Social Construction of Urban Space: Using LLMs to Identify Neighborhood Boundaries From Craigslist Ads
作者: Adam Visokay, Ruth Bagley, Ian Kennedy, Chris Hess, Kyle Crowder, Rob Voigt, Denis Peskoff
分类: cs.CL
发布日期: 2025-05-31 (更新: 2026-01-06)
备注: 8 pages, 3 figures, 4 tables
💡 一句话要点
利用大型语言模型从Craigslist广告中识别城市社区边界,揭示城市空间的社会构建。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 城市空间 社会构建 大型语言模型 社区边界 自然语言处理
📋 核心要点
- 现有方法难以捕捉城市空间社会构建中细微的语言差异和社区边界的模糊性。
- 利用大型语言模型分析租房广告文本,识别社区边界,揭示城市空间社会构建的语言模式。
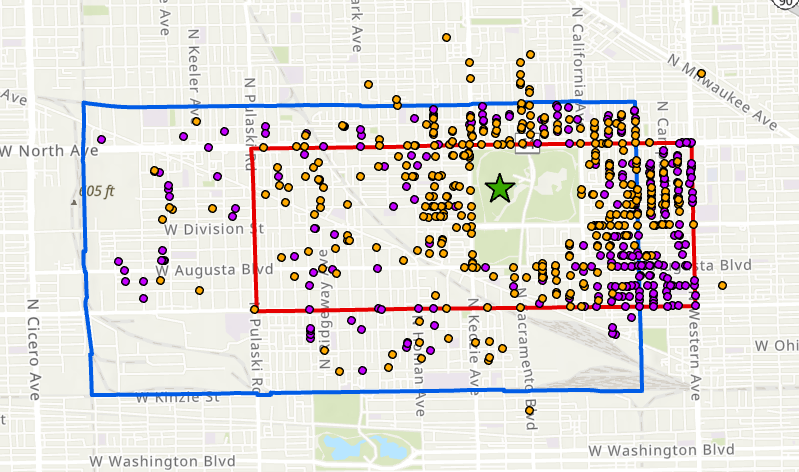
- 通过地理空间分析,发现社区指定冲突、边界房产和声誉洗白等现象,揭示城市空间认知的复杂性。
📝 摘要(中文)
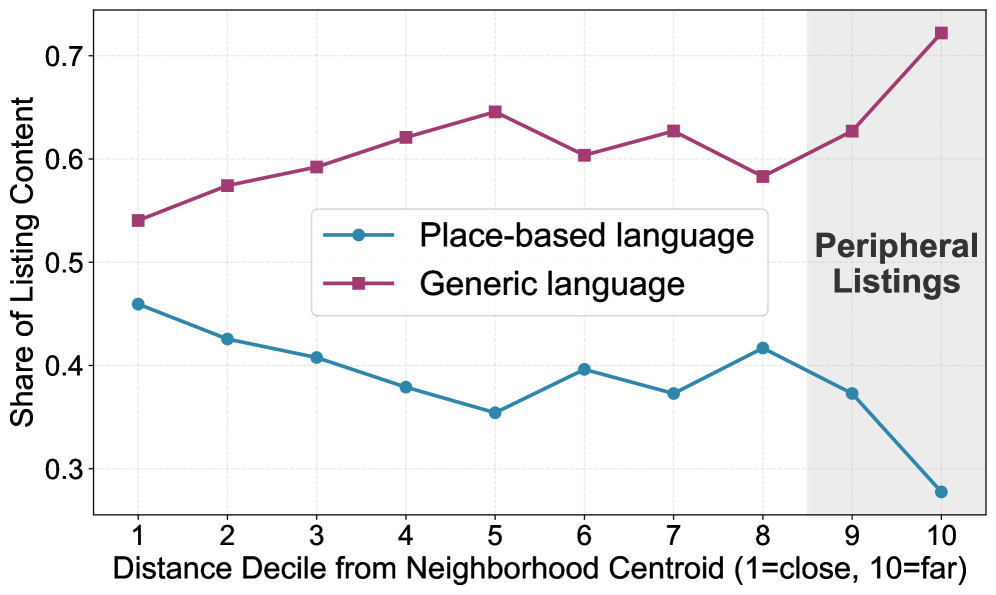
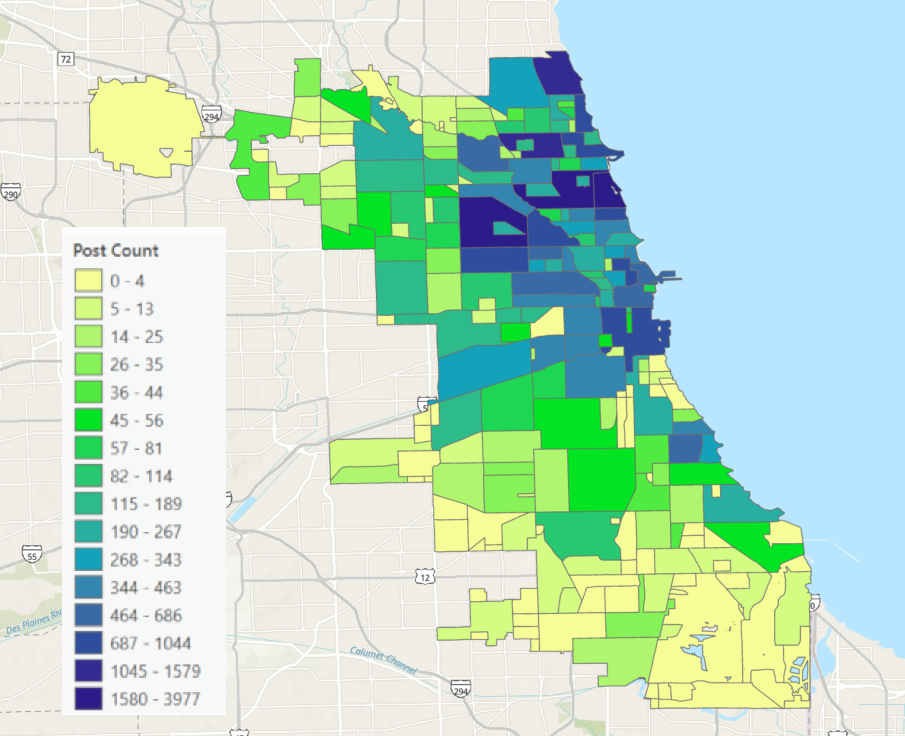
本研究通过分析2018年至2024年芝加哥Craigslist上的租房广告,探讨城市空间如何通过语言进行社会构建。我们考察了房产中介如何描述社区,并识别了机构边界与社区主张之间的不匹配。通过人工和大型语言模型标注,我们根据Craigslist上的非结构化房源信息对其所属社区进行分类。进一步的地理空间分析揭示了三种不同的模式:由于空间定义竞争而导致社区指定冲突的房产、对相邻社区具有有效主张的边界房产,以及通过声称与遥远且理想的社区相关联来“洗白声誉”的房产。通过主题建模,我们识别出与空间位置相关的模式:远离社区中心的房源比位于中心的房源更强调不同的便利设施。自然语言处理技术揭示了城市空间的定义是如何以传统方法所忽视的方式进行争夺的。
🔬 方法详解
问题定义:本研究旨在解决城市空间社会构建中,传统方法难以有效识别和理解社区边界的问题。现有方法,如基于人口普查数据或地理信息的分析,往往忽略了语言在塑造社区认知中的作用,以及社区边界的模糊性和动态性。Craigslist租房广告中蕴含着丰富的社区描述信息,但其非结构化文本给自动分析带来了挑战。
核心思路:本研究的核心思路是利用大型语言模型(LLM)的自然语言理解能力,从Craigslist租房广告的文本中提取社区信息,并结合地理空间分析,揭示城市空间的社会构建过程。通过分析房产中介对社区的描述,识别社区边界的争议和模糊性,以及房产与不同社区的关联模式。
技术框架:研究的整体框架包括以下几个阶段:1) 数据收集:收集2018年至2024年芝加哥Craigslist上的租房广告数据。2) 文本预处理:对广告文本进行清洗和标准化处理。3) 社区标注:使用人工和LLM对广告进行社区标注。4) 地理空间分析:将标注的社区信息与房产的地理位置进行关联,分析社区边界和房产的社区归属模式。5) 主题建模:对广告文本进行主题建模,识别与不同社区相关的语言模式。
关键创新:本研究的关键创新在于:1) 将LLM应用于城市空间社会构建的研究,利用LLM强大的自然语言理解能力,从非结构化文本中提取社区信息。2) 结合地理空间分析和文本分析,揭示城市空间认知的复杂性和动态性。3) 识别了社区指定冲突、边界房产和声誉洗白等现象,为理解城市空间社会构建提供了新的视角。
