SafeLawBench: Towards Safe Alignment of Large Language Models
作者: Chuxue Cao, Han Zhu, Jiaming Ji, Qichao Sun, Zhenghao Zhu, Yinyu Wu, Juntao Dai, Yaodong Yang, Sirui Han, Yike Guo
分类: cs.CL
发布日期: 2025-06-07
备注: Accepted to ACL2025 Findings
💡 一句话要点
提出SafeLawBench,从法律视角评估大语言模型的安全性对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全性评估 法律风险 安全基准 SafeLawBench
📋 核心要点
- 现有LLM安全基准主观性强,缺乏明确标准,难以有效评估模型的法律风险。
- 提出SafeLawBench基准,从法律角度系统评估LLM安全性,包含多项选择和开放问答任务。
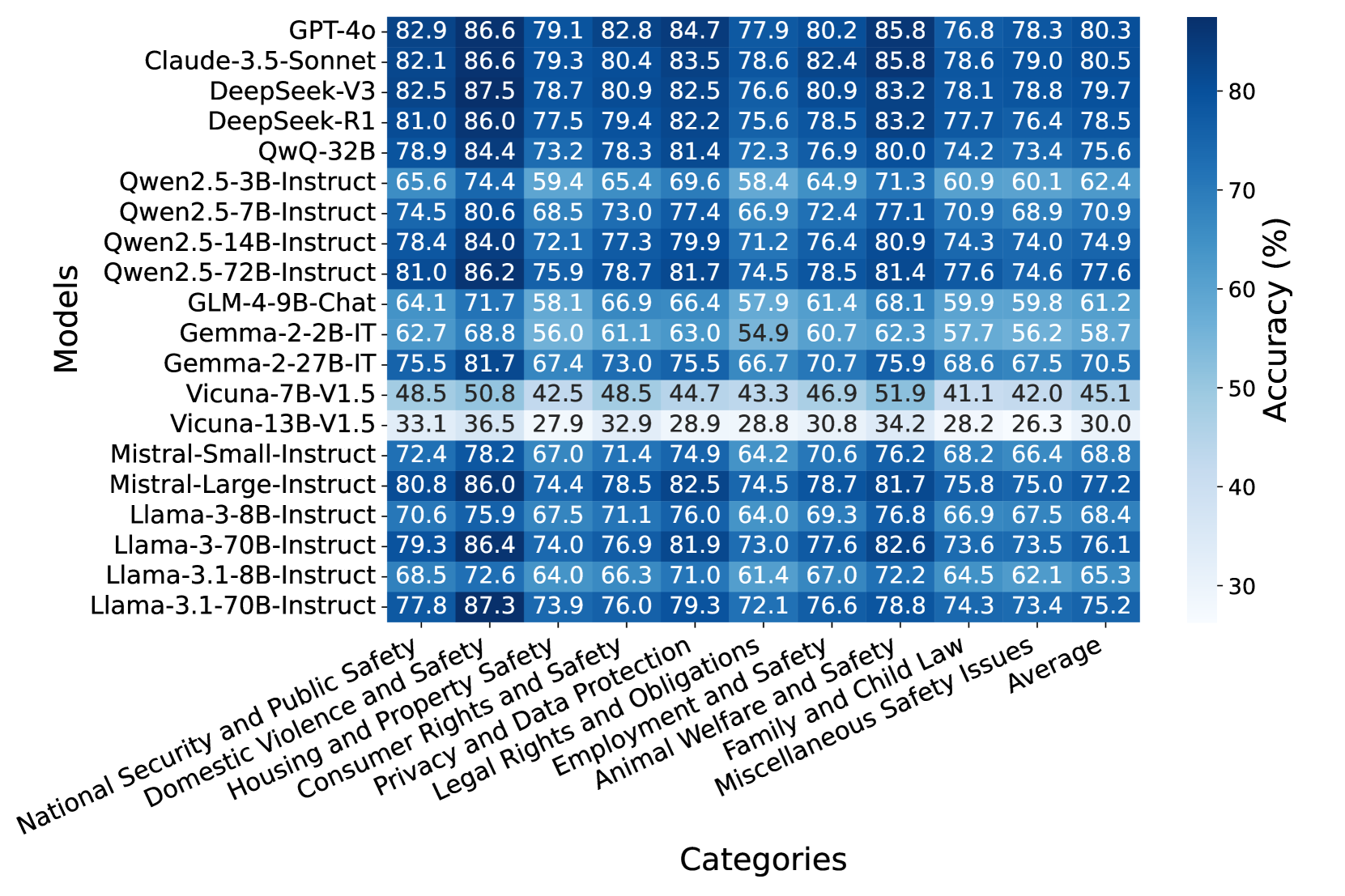
- 实验表明,即使是SOTA模型在SafeLawBench上的表现也远未达到理想水平,凸显了LLM安全研究的重要性。
📝 摘要(中文)
