GuideX: Guided Synthetic Data Generation for Zero-Shot Information Extraction
作者: Neil De La Fuente, Oscar Sainz, Iker García-Ferrero, Eneko Agirre
分类: cs.CL
发布日期: 2025-05-31
备注: ACL Findings 2025
💡 一句话要点
GuideX:引导式合成数据生成,用于零样本信息抽取
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息抽取 零样本学习 合成数据生成 领域泛化 大型语言模型
📋 核心要点
- 现有信息抽取系统依赖于领域特定的标注数据,成本高昂且难以泛化到新领域。
- GUIDEX通过自动生成领域相关的合成数据,提升模型在零样本信息抽取任务中的泛化能力。
- 实验表明,GUIDEX在多个NER基准测试中显著提升了模型性能,无需或仅需少量人工标注。
📝 摘要(中文)
信息抽取(IE)系统传统上是领域特定的,需要昂贵的适配过程,包括专家模式设计、数据标注和模型训练。虽然大型语言模型在零样本IE中显示出潜力,但在标签定义不同的未见领域中,性能会显著下降。本文介绍了一种新方法GUIDEX,它可以自动定义领域特定的模式,推断指南,并生成合成标记实例,从而实现更好的跨领域泛化。使用GUIDEX微调Llama 3.1在七个零样本命名实体识别基准测试中创下了新的state-of-the-art。与之前的方法相比,使用GUIDEX训练的模型在没有人工标注数据的情况下获得了高达7 F1的提升,并且在与人工标注数据结合使用时,F1值提高了近2。在GUIDEX上训练的模型表现出对复杂、领域特定标注模式的增强理解。代码、模型和合成数据集可在neilus03.github.io/guidex.com上找到。
🔬 方法详解
问题定义:现有的信息抽取系统通常需要针对特定领域进行定制,这涉及到专家设计模式、人工标注数据以及模型训练等多个环节,成本高昂。即使是大型语言模型,在面对标签定义不同的新领域时,其零样本信息抽取性能也会显著下降。因此,如何提升信息抽取系统在未见领域中的泛化能力是一个关键问题。
核心思路:GUIDEX的核心思路是利用大型语言模型自动生成领域相关的合成数据,从而提升模型在零样本场景下的泛化能力。具体来说,GUIDEX首先自动定义领域特定的模式,然后推断标注指南,最后生成合成的标注实例。通过在这些合成数据上进行训练,模型可以更好地理解和适应新的领域。
技术框架:GUIDEX主要包含以下几个阶段:1) 领域模式定义:利用大型语言模型自动生成领域相关的实体类型和关系类型。2) 标注指南推断:基于定义的领域模式,利用大型语言模型生成详细的标注指南,明确每个实体类型和关系类型的定义和标注规则。3) 合成数据生成:根据标注指南,利用大型语言模型生成带有标注的合成数据。4) 模型训练:使用生成的合成数据微调大型语言模型,提升其在零样本信息抽取任务中的性能。
关键创新:GUIDEX的关键创新在于其完全自动化地生成领域特定合成数据的能力。与传统方法需要人工设计模式和标注数据不同,GUIDEX可以自动完成这些步骤,大大降低了信息抽取系统的开发成本和时间。此外,GUIDEX生成的合成数据能够更好地反映领域特定的标注模式,从而提升了模型的泛化能力。
