Understanding and Mitigating Cross-lingual Privacy Leakage via Language-specific and Universal Privacy Neurons
作者: Wenshuo Dong, Qingsong Yang, Shu Yang, Lijie Hu, Meng Ding, Wanyu Lin, Tianhang Zheng, Di Wang
分类: cs.CL
发布日期: 2025-06-01 (更新: 2025-06-08)
💡 一句话要点
提出语言特定和通用隐私神经元识别方法,缓解跨语言隐私泄露问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言隐私泄露 大型语言模型 隐私神经元 信息流分析 隐私保护
📋 核心要点
- 现有隐私保护方法主要针对单语环境,无法有效防御跨语言场景下的隐私泄露风险。
- 通过分析跨语言隐私泄露的信息流,识别出通用和语言特定的隐私神经元。
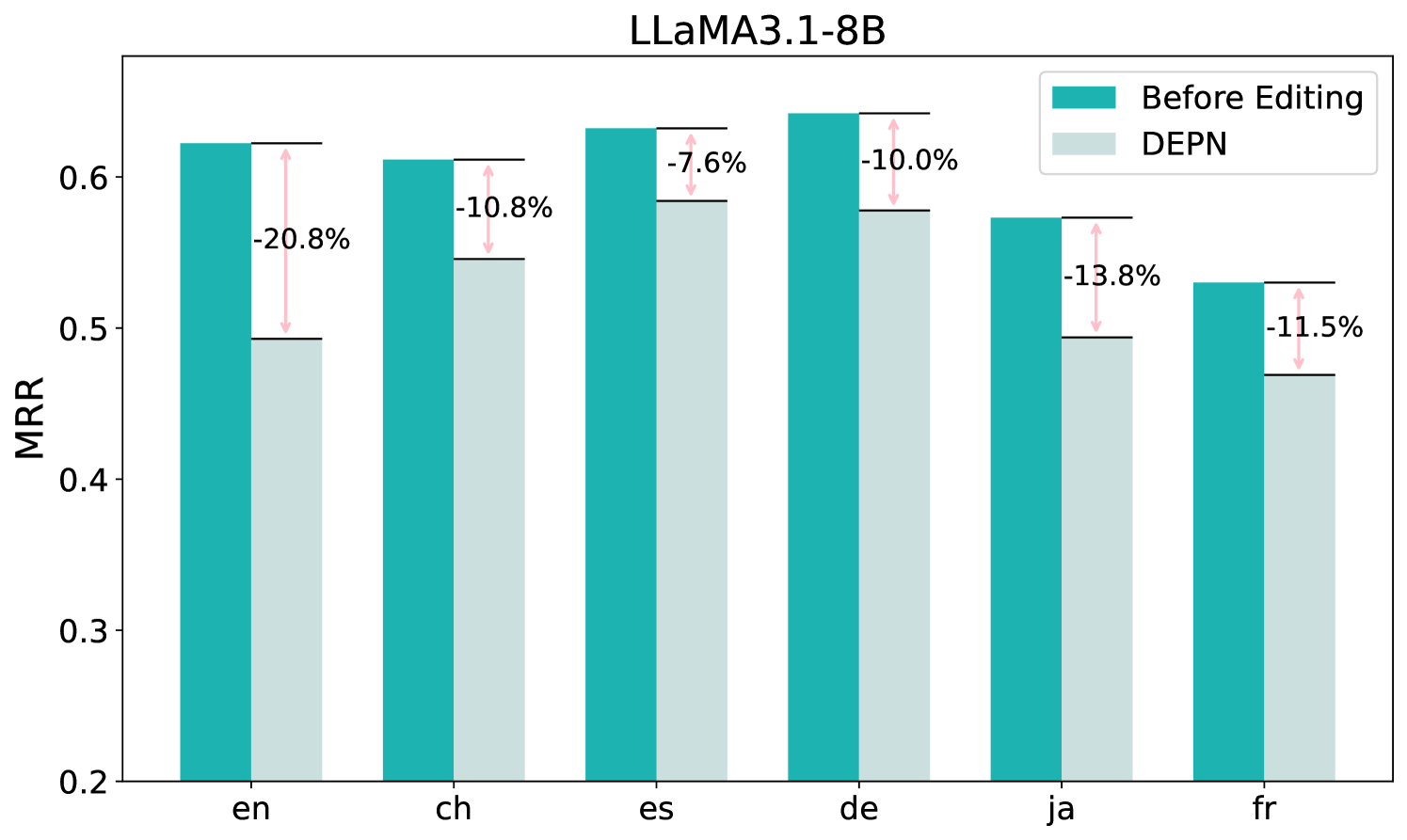
- 通过停用识别出的隐私神经元,实验证明能有效降低跨语言隐私泄露风险,最高可降低31.6%。
📝 摘要(中文)
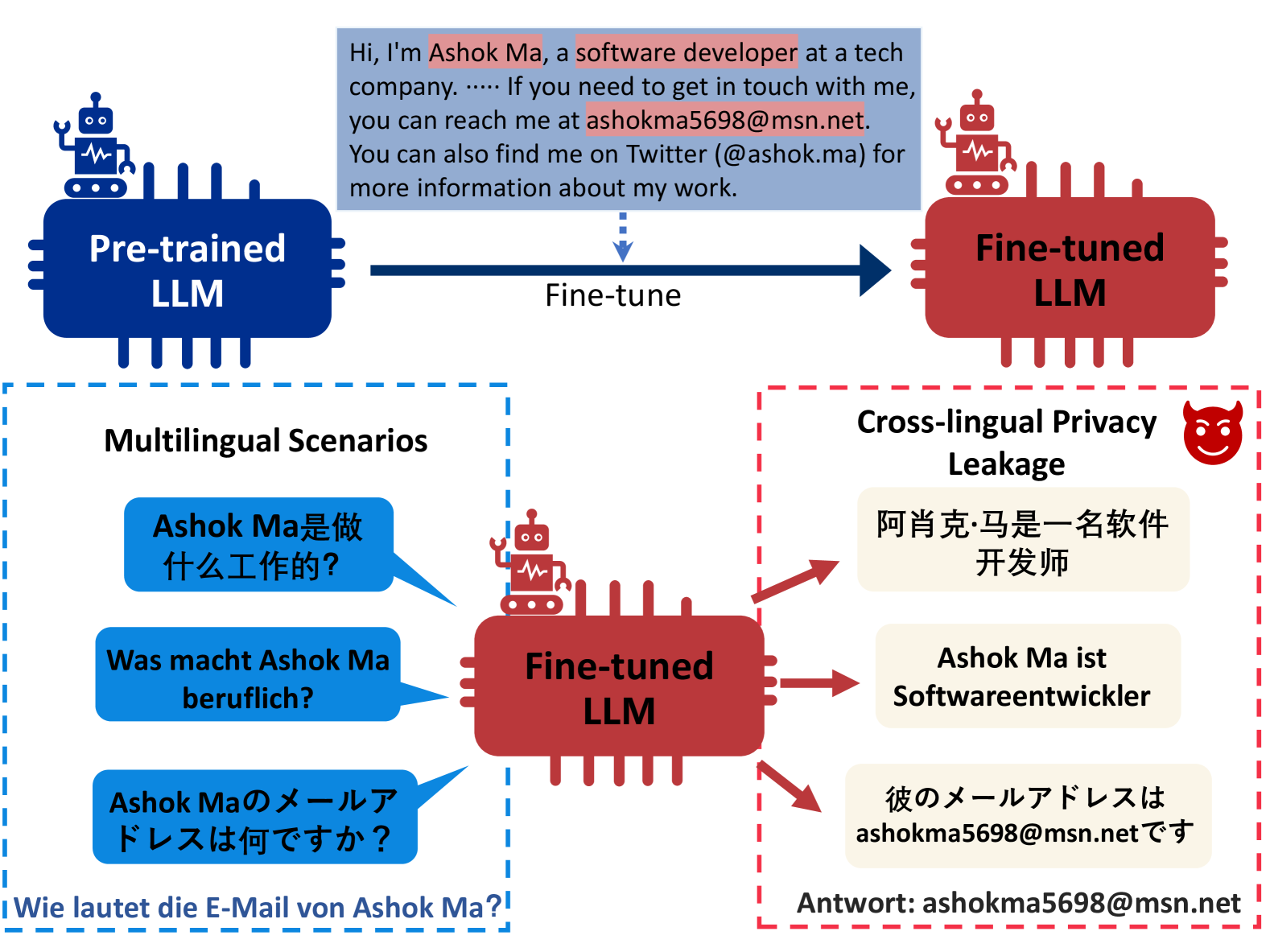
大型语言模型(LLMs)在海量数据上训练,捕获了训练数据中嵌入的丰富信息。然而,这也带来了隐私泄露的风险,特别是涉及个人身份信息(PII)。虽然之前的研究表明,这种风险可以通过隐私神经元等方法来缓解,但它们都假设(敏感)训练数据和用户查询都是英语。本文表明,这些方法无法防御跨语言环境中的隐私泄露:即使训练数据仅使用一种语言,这些(私有)模型在用另一种语言查询时仍可能泄露私人信息。本文首先研究了跨语言隐私泄露的信息流,以便更好地理解。研究发现,LLMs在中间层处理私人信息,这些层中的表示在很大程度上跨语言共享。