关键设计:研究中使用的LLM的具体模型未知,但标注过程是关键。研究可能采用了微调或提示工程等技术,以提高LLM在社区识别任务上的准确性。地理空间分析可能使用了核密度估计或空间自相关等方法,以识别社区边界和房产的社区归属模式。主题建模可能使用了LDA或NMF等算法,以识别与不同社区相关的关键词和主题。
🖼️ 关键图片
📊 实验亮点
研究通过分析芝加哥Craigslist租房广告,揭示了三种独特的空间模式:社区指定冲突、边界房产和声誉洗白。主题建模显示,远离社区中心的房源更强调不同的便利设施。这些发现表明,传统的城市空间定义方法可能忽略了语言在塑造社区认知中的重要作用。
🎯 应用场景
该研究成果可应用于城市规划、房地产分析、社会学研究等领域。通过理解城市空间的社会构建过程,可以为城市规划提供更精细化的指导,促进社区融合和社会公平。房地产公司可以利用该研究成果进行市场分析,了解不同社区的价值和吸引力。社会学家可以利用该研究成果研究城市居民的社区认同感和归属感。
📄 摘要(原文)
Rental listings offer a window into how urban space is socially constructed through language. We analyze Chicago Craigslist rental advertisements from 2018 to 2024 to examine how listing agents characterize neighborhoods, identifying mismatches between institutional boundaries and neighborhood claims. Through manual and large language model annotation, we classify unstructured listings from Craigslist according to their neighborhood. Further geospatial analysis reveals three distinct patterns: properties with conflicting neighborhood designations due to competing spatial definitions, border properties with valid claims to adjacent neighborhoods, and "reputation laundering" where listings claim association with distant, desirable neighborhoods. Through topic modeling, we identify patterns that correlate with spatial positioning: listings further from neighborhood centers emphasize different amenities than centrally-located units. Natural language processing techniques reveal how definitions of urban spaces are contested in ways that traditional methods overlook.