Hierarchical Level-Wise News Article Clustering via Multilingual Matryoshka Embeddings
作者: Hans W. A. Hanley, Zakir Durumeric
分类: cs.CL, cs.AI, cs.SI
发布日期: 2025-05-30
备注: Accepted to The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025)
💡 一句话要点
提出基于多语言Matryoshka嵌入的分层新闻文章聚类方法,提升可扩展性和可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 新闻聚类 主题建模 多语言处理 Matryoshka嵌入 分层聚类
📋 核心要点
- 现有基于上下文大语言模型嵌入的主题建模和聚类方法,在可扩展性、透明度和多语言支持方面存在不足。
- 论文提出利用多语言Matryoshka嵌入,通过维度子集分析实现不同粒度的相似度计算,从而进行分层聚类。
- 实验表明,该方法在SemEval 2022 Task 8数据集上取得了领先性能,验证了其有效性。
📝 摘要(中文)
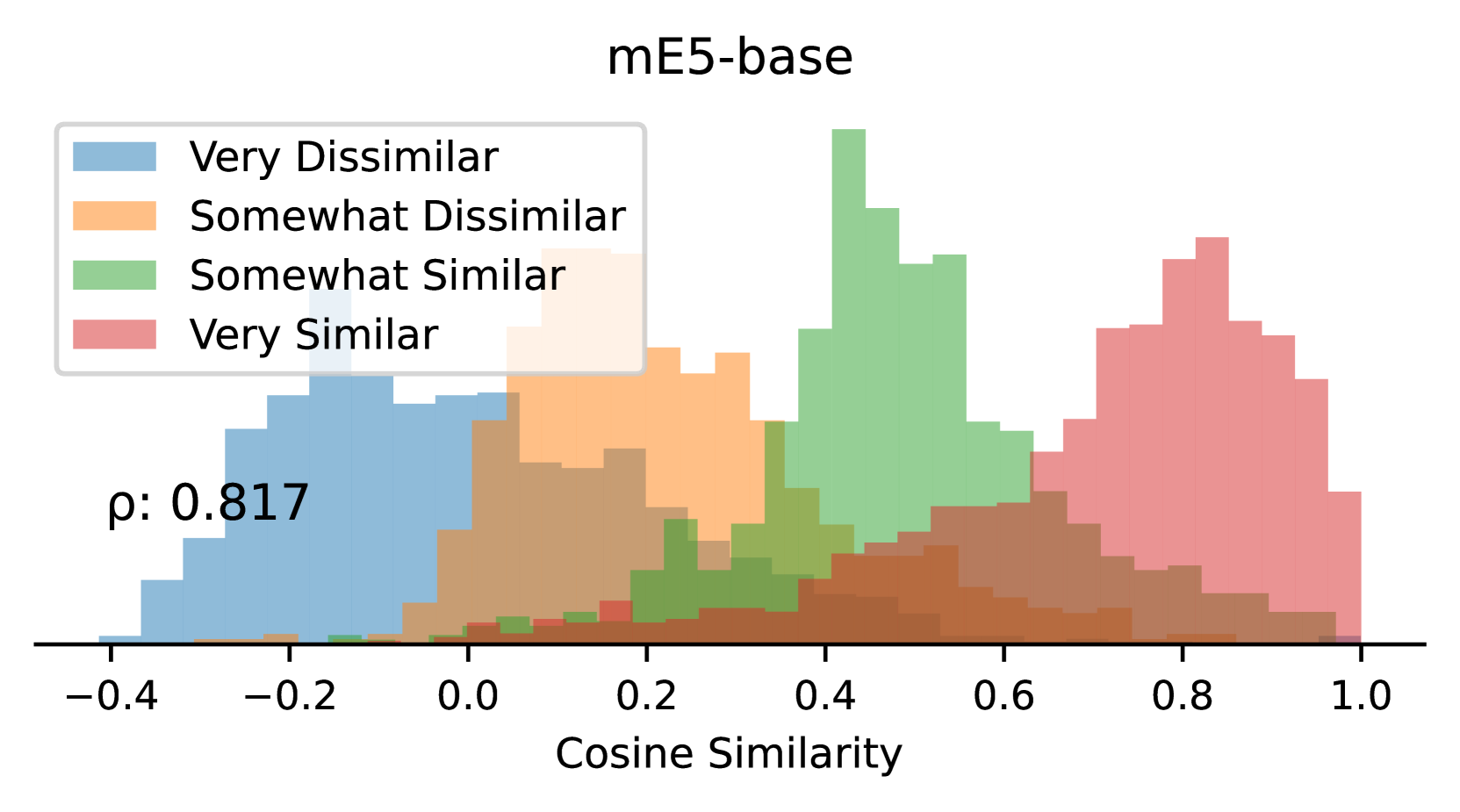
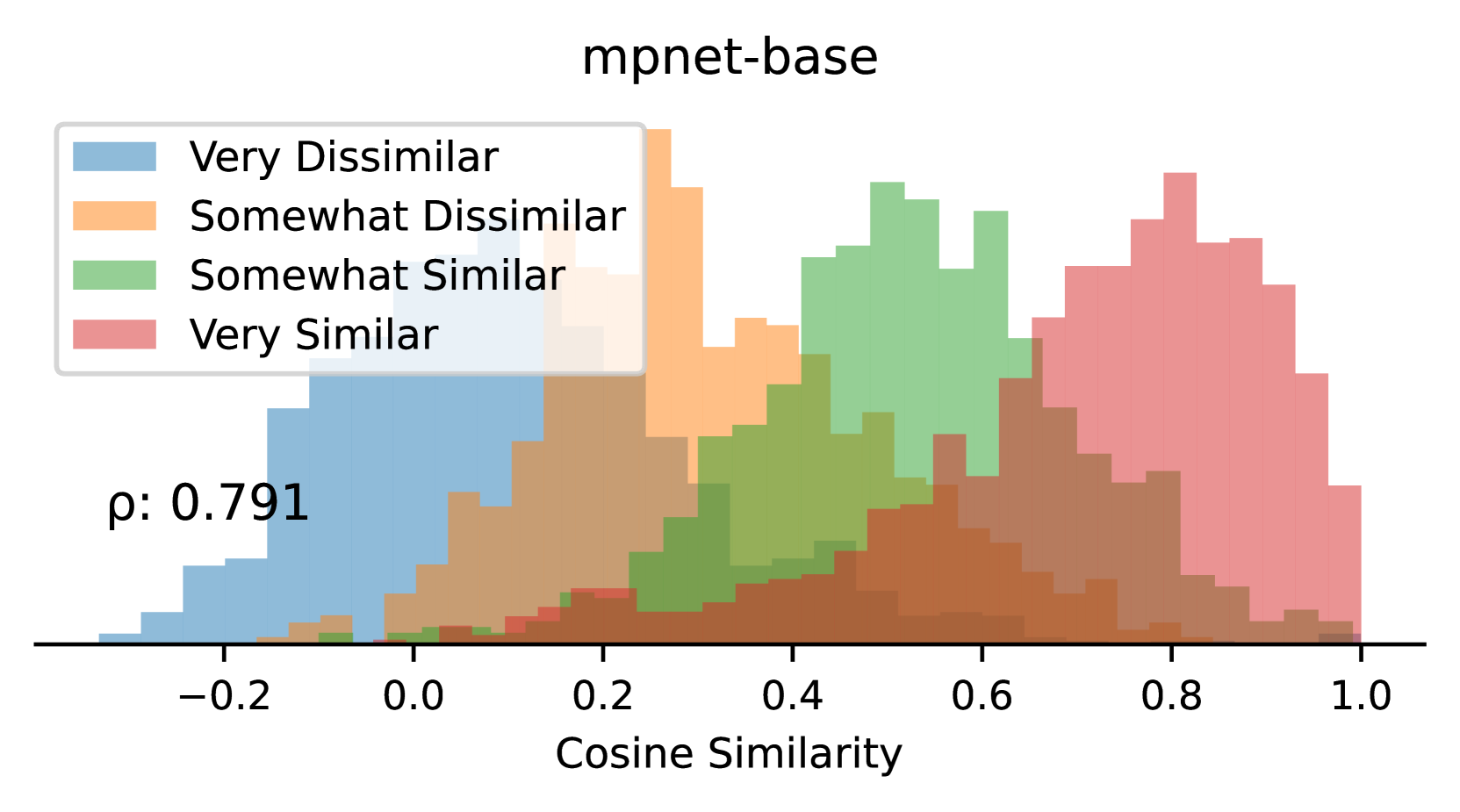
本文提出了一种新颖、可扩展、可解释、分层且多语言的新闻文章和社会媒体数据聚类方法。该方法首先训练多语言Matryoshka嵌入,该嵌入能够根据所检查的嵌入维度子集,确定不同粒度级别的故事相似性。