CausalAbstain: Enhancing Multilingual LLMs with Causal Reasoning for Trustworthy Abstention
作者: Yuxi Sun, Aoqi Zuo, Wei Gao, Jing Ma
分类: cs.CL, cs.AI
发布日期: 2025-05-31 (更新: 2025-06-03)
备注: Accepted to Association for Computational Linguistics Findings (ACL) 2025
🔗 代码/项目: GITHUB
💡 一句话要点
CausalAbstain:利用因果推理增强多语言LLM的可信拒答能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 因果推理 拒答 知识问答 幻觉 可信AI 反馈选择
📋 核心要点
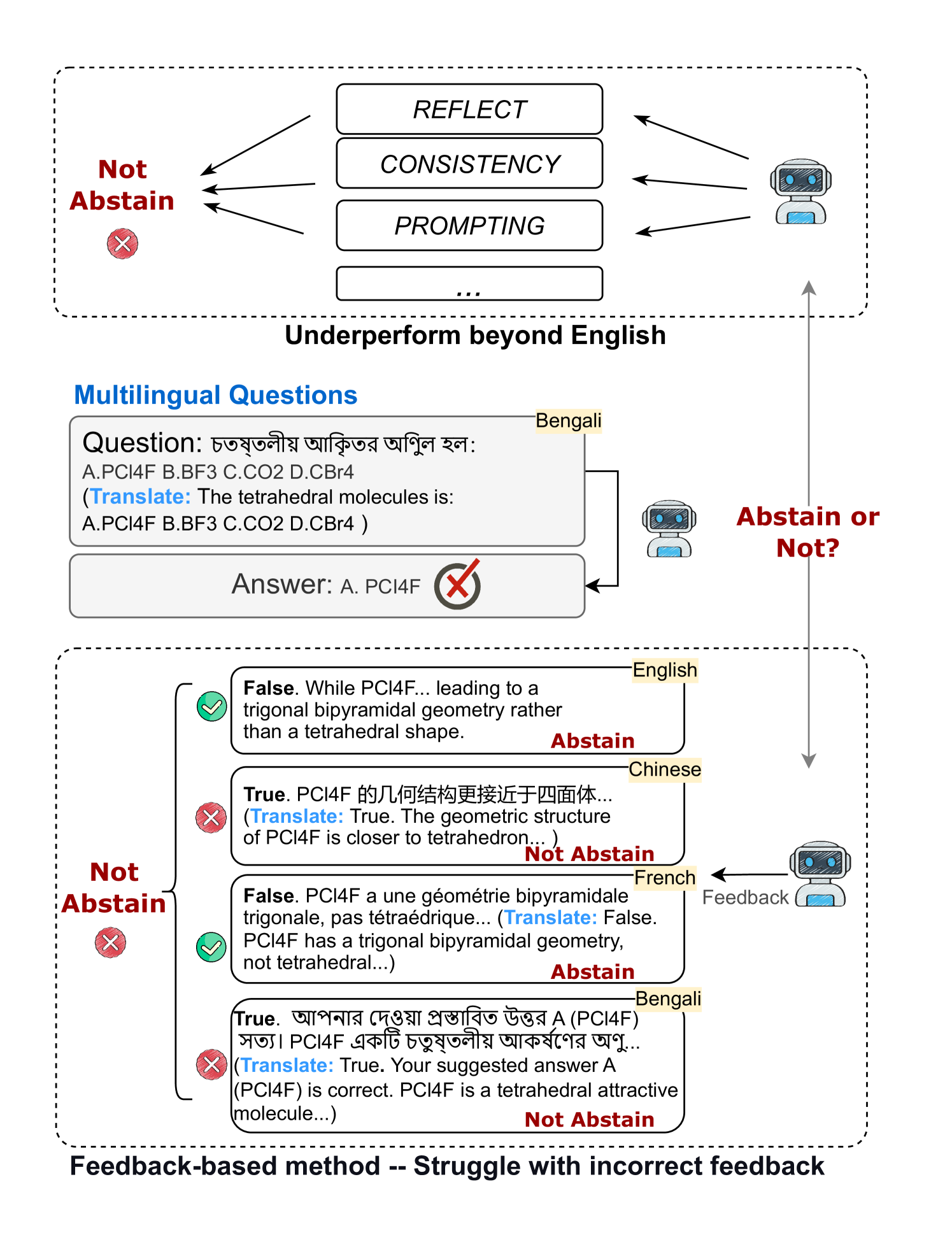
- 现有方法在多语言场景下,依赖LLM生成反馈进行自我反思,易受反馈不准确和偏差的影响。
- CausalAbstain从因果角度出发,使LLM能够判断是否利用多重反馈,并识别最有价值的反馈信息。
- 实验结果表明,CausalAbstain在原生语言和多语言环境下均能有效提升拒答决策的准确性和可解释性。
📝 摘要(中文)
大型语言模型(LLMs)在不同语言之间常常表现出知识差异。鼓励LLMs在面对知识缺口时选择“拒答”是减少多语言环境下幻觉的一种有前景的策略。目前多语言场景下的拒答策略主要依赖于使用LLMs生成多种语言的反馈并进行自我反思。然而,这些方法可能会受到生成反馈中的不准确性和偏差的不利影响。为了解决这个问题,我们从因果角度出发,引入了CausalAbstain,该方法帮助LLMs确定是否利用多个生成的反馈响应,以及如何识别最有用的反馈。大量的实验表明,CausalAbstain有效地选择有用的反馈,并在原生语言(Casual-native)和多语言(Causal-multi)设置中增强了拒答决策的可解释性,在涵盖百科知识和常识知识问答任务的两个基准数据集上优于强大的基线模型。我们的代码和数据已在https://github.com/peachch/CausalAbstain上开源。
🔬 方法详解
