Multimodal Fusion with Semi-Supervised Learning Minimizes Annotation Quantity for Modeling Videoconference Conversation Experience
作者: Andrew Chang, Chenkai Hu, Ji Qi, Zhuojian Wei, Kexin Zhang, Viswadruth Akkaraju, David Poeppel, Dustin Freeman
分类: eess.AS, cs.CL, cs.HC, cs.LG, cs.MM
发布日期: 2025-06-01
备注: Interspeech 2025
DOI: 10.21437/Interspeech.2025-2451
💡 一句话要点
提出半监督多模态融合方法,高效建模视频会议中的负面体验时刻
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 多模态融合 协同训练 视频会议 情感分析 深度学习 特征提取
📋 核心要点
- 视频会议负面体验时刻难以捕捉,有监督学习需要大量标注数据,成本高昂。
- 利用半监督学习,结合少量标注数据和大量未标注数据,训练多模态深度特征。
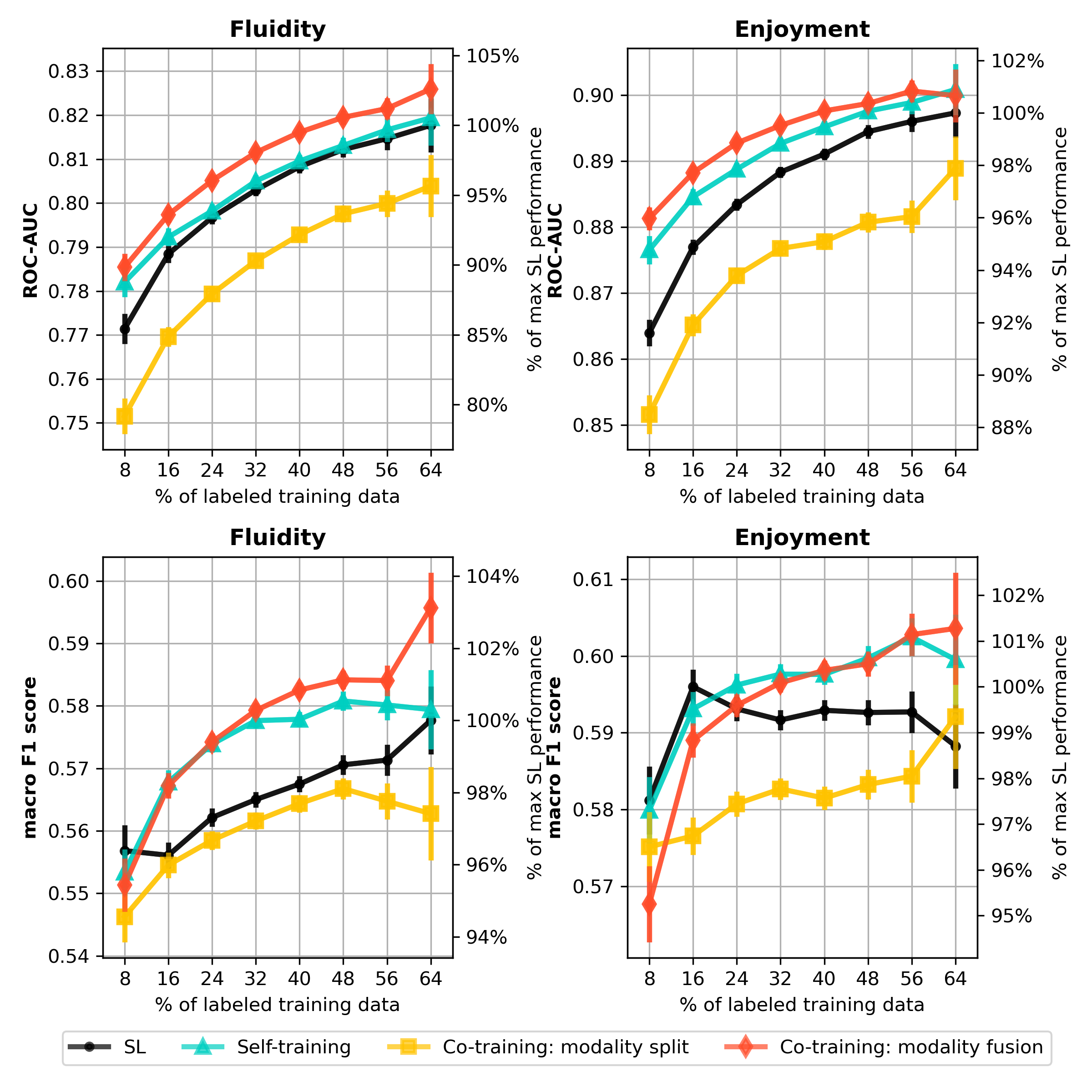
- 实验表明,该方法在少量标注下即可达到接近全数据有监督学习的性能,显著降低标注成本。
📝 摘要(中文)
视频会议中的群体对话是一种复杂的社会行为。然而,对话失去流畅性或乐趣的负面体验时刻仍然缺乏研究。这些时刻在自然数据中很少出现,因此训练有监督学习(SL)模型需要昂贵的手动数据标注。我们应用半监督学习(SSL)来利用有针对性的标记和未标记片段,训练多模态(音频、面部、文本)深度特征,以预测视频会议会话中的非流畅或令人不快的时刻。多模态融合的协同训练SSL实现了0.9的ROC-AUC和0.6的F1分数,在使用相同数量的标记数据的情况下,优于SL模型高达4%。值得注意的是,最佳的SSL模型仅使用8%的标记数据就达到了SL模型使用完整数据性能的96%。这展示了一种注释高效的框架,用于建模视频会议体验。
🔬 方法详解
问题定义:论文旨在解决视频会议场景下,难以有效识别和预测对话中的非流畅或令人不快的负面体验时刻的问题。现有有监督学习方法依赖大量人工标注数据,成本高昂,且负面体验时刻本身在自然数据中就比较稀少,导致模型训练困难。
核心思路:论文的核心思路是利用半监督学习(SSL),结合少量标注数据和大量未标注数据,来训练一个能够准确预测视频会议负面体验时刻的多模态模型。通过利用未标注数据中的信息,减少对大量标注数据的依赖,从而降低标注成本,提高模型训练效率。
技术框架:整体框架采用多模态融合的协同训练(Co-training)半监督学习方法。主要包含以下模块:1) 多模态特征提取:分别从音频、面部和文本数据中提取深度特征。2) 协同训练:使用不同的模态特征训练多个分类器,每个分类器使用少量标注数据和大量未标注数据进行训练。3) 伪标签生成:每个分类器对未标注数据进行预测,生成伪标签。4) 互相学习:分类器之间互相学习,利用彼此生成的伪标签来提高自身的预测能力。5) 模型融合:将多个分类器的预测结果进行融合,得到最终的预测结果。