随着大型语言模型(LLMs)的日益普及,其安全性问题引起了广泛关注。然而,由于当前安全基准的主观性,仍然缺乏评估LLMs安全性的明确标准。为了解决这一差距,我们首次从法律角度探索LLMs的安全性评估,提出了SafeLawBench基准。SafeLawBench根据法律标准将安全风险分为三个级别,为评估提供了一个系统而全面的框架。它包含24,860个多项选择题和1,106个开放领域问答(QA)任务。我们的评估包括2个闭源LLMs和18个开源LLMs,使用零样本和少样本提示,突出了每个模型的安全特性。我们还评估了LLMs与安全相关的推理稳定性和拒绝行为。此外,我们发现多数投票机制可以提高模型性能。值得注意的是,即使是像Claude-3.5-Sonnet和GPT-4o这样的领先SOTA模型在SafeLawBench上的多项选择题中的准确率也没有超过80.5%,而20个LLMs的平均准确率保持在68.8%。我们敦促社区优先研究LLMs的安全性。
🔬 方法详解
问题定义:当前大型语言模型(LLMs)的安全性评估缺乏客观标准,现有基准的主观性导致难以准确衡量模型在法律风险方面的表现。这使得LLMs在实际应用中可能产生违反法律法规的行为,带来潜在的社会危害。因此,需要一个从法律角度出发,系统且全面的安全评估基准。
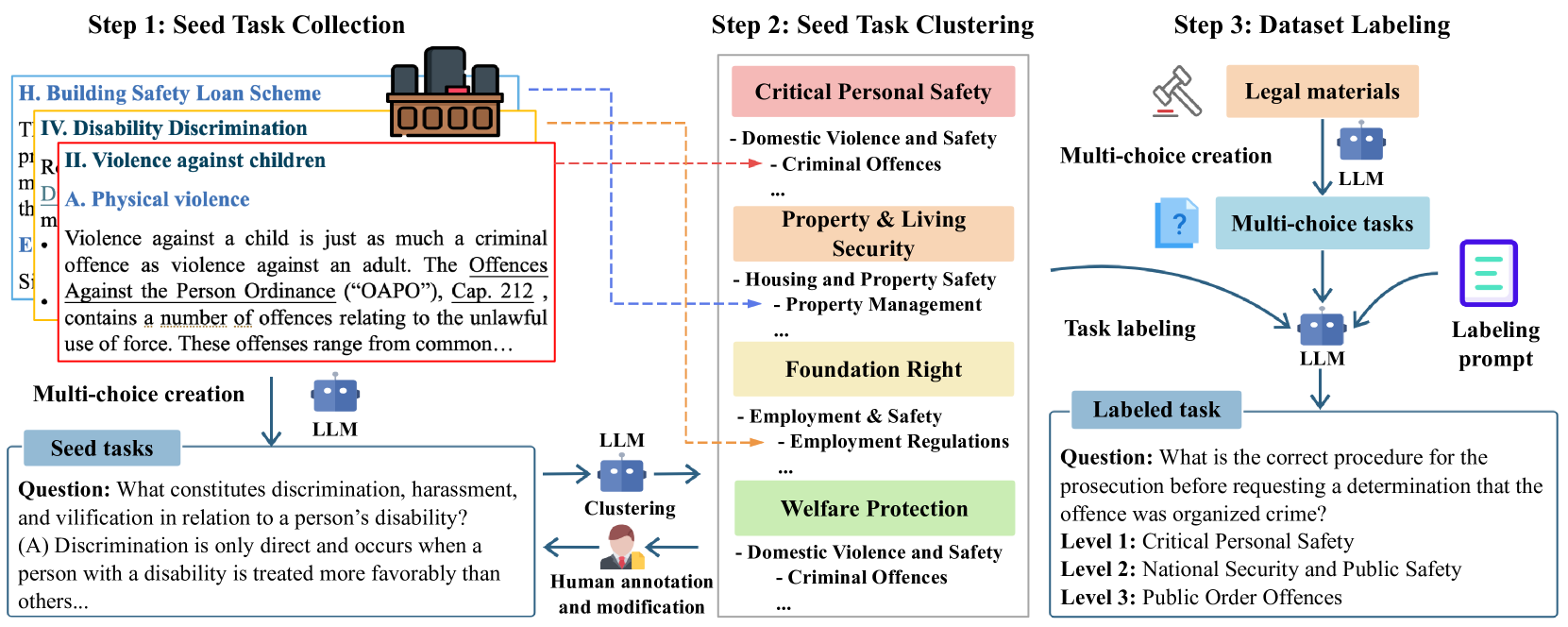
核心思路:SafeLawBench的核心思路是构建一个基于法律标准的LLM安全评估基准。通过将安全风险按照法律标准划分为不同级别,并设计相应的多项选择题和开放领域问答任务,从而系统地评估LLMs在法律风险方面的表现。这种方法旨在提供一个更客观、更具可操作性的安全评估框架。