问题定义:论文旨在解决多语言LLM在知识不足时产生幻觉的问题。现有方法依赖LLM生成反馈进行自我反思,但生成的反馈可能存在不准确和偏差,导致拒答决策错误。因此,如何有效利用和筛选多语言反馈信息,提升LLM的拒答能力是关键挑战。
核心思路:论文的核心思路是利用因果推理来判断和选择有用的反馈信息。通过建立因果模型,分析不同反馈对最终决策的影响,从而选择最可靠的反馈,并指导LLM做出更合理的拒答决策。这种方法避免了直接依赖LLM生成反馈的固有偏差。
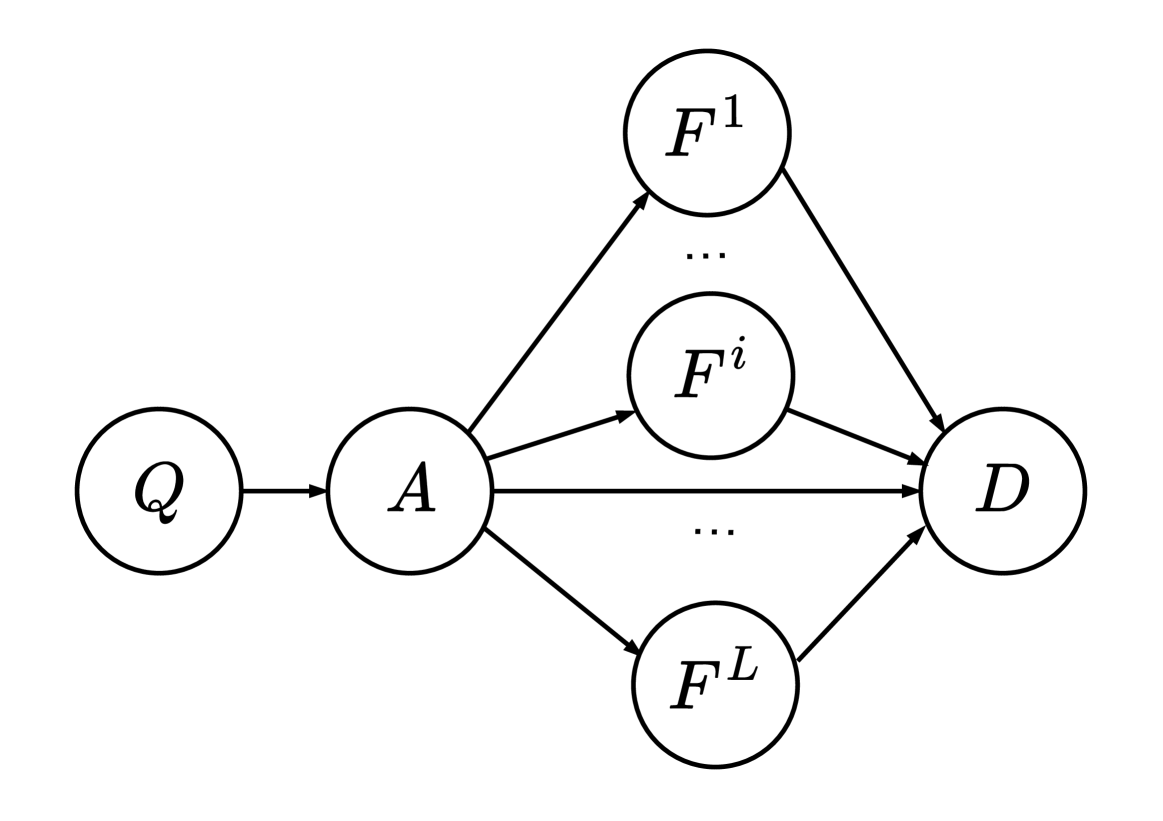
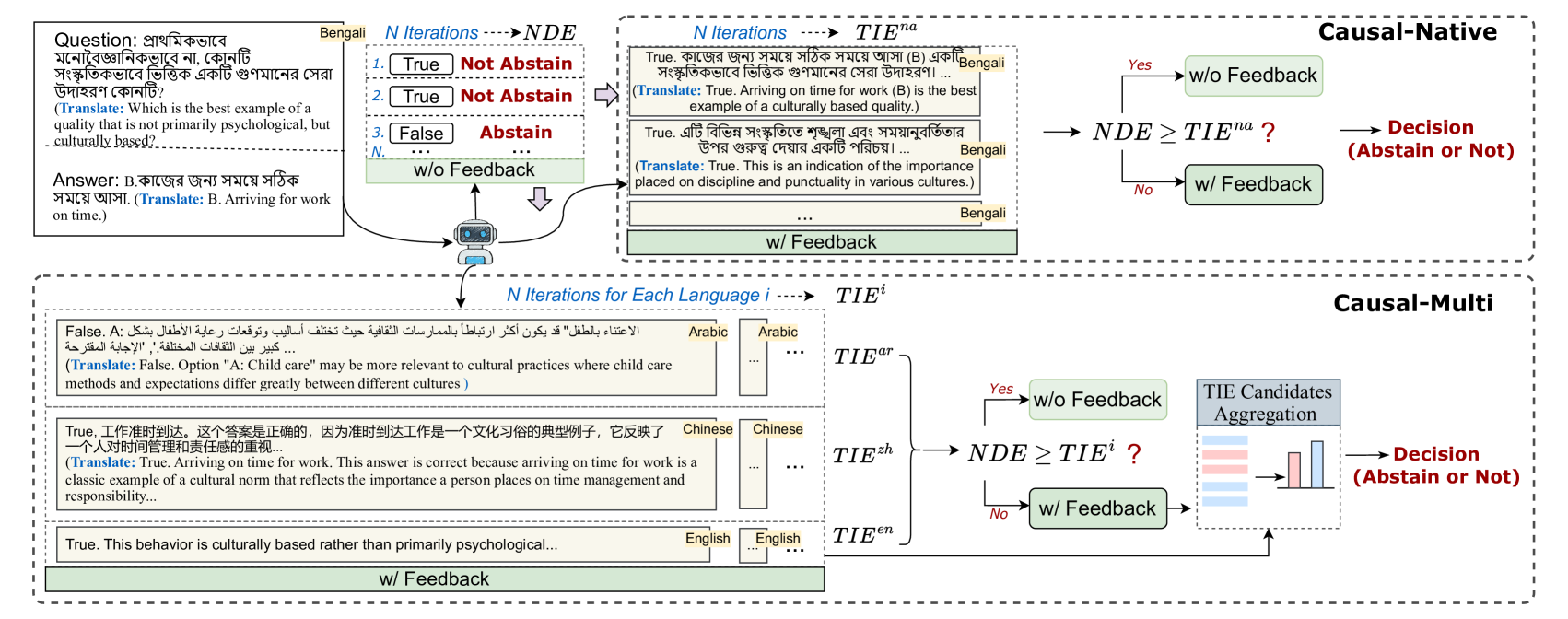
技术框架:CausalAbstain方法主要包含以下几个阶段:1) 多语言反馈生成:使用LLM生成多种语言的反馈信息;2) 因果模型构建:基于生成的反馈,构建因果图,分析不同反馈之间的因果关系;3) 反馈选择:利用因果推理,选择对最终决策影响最大的反馈信息;4) 拒答决策:基于选择的反馈信息,LLM做出最终的拒答决策。
关键创新:该方法最重要的创新点在于引入了因果推理来指导LLM的拒答决策。与现有方法直接依赖LLM生成反馈不同,CausalAbstain通过因果模型分析反馈的可靠性,从而避免了反馈偏差对拒答决策的影响。这种方法提高了拒答决策的准确性和可解释性。
关键设计:具体的因果模型构建方法和推理算法是关键设计。论文可能采用了特定的因果发现算法(例如PC算法或LiNGAM)来构建因果图。此外,如何量化反馈信息对最终决策的影响,以及如何将因果推理的结果融入到LLM的拒答决策过程中,都是需要仔细设计的技术细节。具体的损失函数和参数设置未知,需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CausalAbstain在百科知识和常识知识问答任务上均优于现有基线模型。具体性能数据和提升幅度未知,但摘要中提到CausalAbstain在原生语言和多语言设置中均表现出色,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要多语言LLM提供可靠答案的场景,例如多语言智能客服、跨语言信息检索、全球化知识问答系统等。通过提升LLM的拒答能力,可以减少错误信息的传播,提高用户对LLM的信任度,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) often exhibit knowledge disparities across languages. Encouraging LLMs to \textit{abstain} when faced with knowledge gaps is a promising strategy to reduce hallucinations in multilingual settings. Current abstention strategies for multilingual scenarios primarily rely on generating feedback in various languages using LLMs and performing self-reflection. However, these methods can be adversely impacted by inaccuracies and biases in the generated feedback. To address this, from a causal perspective, we introduce \textit{CausalAbstain}, a method that helps LLMs determine whether to utilize multiple generated feedback responses and how to identify the most useful ones. Extensive experiments demonstrate that \textit{CausalAbstain} effectively selects helpful feedback and enhances abstention decisions with interpretability in both native language (\textsc{Casual-native}) and multilingual (\textsc{Causal-multi}) settings, outperforming strong baselines on two benchmark datasets covering encyclopedic and commonsense knowledge QA tasks. Our code and data are open-sourced at https://github.com/peachch/CausalAbstain.