Auto-Patching: Enhancing Multi-Hop Reasoning in Language Models
作者: Aviv Jan, Dean Tahory, Omer Talmi, Omar Abo Mokh
分类: cs.CL, cs.LG
发布日期: 2025-05-31
备注: 8 pages, 5 figures
💡 一句话要点
提出Auto-Patch以增强语言模型的多跳推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多跳推理 语言模型 动态修补 PatchScopes 智能问答 自然语言处理 深度学习
📋 核心要点
- 现有的大型语言模型在处理多跳推理问题时,往往无法有效链接跨多个推理步骤的信息,导致解题率低下。
- 论文提出的Auto-Patch方法通过动态修补隐藏状态,利用学习到的分类器选择性地修改内部表示,从而提升多跳推理能力。
- 在MuSiQue数据集上的实验结果显示,Auto-Patch的解题率显著提高,达到了23.63%,相较于基线提升了5.18%。
📝 摘要(中文)
多跳问题仍然困扰着大型语言模型(LLMs),这些模型在跨多个推理步骤链接信息时表现不佳。我们提出了Auto-Patch,这是一种在推理过程中动态修补隐藏状态的新方法,以增强LLMs的多跳推理能力。Auto-Patch基于PatchScopes框架,利用学习到的分类器选择性地修改内部表示。在MuSiQue数据集上的评估表明,Auto-Patch的解题率从基线的18.45%提高到23.63±0.7%(3次实验),缩小了与链式思维提示(27.44%)之间的差距。我们的结果突显了动态隐藏状态干预在推动LLMs复杂推理方面的潜力。
🔬 方法详解
问题定义:本论文旨在解决大型语言模型在多跳推理任务中信息链接不足的问题。现有方法在处理复杂推理时,往往无法有效整合不同推理步骤的信息,导致解题率低下。
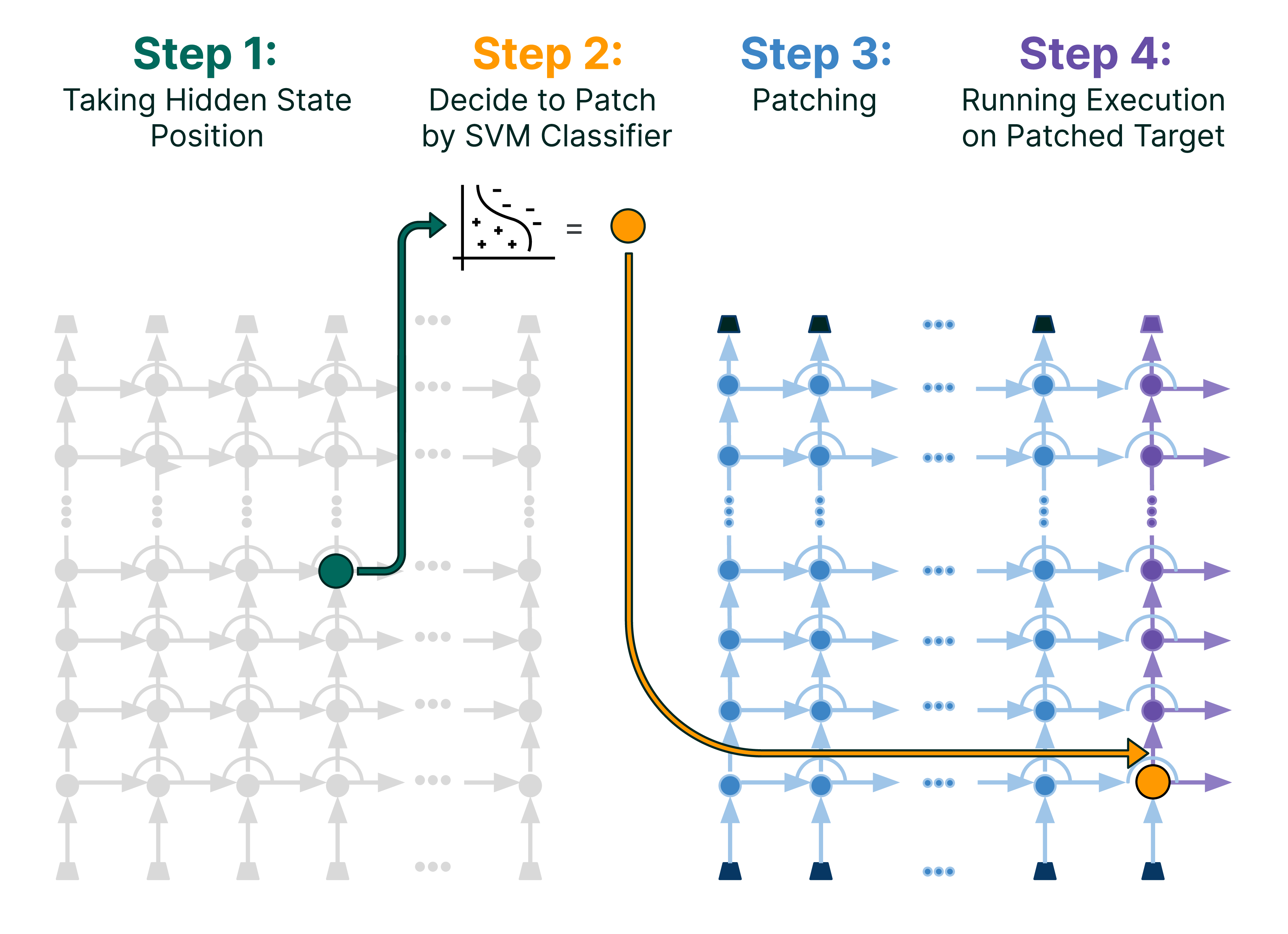
核心思路:Auto-Patch的核心思路是通过动态修补隐藏状态,利用一个学习到的分类器来选择性地修改模型的内部表示。这种设计旨在增强模型在多跳推理中的信息整合能力。
技术框架:Auto-Patch基于PatchScopes框架,整体流程包括输入数据的预处理、隐藏状态的动态修补以及最终的推理输出。主要模块包括分类器、隐藏状态修补机制和推理模块。
关键创新:最重要的技术创新点在于动态干预隐藏状态的能力,这与传统的静态推理方法本质上有所不同。通过这种动态修补,模型能够更好地适应复杂的推理任务。
关键设计:在设计中,Auto-Patch使用了特定的损失函数来优化分类器的性能,并对隐藏状态的修补过程进行了精细调节,以确保信息的有效整合。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Auto-Patch在MuSiQue数据集上的解题率从基线的18.45%提升至23.63±0.7%,相较于链式思维提示的27.44%缩小了差距。这一结果表明,动态隐藏状态干预在复杂推理任务中的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话系统以及任何需要复杂推理的自然语言处理任务。通过提升多跳推理能力,Auto-Patch可以显著提高模型在实际应用中的表现,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multi-hop questions still stump large language models (LLMs), which struggle to link information across multiple reasoning steps. We introduce Auto-Patch, a novel method that dynamically patches hidden states during inference to enhance multi-hop reasoning in LLMs. Building on the PatchScopes framework, Auto-Patch selectively modifies internal representations using a learned classifier. Evaluated on the MuSiQue dataset, Auto-Patch improves the solve rate from 18.45\% (baseline) to 23.63~$\pm$~0.7\% (3 runs), narrowing the gap to Chain-of-Thought prompting (27.44\%). Our results highlight the potential of dynamic hidden state interventions for advancing complex reasoning in LLMs.