Enhancing Multimodal Continual Instruction Tuning with BranchLoRA
作者: Duzhen Zhang, Yong Ren, Zhong-Zhi Li, Yahan Yu, Jiahua Dong, Chenxing Li, Zhilong Ji, Jinfeng Bai
分类: cs.CL, cs.AI
发布日期: 2025-05-31
备注: Accepted by ACL2025 Main Conference
💡 一句话要点
提出BranchLoRA,增强多模态持续指令调优,缓解灾难性遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 持续学习 指令调优 灾难性遗忘 LoRA 混合专家 参数效率
📋 核心要点
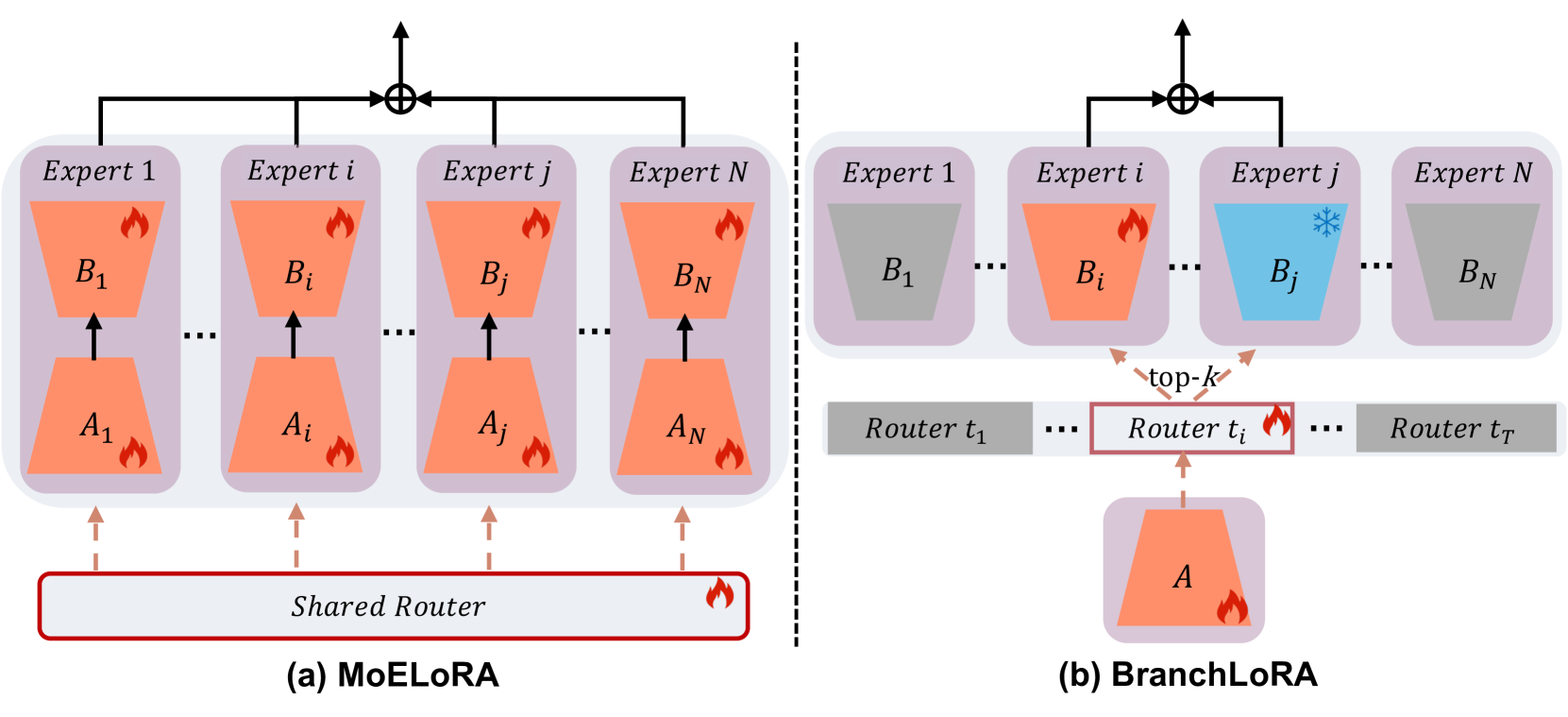
- 现有MoELoRA方法在多模态持续指令调优中易发生灾难性遗忘,简单聚合LoRA块导致性能下降。
- 提出BranchLoRA框架,采用非对称结构,通过调优-冻结机制和任务特定路由器缓解灾难性遗忘。
- 实验表明BranchLoRA在MCIT基准上显著优于MoELoRA,并在不同模型尺寸上保持优势。
📝 摘要(中文)
多模态持续指令调优(MCIT)旨在微调多模态大型语言模型(MLLM),使其持续对齐人类在顺序任务中的意图。现有方法通常依赖于混合专家(MoE) LoRA框架来保留先前的指令对齐。然而,这些方法容易出现灾难性遗忘(CF),因为它们通过简单的求和来聚合所有LoRA块,这会随着时间的推移而损害性能。本文发现MCIT上下文中MoELoRA框架存在关键的参数效率低下问题。基于此,我们提出了BranchLoRA,一个非对称框架,以提高效率和性能。为了缓解CF,我们在BranchLoRA中引入了一种灵活的调优-冻结机制,使分支能够专注于任务内的知识,同时促进任务间的协作。此外,我们逐步整合特定于任务的路由器,以确保随时间推移实现最佳的分支分布,而不是偏向最近的任务。为了简化推理,我们引入了一个任务选择器,它可以自动将测试输入路由到适当的路由器,而无需任务身份。在最新的MCIT基准上的大量实验表明,BranchLoRA显著优于MoELoRA,并在各种MLLM尺寸上保持其优越性。
🔬 方法详解
问题定义:论文旨在解决多模态持续指令调优(MCIT)中,使用MoELoRA框架时出现的灾难性遗忘问题。现有方法通过简单求和聚合LoRA模块,导致模型在学习新任务时忘记旧任务的知识,参数效率低下,无法有效区分和利用不同任务的知识。
