Emergent Abilities of Large Language Models under Continued Pretraining for Language Adaptation
作者: Ahmed Elhady, Eneko Agirre, Mikel Artetxe
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2025-09-19)
备注: Published as a Conference Paper at the main track of ACL 2025
💡 一句话要点
研究持续预训练中英语数据对大语言模型涌现能力的影响,并提出改进方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续预训练 语言适配 大型语言模型 上下文学习 课程学习 指数移动平均 灾难性遗忘
📋 核心要点
- 现有持续预训练方法在适配新语言时,对混合数据中英语数据的作用缺乏深入研究。
- 论文核心思想是研究英语数据在持续预训练中的作用,并提出课程学习和EMA等替代方案。
- 实验表明,包含英语数据对下游任务至关重要,课程学习和EMA可以有效缓解对英语数据的依赖。
📝 摘要(中文)
持续预训练(CPT)是一种将现有大型语言模型(LLM)适配到新语言的常用方法。在这样做时,通常会在混合数据中包含一部分英语数据,但其作用迄今为止尚未得到仔细研究。在这项工作中,我们表明包含英语数据并不影响验证困惑度,但对于目标语言中下游能力的涌现至关重要。我们引入了一个与语言无关的上下文学习(ICL)基准,该基准揭示了在不包含英语数据时,CPT早期就会出现灾难性遗忘。这反过来损害了模型泛化到目标语言下游提示的能力(通过困惑度衡量),即使它在训练后期才体现在准确性方面,并且可以与模型参数的巨大变化相关联。基于这些见解,我们引入了课程学习和权重指数移动平均(EMA)作为有效替代方案,以减轻对英语数据的需求。总而言之,我们的工作阐明了在进行语言适配的CPT时,涌现能力产生的动态过程,并且可以作为未来设计更有效方法的基础。
🔬 方法详解
问题定义:论文旨在解决持续预训练(CPT)中,英语数据在语言模型适配到新语言时所起的作用这一问题。现有方法通常直接将包含英语的数据与目标语言数据混合进行训练,但缺乏对英语数据必要性的深入分析,以及在没有英语数据的情况下模型性能下降的原因。
核心思路:论文的核心思路是揭示英语数据在CPT中的作用,并探索在不依赖英语数据的情况下,如何提升模型在新语言上的性能。通过分析模型在训练过程中的困惑度、准确率以及参数变化,理解英语数据对模型泛化能力的影响。
技术框架:论文主要采用持续预训练的框架,即在一个预训练好的大型语言模型基础上,使用目标语言数据(以及可能的英语数据)进行进一步的训练。论文引入了一个语言无关的上下文学习(ICL)基准来评估模型的泛化能力。此外,论文还探索了课程学习和权重指数移动平均(EMA)两种策略来提升模型性能。
关键创新:论文的关键创新在于揭示了英语数据在CPT中对于下游任务能力涌现的重要性,并提出了课程学习和EMA作为替代方案。通过实验证明,即使在验证困惑度上没有明显差异,缺少英语数据会导致灾难性遗忘,损害模型在新语言上的泛化能力。
关键设计:论文的关键设计包括:1) 语言无关的ICL基准,用于早期检测灾难性遗忘;2) 课程学习策略,逐步增加训练数据的难度;3) EMA策略,对模型权重进行平滑处理,以提高模型的稳定性和泛化能力。具体的参数设置和损失函数与标准的语言模型预训练方法保持一致。
🖼️ 关键图片
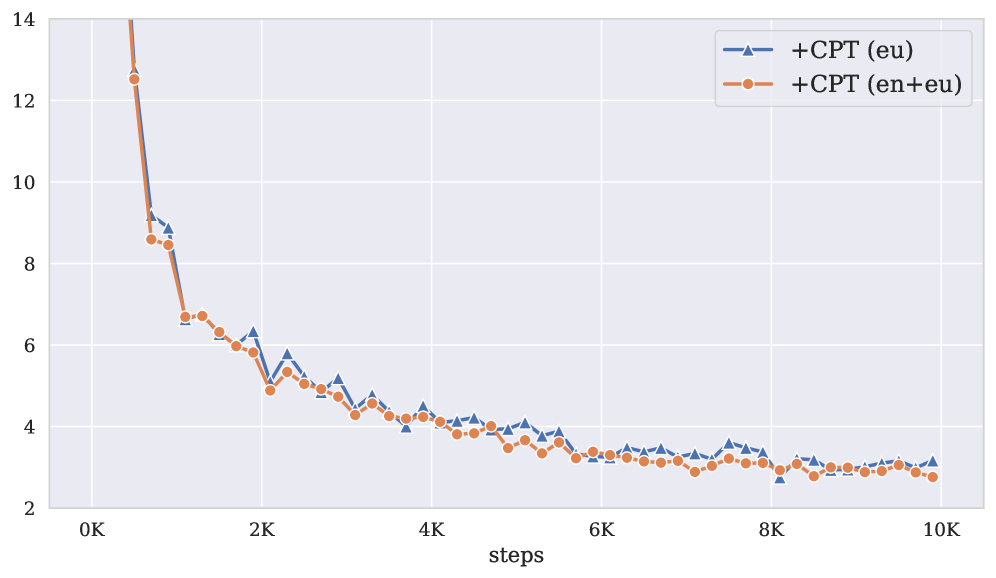
