Chain-of-Thought Training for Open E2E Spoken Dialogue Systems
作者: Siddhant Arora, Jinchuan Tian, Hayato Futami, Jee-weon Jung, Jiatong Shi, Yosuke Kashiwagi, Emiru Tsunoo, Shinji Watanabe
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-05-31
备注: Accepted at INTERSPEECH 2025
💡 一句话要点
提出基于思维链(CoT)训练的端到端口语对话系统,提升语义连贯性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 口语对话系统 端到端学习 思维链 多模态学习 预训练模型
📋 核心要点
- 现有端到端口语对话系统需要大规模训练数据,且生成的回复缺乏语义连贯性。
- 利用思维链(CoT)方法,对齐对话数据训练和多模态语言模型的预训练任务。
- 在Switchboard等数据集上验证,仅需300小时数据即可训练,ROUGE-1指标提升超过1.5。
📝 摘要(中文)
本文提出了一种简单而有效的策略,利用思维链(CoT)公式,确保在对话数据上的训练与多模态语言模型(LM)在语音识别(ASR)、文本到语音合成(TTS)和文本LM任务上的预训练紧密对齐。该方法在基线上实现了超过1.5的ROUGE-1改进,成功地在公开的人与人对话数据集上训练了口语对话系统,并且计算效率足够高,可以在仅300小时的公开人与人对话数据(如Switchboard)上进行训练。我们将公开发布我们的模型和训练代码。
🔬 方法详解
问题定义:现有端到端口语对话系统虽然具备端到端可微性和捕获非音素信息的能力,但通常需要大量的训练数据,并且生成的回复在语义上缺乏连贯性。这限制了它们在实际应用中的可行性,尤其是在数据资源有限的情况下。
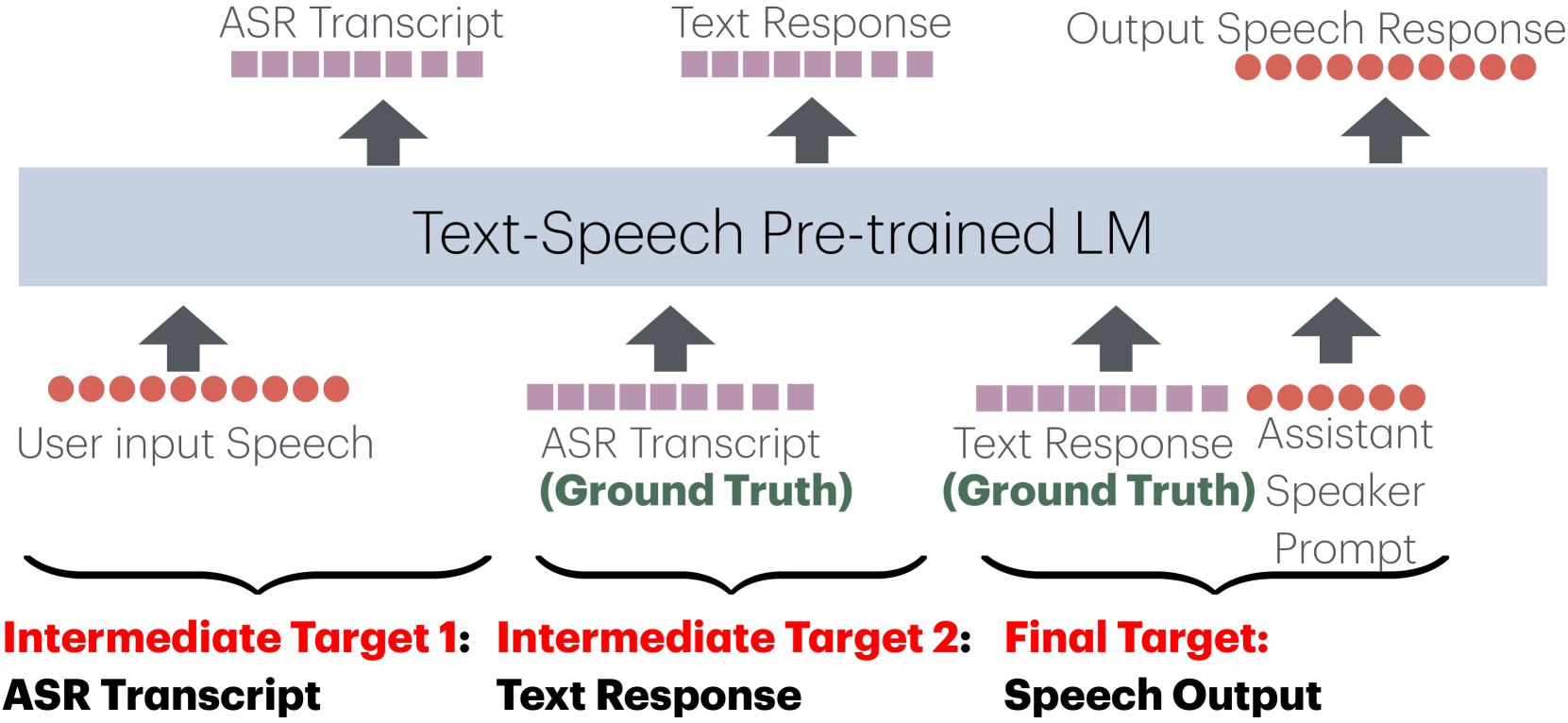
核心思路:本文的核心思路是利用思维链(Chain-of-Thought, CoT)的方法,将对话生成过程分解为一系列中间步骤,从而引导模型学习更具结构化和连贯性的对话策略。通过这种方式,可以更好地利用预训练多模态语言模型的知识,并减少对大规模对话数据的依赖。
技术框架:整体框架包括一个端到端的多模态语言模型,该模型在语音识别(ASR)、文本到语音合成(TTS)和文本语言模型(LM)等任务上进行了预训练。在对话训练阶段,引入CoT,强制模型生成中间推理步骤,例如意图识别、槽填充等,然后再生成最终回复。整个过程仍然是端到端可微的,允许模型在训练过程中优化所有模块。
关键创新:最重要的创新点在于将思维链(CoT)的概念引入到端到端口语对话系统的训练中。与传统的直接生成回复的方法不同,CoT方法鼓励模型显式地进行推理,从而提高生成回复的语义连贯性和可解释性。这种方法特别适用于数据资源有限的场景,因为它可以更好地利用预训练模型的知识。
