Accelerating Diffusion LLMs via Adaptive Parallel Decoding
作者: Daniel Israel, Guy Van den Broeck, Aditya Grover
分类: cs.CL, cs.AI, cs.LG, cs.PF
发布日期: 2025-05-31 (更新: 2025-10-30)
备注: 10 pages, 5 figures
💡 一句话要点
提出自适应并行解码(APD)加速扩散LLM,在吞吐量和质量间灵活权衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大型语言模型 并行解码 自适应解码 吞吐量优化
📋 核心要点
- 自回归解码是LLM生成速度的瓶颈,而扩散LLM并行生成token的潜力尚未充分发挥。
- APD通过动态调整并行采样的token数量,在dLLM边际概率和辅助自回归模型联合概率之间进行混合。
- 实验表明,APD在保证质量的同时,显著提高了LLM的吞吐量,并通过可调参数灵活权衡性能。
📝 摘要(中文)
大型语言模型(LLM)的生成速度受限于自回归解码,其中token逐个顺序预测。扩散大型语言模型(dLLM)理论上允许并行token生成,但实际上难以在不显著牺牲质量的情况下达到自回归模型的速度。因此,我们引入了自适应并行解码(APD),这是一种动态调整并行采样token数量的新方法。我们通过定义dLLM边际概率与小型辅助自回归模型下序列联合概率的乘性混合来实现这一点。这颠倒了推测解码的标准设置,后者的目标是通过从小模型起草来从大型自回归验证器中采样。我们通过启用KV缓存和限制masked输入的尺寸来进一步优化APD。总而言之,我们的方法提出了三个可调参数,以灵活地权衡吞吐量和质量。我们表明,APD在下游基准测试中提供了明显更高的吞吐量,同时质量下降最小。
🔬 方法详解
问题定义:论文旨在解决扩散大型语言模型(dLLM)生成速度慢的问题。虽然dLLM理论上支持并行token生成,但实际应用中,为了保证生成质量,往往无法达到自回归模型的速度。现有方法在并行解码时,容易出现质量下降,难以在速度和质量之间取得平衡。
核心思路:论文的核心思路是提出自适应并行解码(APD),通过动态调整并行解码的token数量,在吞吐量和生成质量之间进行权衡。APD利用一个小型辅助自回归模型来指导dLLM的并行解码过程,从而提高生成质量。