关键创新:该论文的关键创新在于将多模态融合和协同训练半监督学习方法应用于视频会议负面体验建模。与传统的有监督学习方法相比,该方法能够显著减少对标注数据的依赖,提高模型训练效率。此外,协同训练框架能够有效利用不同模态之间的互补信息,提高模型的预测准确率。
关键设计:论文中,音频特征使用预训练的音频模型提取,面部特征使用人脸检测和关键点检测算法提取,文本特征使用预训练的语言模型提取。损失函数采用交叉熵损失函数,用于衡量模型预测结果与真实标签之间的差异。网络结构采用深度神经网络,包括卷积神经网络(CNN)和循环神经网络(RNN),用于提取多模态特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该半监督多模态融合方法在预测视频会议负面体验时刻方面表现出色。在相同标注数据量下,该方法比有监督学习模型提升了高达4%的ROC-AUC和F1分数。更重要的是,仅使用8%的标注数据,该方法就能达到有监督学习模型使用全部数据时96%的性能,显著降低了标注成本。
🎯 应用场景
该研究成果可应用于智能会议系统,自动识别和预警会议中的负面体验时刻,帮助主持人及时调整会议节奏和内容,提升会议效率和用户体验。此外,该方法还可推广到其他需要处理多模态数据且标注成本较高的场景,如情感分析、行为识别等。
📄 摘要(原文)
Group conversations over videoconferencing are a complex social behavior. However, the subjective moments of negative experience, where the conversation loses fluidity or enjoyment remain understudied. These moments are infrequent in naturalistic data, and thus training a supervised learning (SL) model requires costly manual data annotation. We applied semi-supervised learning (SSL) to leverage targeted labeled and unlabeled clips for training multimodal (audio, facial, text) deep features to predict non-fluid or unenjoyable moments in holdout videoconference sessions. The modality-fused co-training SSL achieved an ROC-AUC of 0.9 and an F1 score of 0.6, outperforming SL models by up to 4% with the same amount of labeled data. Remarkably, the best SSL model with just 8% labeled data matched 96% of the SL model's full-data performance. This shows an annotation-efficient framework for modeling videoconference experience.