错误的针对性测试用例方面存在不足。
核心思路:论文的核心思路是构建一个专门的基准测试集TCGBench,并通过实验评估LLMs在生成有效和针对性测试用例生成器方面的能力。同时,通过人工构建高质量的指令数据集,探索提升LLMs生成针对性测试用例生成器性能的方法。
技术框架:TCGBench基准包含两个主要任务:1) 生成有效的测试用例生成器,确保生成的测试用例符合问题描述的约束;2) 生成针对性的测试用例生成器,旨在暴露人工编写代码中的潜在错误。论文还构建了一个人工标注的指令数据集,用于指导LLMs生成更有效的针对性测试用例。整体流程包括使用不同的LLMs在TCGBench上进行评估,分析其性能瓶颈,并利用人工数据集进行提示或微调,以提升性能。
关键创新:论文的关键创新在于提出了TCGBench基准,为评估LLMs在代码测试和调试方面的能力提供了一个标准化的平台。此外,人工构建的高质量指令数据集为提升LLMs生成针对性测试用例生成器的性能提供了一种有效的方法。
关键设计:论文的关键设计包括:1) TCGBench基准的构建,确保其包含多样化的竞赛级编程问题,并提供清晰的评估指标;2) 人工指令数据集的设计,确保其能够有效地指导LLMs生成针对性测试用例;3) 实验方案的设计,包括选择合适的LLMs、设计有效的提示策略以及进行微调实验。
🖼️ 关键图片
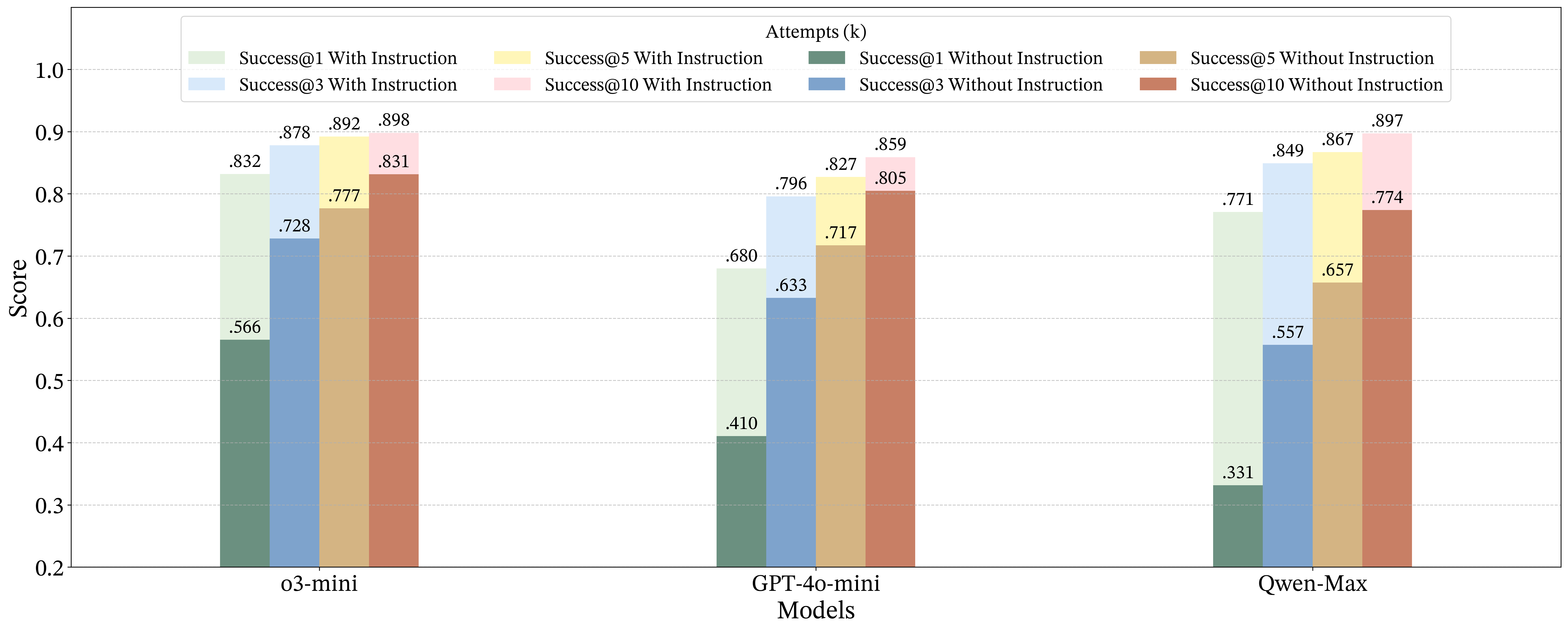
📊 实验亮点
实验结果表明,虽然最先进的LLMs可以生成有效的测试用例生成器,但它们在生成能够有效揭示人工代码缺陷的有针对性的测试用例方面表现不佳。即使是高级推理模型(如o3-mini)也远低于人类的表现。通过使用人工构建的高质量指令数据集进行提示和微调,可以显著提高LLMs生成针对性测试用例生成器的性能。
🎯 应用场景
该研究成果可应用于自动化软件测试、代码调试和教育领域。通过利用LLM自动生成测试用例,可以提高软件测试的效率和覆盖率,帮助开发者快速发现和修复代码中的错误。此外,该研究还可以用于编程教育,帮助学生更好地理解和掌握编程技能。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.