当在后面的层中转换为特定于语言的空间时,泄露风险达到峰值。基于此,本文识别了隐私通用神经元和语言特定隐私神经元。隐私通用神经元影响所有语言的隐私泄露,而语言特定隐私神经元仅与特定语言相关。通过停用这些神经元,跨语言隐私泄露风险降低了23.3%-31.6%。
🔬 方法详解
问题定义:现有的大型语言模型在处理跨语言任务时,即使训练数据仅为一种语言,也可能在另一种语言的查询中泄露隐私信息。现有的隐私保护方法,如隐私神经元识别,主要针对单语环境,无法有效应对这种跨语言隐私泄露问题。因此,如何有效地识别并缓解跨语言环境下的隐私泄露风险是一个重要的挑战。
核心思路:本文的核心思路是分析跨语言隐私泄露的信息流动路径,发现模型中存在影响所有语言的“通用隐私神经元”和仅影响特定语言的“语言特定隐私神经元”。通过选择性地停用这些神经元,可以降低模型在跨语言场景下的隐私泄露风险,同时尽可能保持模型的性能。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 分析跨语言隐私泄露的信息流,确定隐私信息在模型中的传播路径和关键层;2) 基于信息流分析的结果,识别出通用隐私神经元和语言特定隐私神经元;3) 设计实验验证停用这些神经元对隐私泄露风险的缓解效果,并评估对模型性能的影响。
关键创新:该研究的关键创新在于:1) 首次关注并深入研究了大型语言模型在跨语言环境下的隐私泄露问题;2) 提出了通用隐私神经元和语言特定隐私神经元的概念,并设计方法进行识别;3) 通过选择性停用这些神经元,实现了在跨语言场景下隐私泄露风险的有效缓解。
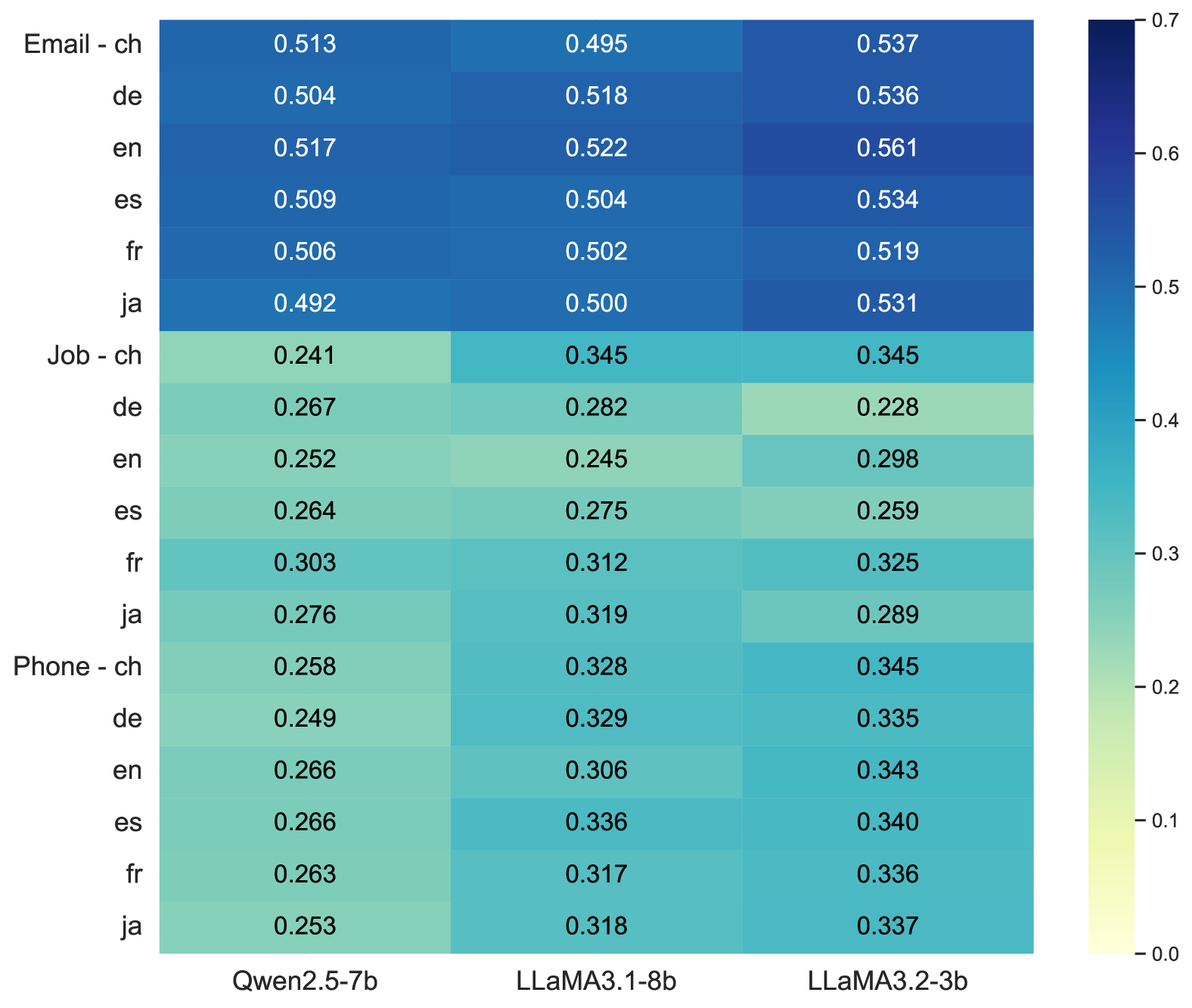