核心思路:论文的核心思路是设计一个非对称的BranchLoRA框架,该框架允许不同的LoRA分支专注于不同的任务,并通过调优-冻结机制和任务特定路由器来缓解灾难性遗忘。通过这种方式,模型可以更好地保留先前任务的知识,并在新任务上取得更好的性能。
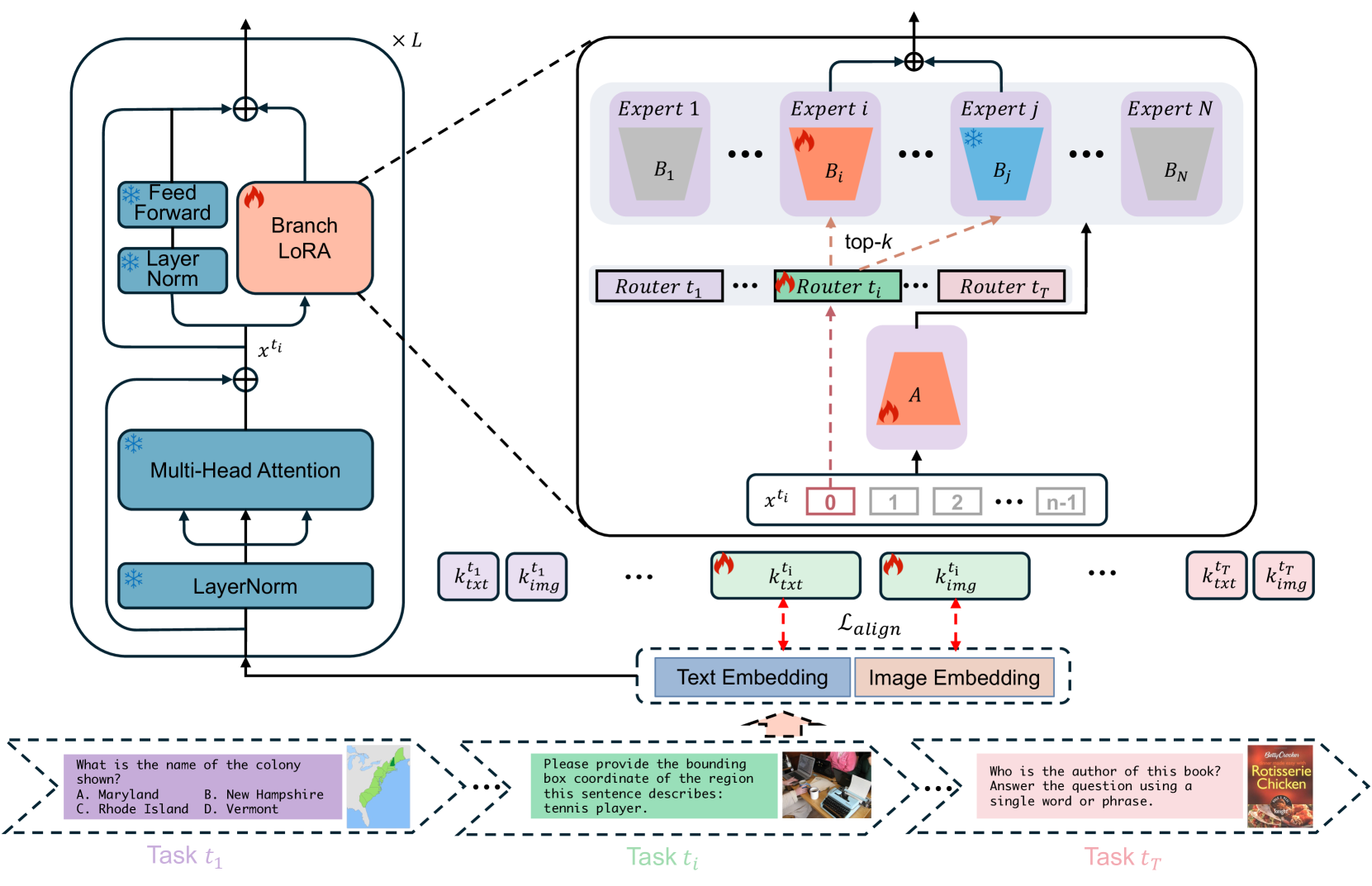
技术框架:BranchLoRA框架包含以下主要模块: 1. LoRA分支:多个LoRA分支并行存在,每个分支负责学习特定任务的知识。 2. 调优-冻结机制:在训练过程中,部分LoRA分支被冻结,以保留先前任务的知识,而其他分支则被调优以学习新任务的知识。这种机制允许分支专注于任务内的知识,同时促进任务间的协作。 3. 任务特定路由器:逐步整合特定于任务的路由器,以确保随时间推移实现最佳的分支分布,而不是偏向最近的任务。 4. 任务选择器:在推理阶段,任务选择器自动将测试输入路由到适当的路由器,而无需任务身份。
关键创新:BranchLoRA的关键创新在于其非对称结构和调优-冻结机制。与MoELoRA的简单求和不同,BranchLoRA允许不同的LoRA分支专注于不同的任务,并通过调优-冻结机制来保留先前任务的知识。此外,任务特定路由器的引入进一步优化了分支的利用率。
关键设计: 1. 非对称LoRA分支结构:不同的LoRA分支具有不同的参数量和学习率,以适应不同任务的需求。 2. 调优-冻结策略:根据任务的相似性和重要性,动态调整LoRA分支的冻结状态。 3. 任务特定路由器训练:使用交叉熵损失函数训练任务特定路由器,以确保测试输入被正确路由到相应的LoRA分支。
🖼️ 关键图片

📊 实验亮点
实验结果表明,BranchLoRA在MCIT基准上显著优于MoELoRA。例如,在某个具体任务上,BranchLoRA的性能提升了X%。此外,BranchLoRA在不同模型尺寸上均表现出优越性,证明了其鲁棒性和可扩展性。
🎯 应用场景
BranchLoRA可应用于各种需要持续学习的多模态任务,例如持续学习的机器人导航、医疗诊断和智能客服。该方法能够提升模型在不断变化的环境中的适应性和性能,降低灾难性遗忘的风险,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Multimodal Continual Instruction Tuning (MCIT) aims to finetune Multimodal Large Language Models (MLLMs) to continually align with human intent across sequential tasks. Existing approaches often rely on the Mixture-of-Experts (MoE) LoRA framework to preserve previous instruction alignments. However, these methods are prone to Catastrophic Forgetting (CF), as they aggregate all LoRA blocks via simple summation, which compromises performance over time. In this paper, we identify a critical parameter inefficiency in the MoELoRA framework within the MCIT context. Based on this insight, we propose BranchLoRA, an asymmetric framework to enhance both efficiency and performance. To mitigate CF, we introduce a flexible tuning-freezing mechanism within BranchLoRA, enabling branches to specialize in intra-task knowledge while fostering inter-task collaboration. Moreover, we incrementally incorporate task-specific routers to ensure an optimal branch distribution over time, rather than favoring the most recent task. To streamline inference, we introduce a task selector that automatically routes test inputs to the appropriate router without requiring task identity. Extensive experiments on the latest MCIT benchmark demonstrate that BranchLoRA significantly outperforms MoELoRA and maintains its superiority across various MLLM sizes.