Measuring Faithfulness and Abstention: An Automated Pipeline for Evaluating LLM-Generated 3-ply Case-Based Legal Arguments
作者: Li Zhang, Morgan Gray, Jaromir Savelka, Kevin D. Ashley
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-31 (更新: 2025-06-03)
备注: 11 pages, 7th Workshop on Automated Semantic Analysis of Information in Legal Text @ ICAIL 2025, 16 June 2025, Chicago, IL
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出自动化评估流程,用于评估LLM生成3层案例法律论证的忠实性和克制能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 法律论证生成 自动化评估 忠实性 克制 因子利用 幻觉
📋 核心要点
- 现有方法难以有效评估LLM在法律论证生成中出现的幻觉、因子利用不足和缺乏克制等问题。
- 提出一种自动化评估流程,利用外部LLM提取因子并与ground-truth进行比较,从而评估LLM的忠实性和克制能力。
- 实验表明,LLM在避免幻觉方面表现良好,但在因子利用和克制方面存在不足,尤其是在缺乏共同因子时容易生成虚假论证。
📝 摘要(中文)
大型语言模型(LLM)在复杂的法律任务(如论证生成)中展现出潜力,但其可靠性仍然令人担忧。本文在评估LLM生成3层法律论证的初步人工评估工作基础上,引入了一种自动化流程来评估LLM在此任务上的性能,特别关注忠实性(不存在幻觉)、因子利用和适当的克制。我们将幻觉定义为生成输入案例材料中不存在的因子,将克制定义为模型在被指示且不存在事实依据时避免生成论证的能力。我们的自动化方法采用外部LLM从生成的论证中提取因子,并将其与输入案例三元组(当前案例和两个先例案例)中提供的ground-truth因子进行比较。我们评估了八个不同的LLM在三个难度递增的测试上的表现:1)生成标准的3层论证,2)生成具有交换先例角色的论证,3)识别由于缺乏共享因子而无法生成论证并进行克制。我们的研究结果表明,虽然当前的LLM在可行的论证生成测试(测试1和2)中避免幻觉方面达到了很高的准确率(超过90%),但它们通常未能充分利用案例中存在的全部相关因子。关键的是,在克制测试(测试3)中,大多数模型未能遵循停止指令,而是生成了虚假的论证,尽管缺乏共同因子。这种自动化流程提供了一种可扩展的方法来评估这些关键的LLM行为,突出了在可靠部署到法律环境中之前,需要在因子利用和强大的克制能力方面进行改进。
🔬 方法详解
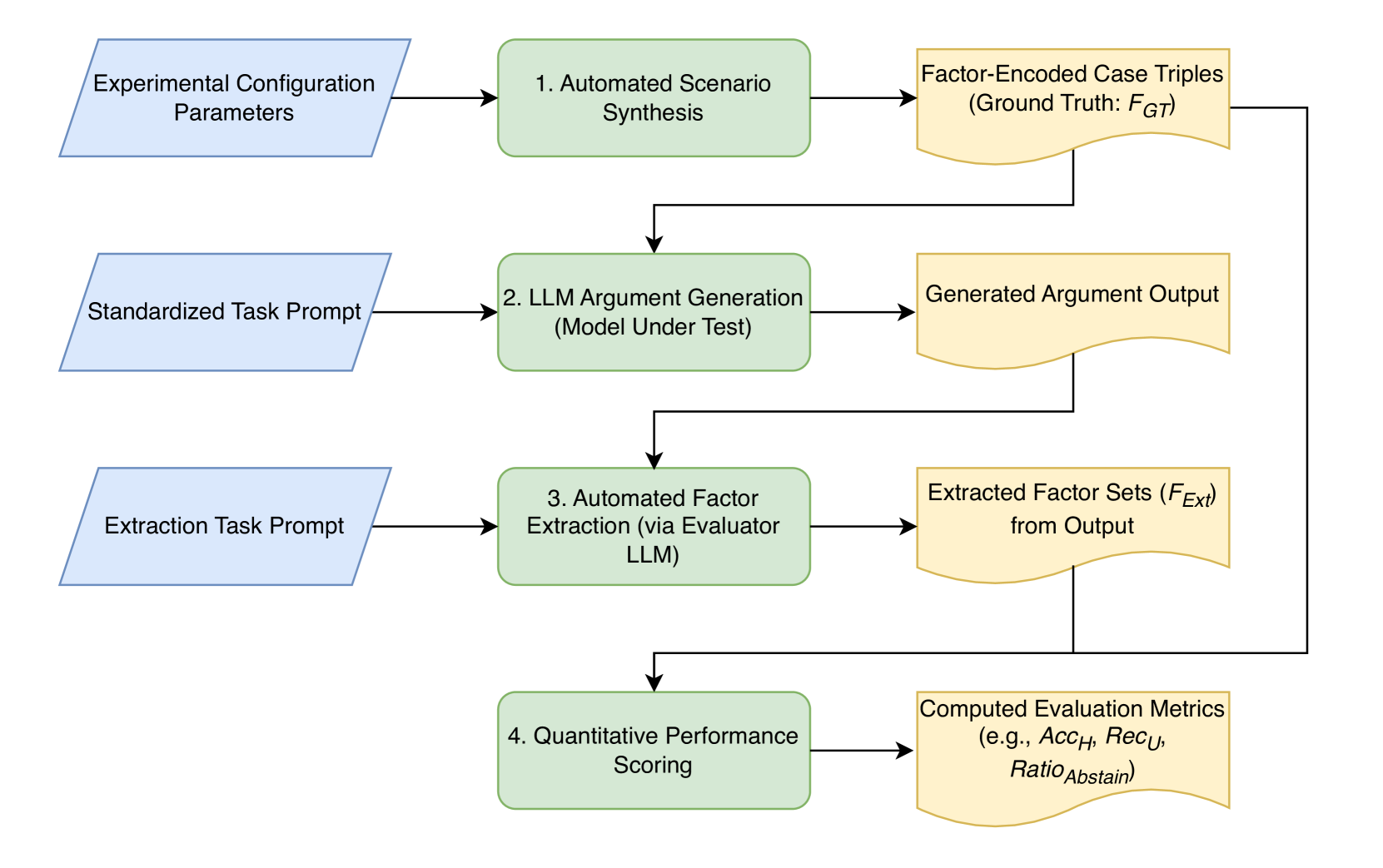
问题定义:论文旨在解决如何自动且有效地评估大型语言模型(LLM)在生成三层案例法律论证时的可靠性问题。现有的评估方法主要依赖于人工评估,成本高昂且难以扩展。此外,现有方法难以量化LLM在论证生成过程中出现的幻觉(生成不存在的事实)、因子利用不足(未能充分利用案例中的相关信息)以及缺乏克制(在不应生成论证时仍然生成)等问题。
核心思路:论文的核心思路是构建一个自动化评估流程,该流程利用另一个LLM作为评估器,从LLM生成的论证中提取关键因子,并将其与ground-truth因子进行比较,从而量化LLM的忠实性、因子利用率和克制能力。这种方法避免了人工评估的成本和主观性,并能够大规模地评估LLM的性能。
技术框架:该自动化评估流程主要包含以下几个阶段:1) 输入案例三元组(当前案例和两个先例案例)给待评估的LLM;2) LLM生成三层法律论证;3) 使用外部LLM(评估器)从生成的论证中提取因子;4) 将提取的因子与ground-truth因子进行比较,计算忠实性、因子利用率和克制能力等指标。该流程包含三个测试:标准论证生成、交换先例角色论证生成和克制测试。
关键创新:该论文最重要的技术创新点在于提出了一个完全自动化的评估流程,用于评估LLM在生成法律论证时的可靠性。与传统的人工评估方法相比,该方法具有更高的效率和可扩展性。此外,该方法还能够量化LLM在幻觉、因子利用和克制等方面的表现,为改进LLM的性能提供了有价值的反馈。
关键设计:论文的关键设计包括:1) 使用外部LLM作为评估器,避免了人工评估的主观性;2) 设计了三个难度递增的测试,全面评估LLM的论证生成能力;3) 定义了明确的指标,用于量化LLM的忠实性、因子利用率和克制能力。评估器LLM的选择和prompt工程是影响评估结果的关键因素,但论文中没有详细说明具体选择和prompt设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前LLM在避免幻觉方面表现良好(准确率超过90%),但在因子利用和克制方面存在明显不足。尤其是在克制测试中,大多数模型未能遵循指令停止生成论证,而是生成了虚假论证。这表明,在将LLM应用于法律领域之前,需要对其因子利用和克制能力进行进一步的改进。