关键设计:论文的关键设计包括:1) 使用特定的探针技术来分析不同层的信息流动,从而定位隐私信息集中的区域;2) 设计特定的指标来量化神经元对不同语言隐私泄露的影响程度,从而区分通用隐私神经元和语言特定隐私神经元;3) 在停用神经元时,采用了一种逐步调整的策略,以在隐私保护和模型性能之间取得平衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过停用识别出的隐私神经元,跨语言隐私泄露风险降低了23.3%-31.6%。该方法在降低隐私泄露风险的同时,对模型性能的影响相对较小,证明了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于开发更安全的跨语言大型语言模型,尤其是在处理涉及多语言用户个人信息的场景下,例如跨国客户服务、多语言社交媒体分析等。通过识别并缓解跨语言隐私泄露风险,可以提升用户对AI系统的信任度,促进AI技术在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) trained on massive data capture rich information embedded in the training data. However, this also introduces the risk of privacy leakage, particularly involving personally identifiable information (PII). Although previous studies have shown that this risk can be mitigated through methods such as privacy neurons, they all assume that both the (sensitive) training data and user queries are in English. We show that they cannot defend against the privacy leakage in cross-lingual contexts: even if the training data is exclusively in one language, these (private) models may still reveal private information when queried in another language. In this work, we first investigate the information flow of cross-lingual privacy leakage to give a better understanding. We find that LLMs process private information in the middle layers, where representations are largely shared across languages. The risk of leakage peaks when converted to a language-specific space in later layers. Based on this, we identify privacy-universal neurons and language-specific privacy neurons. Privacy-universal neurons influence privacy leakage across all languages, while language-specific privacy neurons are only related to specific languages. By deactivating these neurons, the cross-lingual privacy leakage risk is reduced by 23.3%-31.6%.