关键设计:GUIDEX使用Llama 3.1作为基础模型,并对其进行微调。在合成数据生成阶段,GUIDEX采用了多种策略来保证数据的质量和多样性,例如使用不同的prompt来生成不同的实例,以及对生成的数据进行过滤和清洗。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
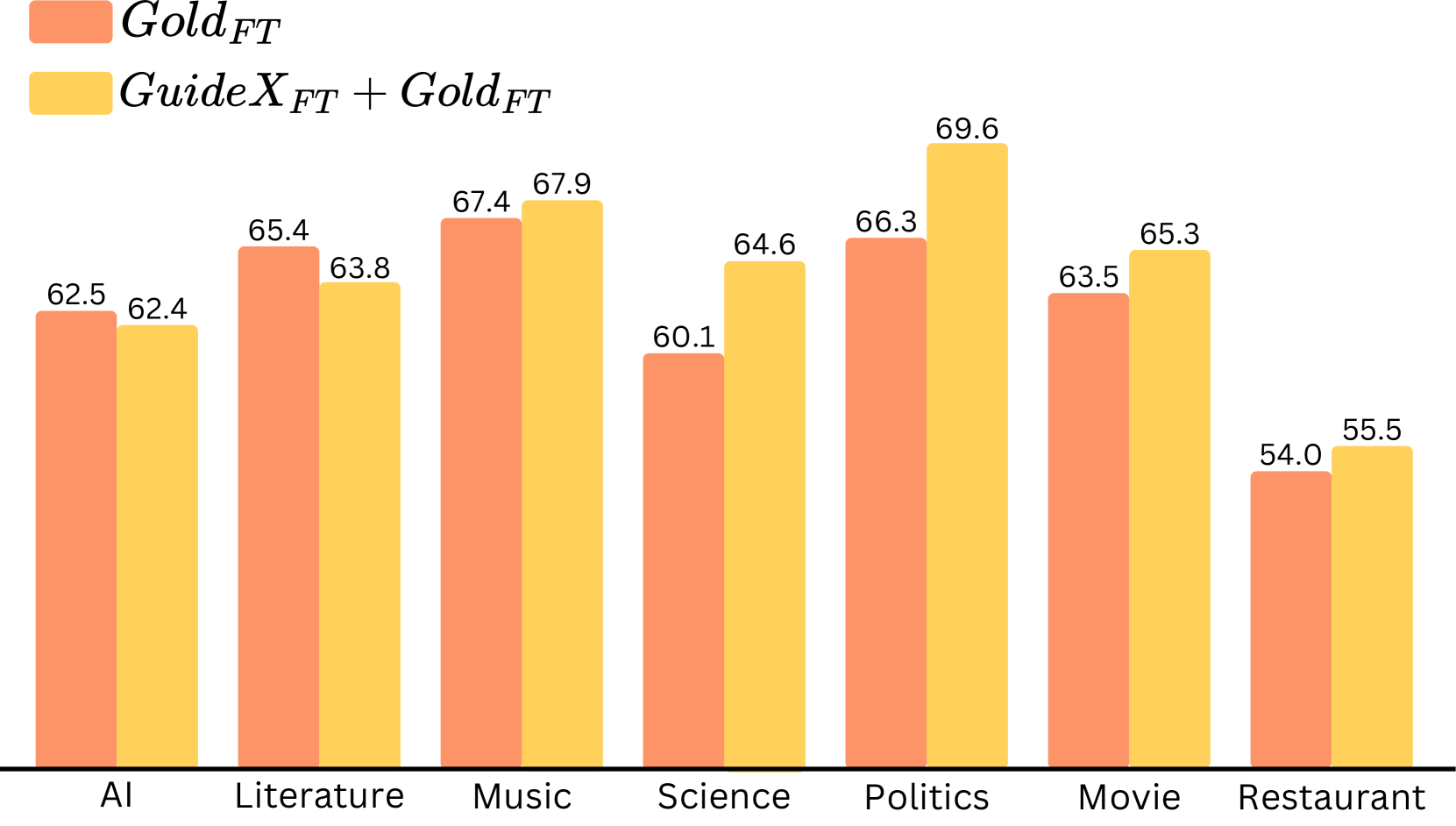


📊 实验亮点
实验结果表明,使用GUIDEX微调Llama 3.1在七个零样本命名实体识别基准测试中创下了新的state-of-the-art。与之前的方法相比,使用GUIDEX训练的模型在没有人工标注数据的情况下获得了高达7 F1的提升,并且在与人工标注数据结合使用时,F1值提高了近2。这些结果表明GUIDEX能够有效地提升模型在零样本信息抽取任务中的性能。
🎯 应用场景
GUIDEX在信息抽取领域具有广泛的应用前景。它可以用于快速构建针对特定领域的零样本信息抽取系统,例如金融、医疗、法律等领域。此外,GUIDEX还可以用于数据增强,提升现有信息抽取系统的性能。该研究有望降低信息抽取系统的开发成本,加速其在各个领域的应用。
📄 摘要(原文)
Information Extraction (IE) systems are traditionally domain-specific, requiring costly adaptation that involves expert schema design, data annotation, and model training. While Large Language Models have shown promise in zero-shot IE, performance degrades significantly in unseen domains where label definitions differ. This paper introduces GUIDEX, a novel method that automatically defines domain-specific schemas, infers guidelines, and generates synthetically labeled instances, allowing for better out-of-domain generalization. Fine-tuning Llama 3.1 with GUIDEX sets a new state-of-the-art across seven zeroshot Named Entity Recognition benchmarks. Models trained with GUIDEX gain up to 7 F1 points over previous methods without humanlabeled data, and nearly 2 F1 points higher when combined with it. Models trained on GUIDEX demonstrate enhanced comprehension of complex, domain-specific annotation schemas. Code, models, and synthetic datasets are available at neilus03.github.io/guidex.com