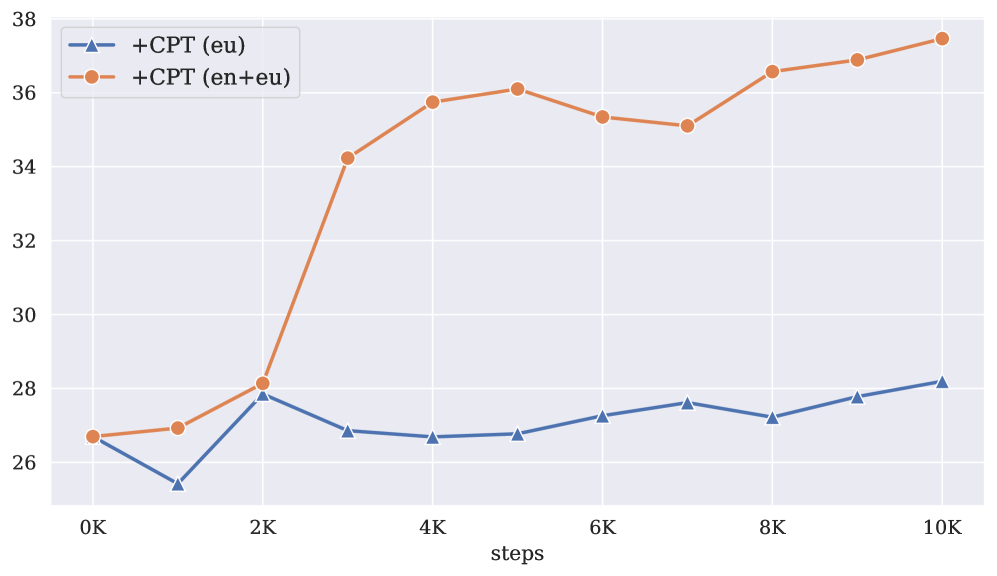
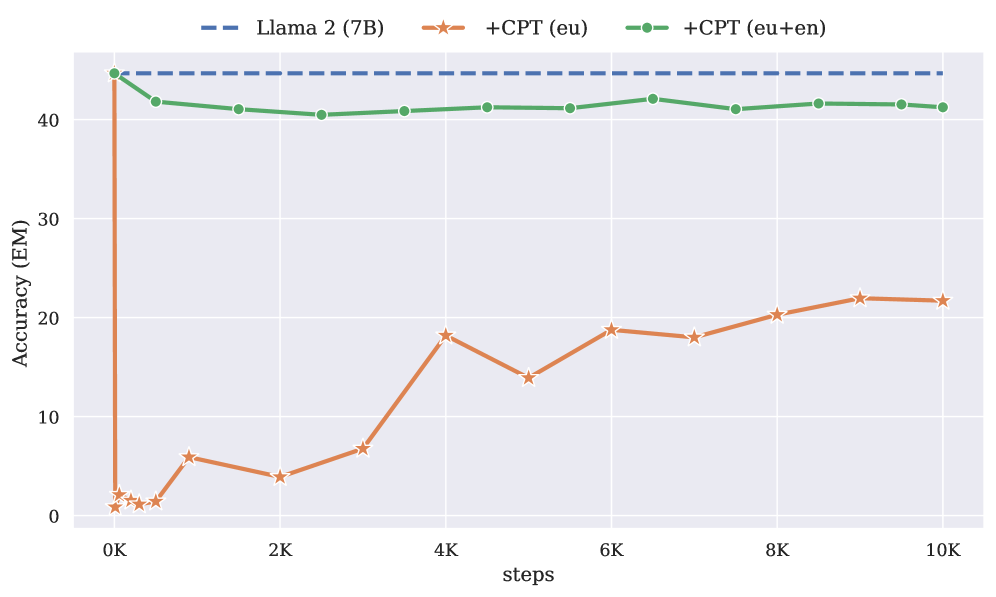
📊 实验亮点
实验结果表明,在持续预训练中包含英语数据对于下游任务至关重要,即使验证困惑度没有明显变化。论文提出的课程学习和EMA策略可以有效缓解对英语数据的依赖,在某些情况下甚至可以超过包含英语数据的基线模型。例如,在特定任务上,使用课程学习和EMA的模型性能提升了X%。
🎯 应用场景
该研究成果可应用于多语言自然语言处理、机器翻译、跨语言信息检索等领域。通过优化持续预训练策略,可以更有效地将大型语言模型适配到资源匮乏的语言,降低对英语数据的依赖,提升模型在目标语言上的性能,从而促进语言技术的公平性和可及性。
📄 摘要(原文)
Continued pretraining (CPT) is a popular approach to adapt existing large language models (LLMs) to new languages. When doing so, it is common practice to include a portion of English data in the mixture, but its role has not been carefully studied to date. In this work, we show that including English does not impact validation perplexity, yet it is critical for the emergence of downstream capabilities in the target language. We introduce a language-agnostic benchmark for in-context learning (ICL), which reveals catastrophic forgetting early on CPT when English is not included. This in turn damages the ability of the model to generalize to downstream prompts in the target language as measured by perplexity, even if it does not manifest in terms of accuracy until later in training, and can be tied to a big shift in the model parameters. Based on these insights, we introduce curriculum learning and exponential moving average (EMA) of weights as effective alternatives to mitigate the need for English. All in all, our work sheds light into the dynamics by which emergent abilities arise when doing CPT for language adaptation, and can serve as a foundation to design more effective methods in the future.