关键设计:关键设计包括CoT的具体形式,例如,可以要求模型首先识别用户意图,然后填充相关的槽位,最后生成回复。损失函数的设计也至关重要,需要同时考虑最终回复的质量和中间推理步骤的准确性。此外,模型的架构选择也需要考虑多模态信息的融合,例如,可以使用Transformer结构来处理语音和文本输入。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Switchboard等公开数据集上,该方法仅使用300小时的训练数据,即可在ROUGE-1指标上获得超过1.5的显著提升。这表明该方法在数据资源有限的情况下,能够有效地提高口语对话系统的性能,并生成更具语义连贯性的回复。
🎯 应用场景
该研究成果可应用于各种口语对话系统,例如智能客服、语音助手、智能家居控制等。通过提高对话的语义连贯性和减少对大规模数据的依赖,可以降低部署成本,并提升用户体验。未来,该方法有望扩展到更复杂的对话场景,例如多轮对话、个性化对话等。
📄 摘要(原文)
Unlike traditional cascaded pipelines, end-to-end (E2E) spoken dialogue systems preserve full differentiability and capture non-phonemic information, making them well-suited for modeling spoken interactions. However, existing E2E approaches often require large-scale training data and generates responses lacking semantic coherence. We propose a simple yet effective strategy leveraging a chain-of-thought (CoT) formulation, ensuring that training on conversational data remains closely aligned with the multimodal language model (LM)'s pre-training on speech recognition~(ASR), text-to-speech synthesis (TTS), and text LM tasks. Our method achieves over 1.5 ROUGE-1 improvement over the baseline, successfully training spoken dialogue systems on publicly available human-human conversation datasets, while being compute-efficient enough to train on just 300 hours of public human-human conversation data, such as the Switchboard. We will publicly release our models and training code.