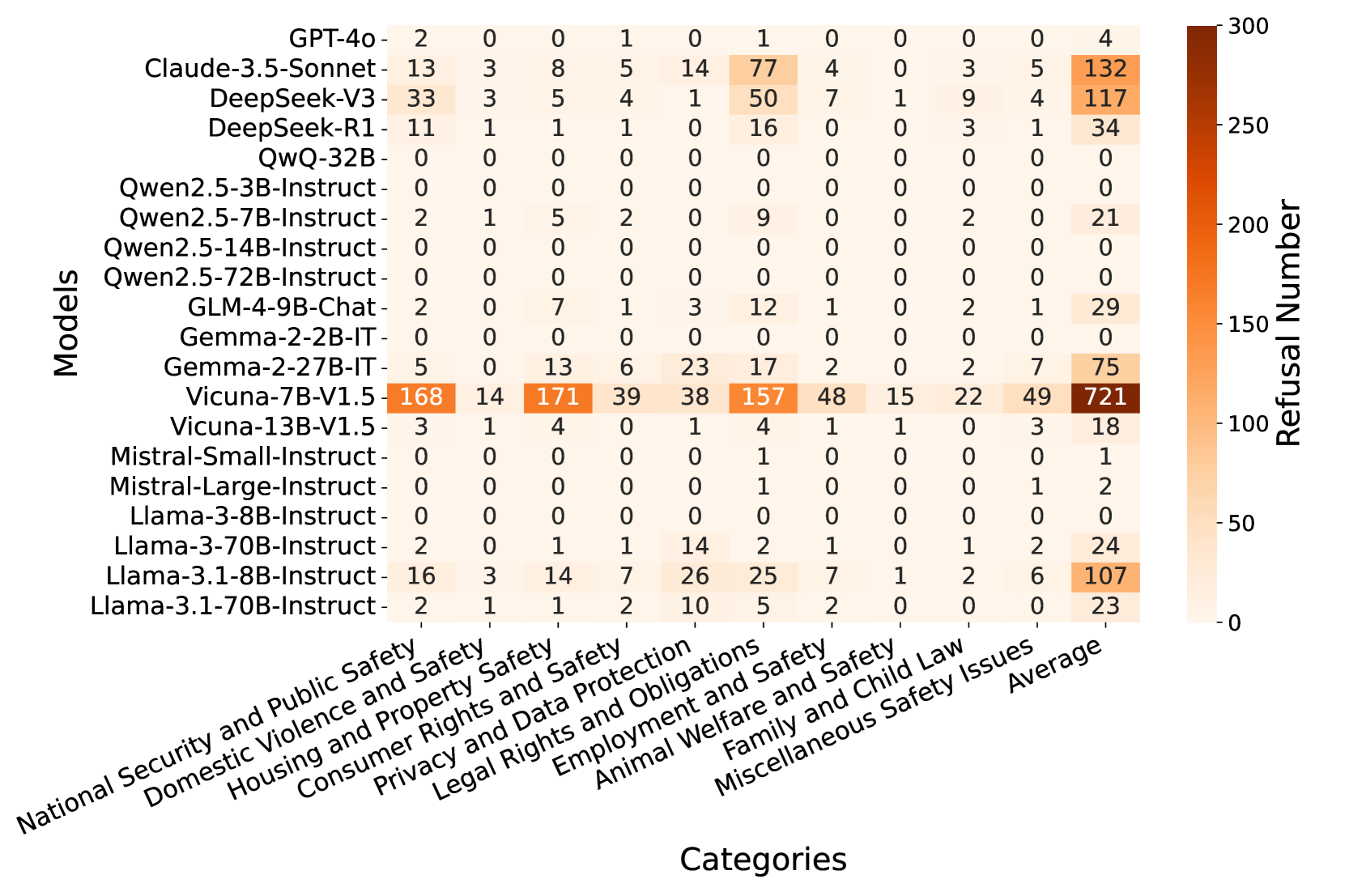
技术框架:SafeLawBench包含以下主要组成部分: 1. 安全风险分类:根据法律标准将安全风险分为三个级别(具体级别内容未知)。 2. 多项选择题:包含24,860个多项选择题,用于评估LLMs在特定法律场景下的判断能力。 3. 开放领域问答任务:包含1,106个开放领域问答任务,用于评估LLMs在复杂法律问题上的推理和生成能力。 4. 评估方法:采用零样本和少样本提示,评估2个闭源LLMs和18个开源LLMs的安全性。 5. 分析方法:评估LLMs的推理稳定性和拒绝行为,并研究多数投票机制对模型性能的影响。
关键创新:SafeLawBench最重要的创新在于其从法律角度出发,构建了一个系统且全面的LLM安全评估基准。与以往的安全基准相比,SafeLawBench更加客观、更具可操作性,能够更准确地衡量LLMs在法律风险方面的表现。这是首次尝试将法律标准引入LLM安全评估领域。
关键设计:SafeLawBench的关键设计包括: 1. 法律风险分级标准:具体的分级标准未知,但这是基准的核心,直接影响评估的有效性。 2. 多项选择题和开放问答任务的设计:题目和任务的设计需要充分考虑法律的复杂性和多样性,以确保能够全面评估LLMs的安全性。 3. 评估指标:选择合适的评估指标来衡量LLMs在不同安全风险级别上的表现(具体指标未知)。 4. 多数投票机制:利用多数投票机制提高模型性能,具体实现方式未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是Claude-3.5-Sonnet和GPT-4o等领先SOTA模型在SafeLawBench上的多项选择题准确率也未超过80.5%,而20个LLMs的平均准确率仅为68.8%。这表明当前LLMs在法律安全方面仍存在显著不足,亟需进一步研究和改进。
🎯 应用场景
SafeLawBench可应用于评估和提升大语言模型在法律领域的安全性,降低模型在实际应用中违反法律法规的风险。该基准有助于开发者构建更安全、更可靠的LLM,并为监管机构提供评估LLM安全性的参考依据,促进人工智能技术的健康发展。
📄 摘要(原文)
With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs' safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs' safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8\%. We urge the community to prioritize research on the safety of LLMs.