🎯 应用场景
该研究成果可应用于法律人工智能领域,用于评估和改进LLM在法律论证生成、案例分析和法律咨询等方面的应用。通过自动化评估,可以更高效地筛选和优化LLM,提高其在法律领域的可靠性和实用性。未来,该方法可以扩展到其他需要高可靠性的领域,如医疗诊断和金融风险评估。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate potential in complex legal tasks like argument generation, yet their reliability remains a concern. Building upon pilot work assessing LLM generation of 3-ply legal arguments using human evaluation, this paper introduces an automated pipeline to evaluate LLM performance on this task, specifically focusing on faithfulness (absence of hallucination), factor utilization, and appropriate abstention. We define hallucination as the generation of factors not present in the input case materials and abstention as the model's ability to refrain from generating arguments when instructed and no factual basis exists. Our automated method employs an external LLM to extract factors from generated arguments and compares them against the ground-truth factors provided in the input case triples (current case and two precedent cases). We evaluated eight distinct LLMs on three tests of increasing difficulty: 1) generating a standard 3-ply argument, 2) generating an argument with swapped precedent roles, and 3) recognizing the impossibility of argument generation due to lack of shared factors and abstaining. Our findings indicate that while current LLMs achieve high accuracy (over 90%) in avoiding hallucination on viable argument generation tests (Tests 1 & 2), they often fail to utilize the full set of relevant factors present in the cases. Critically, on the abstention test (Test 3), most models failed to follow instructions to stop, instead generating spurious arguments despite the lack of common factors. This automated pipeline provides a scalable method for assessing these crucial LLM behaviors, highlighting the need for improvements in factor utilization and robust abstention capabilities before reliable deployment in legal settings. Link: https://lizhang-aiandlaw.github.io/An-Automated-Pipeline-for-Evaluating-LLM-Generated-3-ply-Case-Based-Legal-Arguments/