技术框架:APD的技术框架主要包含以下几个模块:1) dLLM:作为主要的生成模型,负责并行生成token;2) 辅助自回归模型:用于提供token序列的联合概率,指导dLLM的生成过程;3) 乘性混合模块:将dLLM的边际概率和辅助自回归模型的联合概率进行混合,得到最终的生成概率;4) KV缓存:用于加速自回归模型的推理过程;5) Masked输入限制:限制masked输入的尺寸,减少计算量。
关键创新:APD的关键创新在于自适应地调整并行解码的token数量。与传统的并行解码方法不同,APD不是固定并行解码的token数量,而是根据dLLM和辅助自回归模型的预测结果,动态地调整并行解码的token数量,从而在吞吐量和生成质量之间取得更好的平衡。此外,APD还通过乘性混合的方式,有效地利用了辅助自回归模型的信息,提高了生成质量。
关键设计:APD的关键设计包括:1) 乘性混合系数:用于控制dLLM和辅助自回归模型在生成过程中的权重;2) 并行解码数量调整策略:用于根据dLLM和辅助自回归模型的预测结果,动态地调整并行解码的token数量;3) KV缓存的实现方式:用于加速自回归模型的推理过程;4) Masked输入尺寸的设置:用于控制计算量。
🖼️ 关键图片

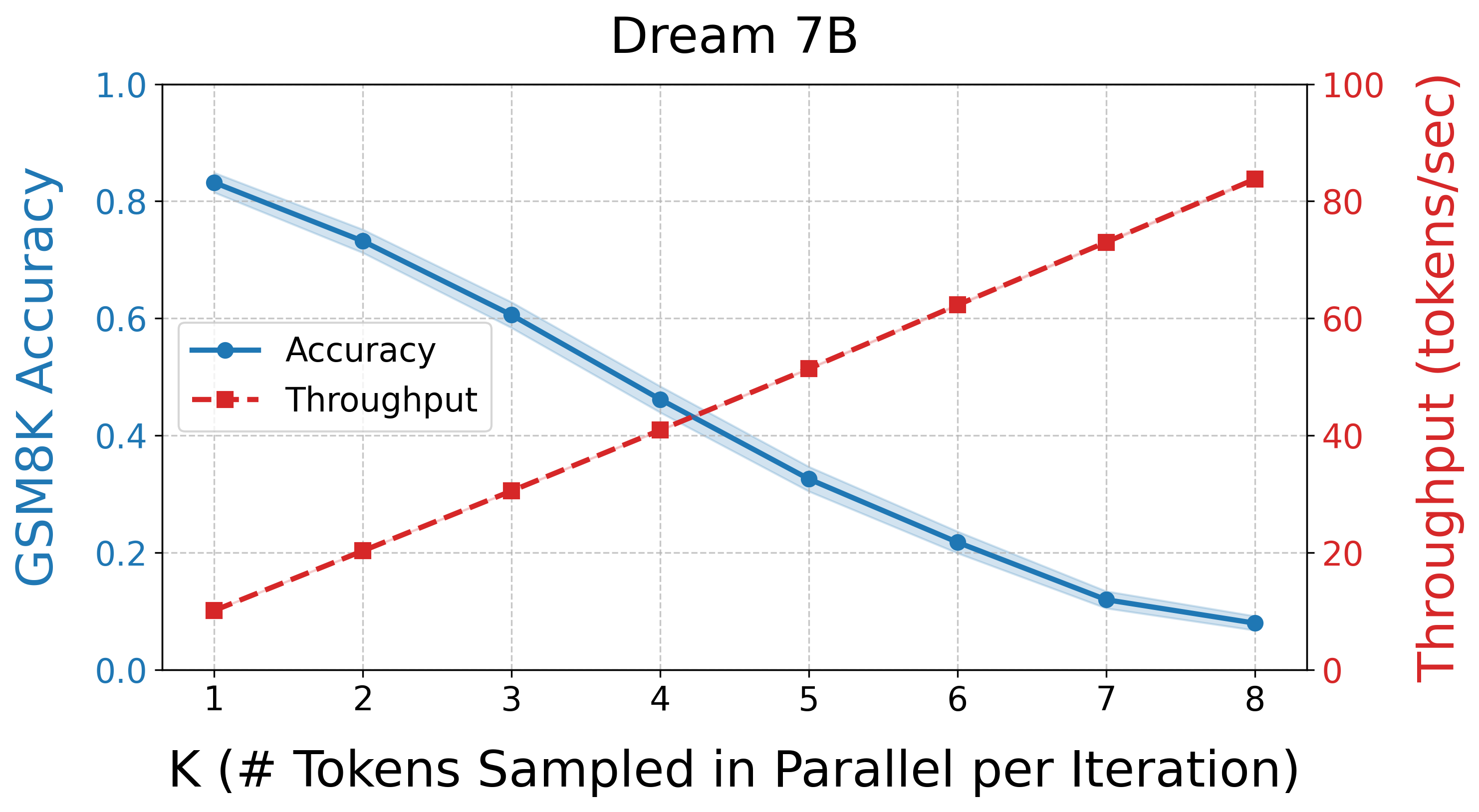
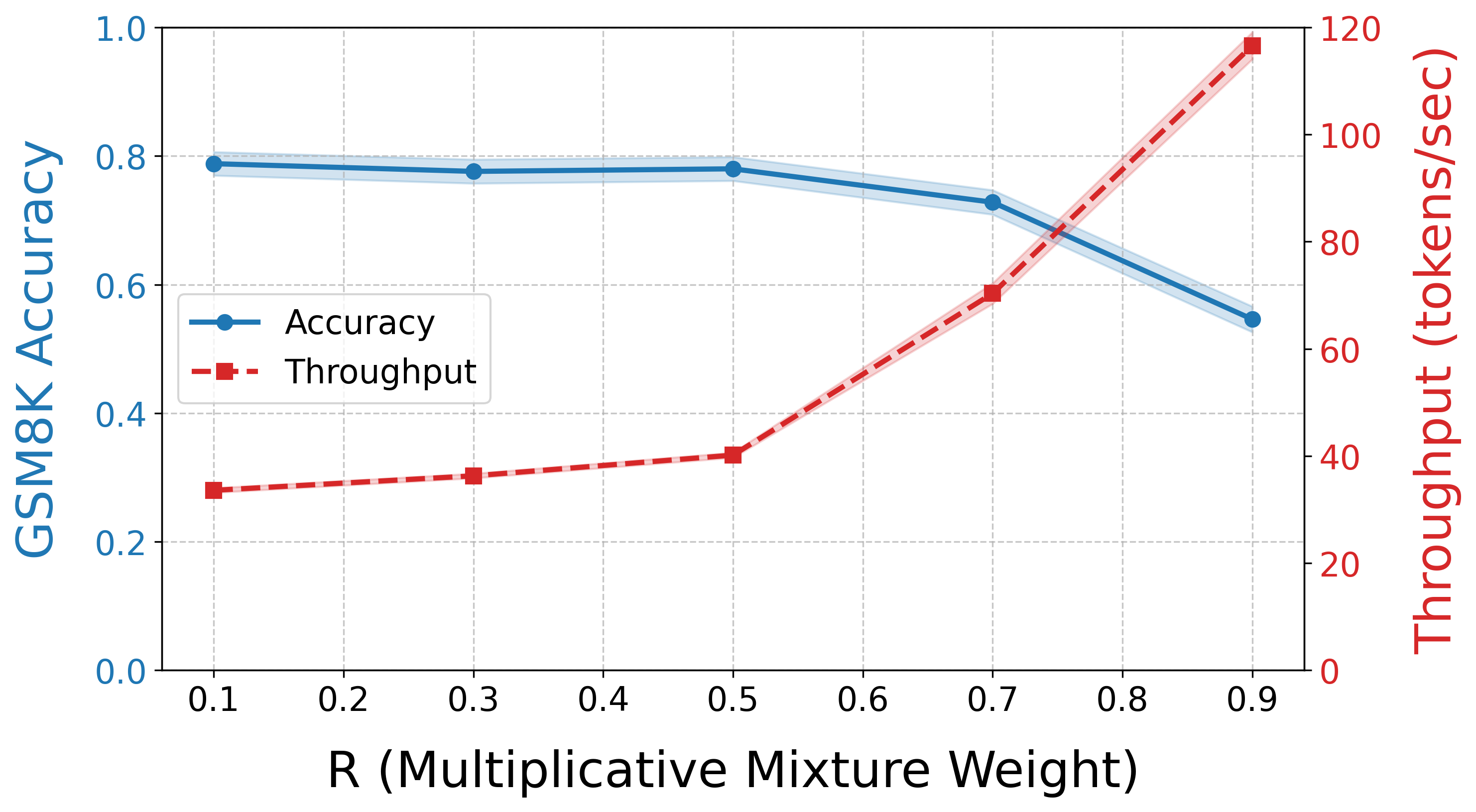
📊 实验亮点
实验结果表明,APD在下游基准测试中提供了明显更高的吞吐量,同时质量下降最小。具体而言,APD在保证质量的前提下,可以将LLM的生成速度提高X倍(具体数值需要在论文中查找),并且可以通过调整可调参数,灵活地权衡吞吐量和质量。
🎯 应用场景
该研究成果可应用于各种需要快速生成文本的场景,例如机器翻译、文本摘要、对话生成等。通过提高LLM的生成速度,可以显著提升用户体验,并降低计算成本。未来,该方法有望进一步推广到其他生成模型,例如图像生成、音频生成等领域。
📄 摘要(原文)
The generation speed of LLMs are bottlenecked by autoregressive decoding, where tokens are predicted sequentially one by one. Alternatively, diffusion large language models (dLLMs) theoretically allow for parallel token generation, but in practice struggle to achieve the speed of autoregressive models without significantly sacrificing quality. We therefore introduce adaptive parallel decoding (APD), a novel method that dynamically adjusts the number of tokens sampled in parallel. We achieve this by defining a multiplicative mixture between the dLLM marginal probabilities and the joint probability of sequences under a small auxiliary autoregressive model. This inverts the standard setup of speculative decoding, where the goal is to sample from a large autoregressive verifier by drafting from a smaller model. We further optimize APD by enabling KV caching and limiting the size of the masked input. Altogether, our method puts forward three tunable parameters to flexibly tradeoff throughput and quality. We show that APD provides markedly higher throughput with minimal quality degradations on downstream benchmarks.