该嵌入模型在SemEval 2022 Task 8测试数据集上取得了最先进的性能(Pearson $ρ$ = 0.816)。训练完成后,我们开发了一种高效的分层聚类算法,该算法利用Matryoshka嵌入的分层特性来识别独特的新闻故事、叙述和主题。最后,我们通过展示我们的方法如何在真实世界的新闻数据集中识别和聚类故事、叙述和总体主题来总结。
🔬 方法详解
问题定义:现有基于大型语言模型嵌入的新闻聚类方法通常面临可扩展性差、相似度度量不透明以及难以处理多语言环境的挑战。这些痛点限制了它们在实际新闻分析和主题发现中的应用。
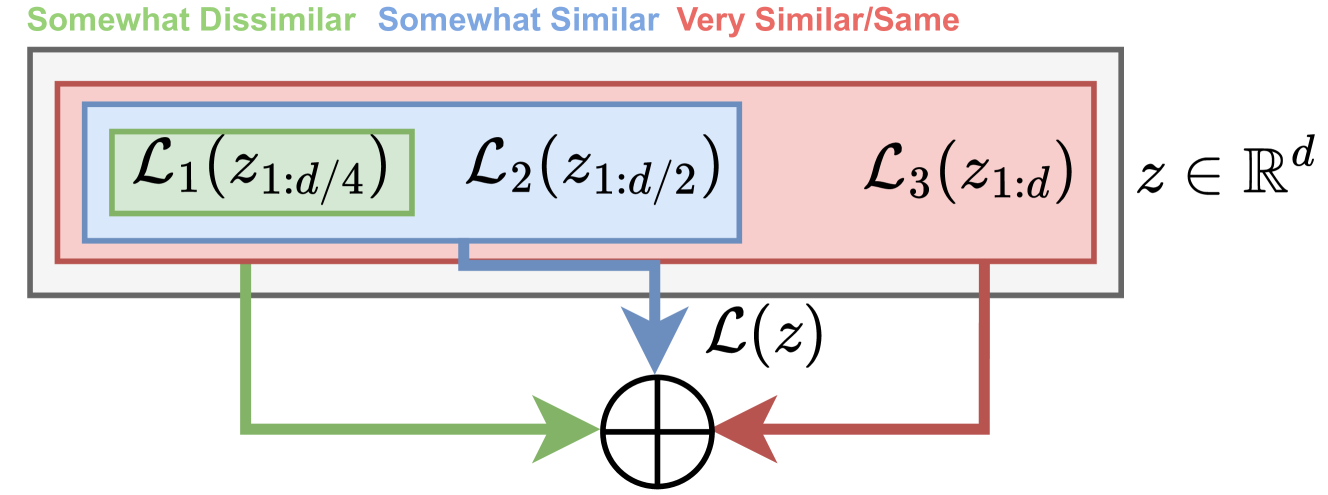
核心思路:论文的核心思路是利用Matryoshka嵌入的分层特性,通过分析不同维度子集来捕捉不同粒度的语义信息。这种分层表示允许算法在不同层次上识别新闻故事的相似性,从而实现更细粒度和可解释的聚类。
技术框架:该方法主要包含两个阶段:1) 训练多语言Matryoshka嵌入模型;2) 基于该嵌入模型,开发高效的分层聚类算法。嵌入模型负责将新闻文章映射到分层向量空间,聚类算法则利用这些向量进行故事、叙述和主题的识别。
关键创新:最重要的技术创新在于Matryoshka嵌入的应用。传统的嵌入方法通常将所有维度视为同等重要,而Matryoshka嵌入则允许根据维度子集来调整相似度计算的粒度。这种分层表示方式更符合新闻主题的自然结构,并提高了聚类的准确性和可解释性。
关键设计:Matryoshka嵌入的训练细节未知,但可以推测其损失函数可能包含多个目标,以确保不同维度子集能够捕捉不同层次的语义信息。分层聚类算法的具体实现也未知,但可以推测其可能采用自底向上的策略,逐步合并相似的故事,最终形成主题层次结构。
🖼️ 关键图片
📊 实验亮点
该方法在SemEval 2022 Task 8测试数据集上取得了最先进的性能,Pearson相关系数达到0.816。这一结果表明,该方法在新闻文章相似度计算方面具有显著优势,能够有效捕捉不同粒度的语义信息。
🎯 应用场景
该研究成果可应用于新闻聚合、舆情分析、虚假信息检测等领域。通过自动识别和聚类新闻故事,可以帮助用户快速了解事件的来龙去脉,监测舆论趋势,并识别潜在的虚假信息传播。未来,该方法还可扩展到其他类型的文本数据,如社交媒体帖子、博客文章等。
📄 摘要(原文)
Contextual large language model embeddings are increasingly utilized for topic modeling and clustering. However, current methods often scale poorly, rely on opaque similarity metrics, and struggle in multilingual settings. In this work, we present a novel, scalable, interpretable, hierarchical, and multilingual approach to clustering news articles and social media data. To do this, we first train multilingual Matryoshka embeddings that can determine story similarity at varying levels of granularity based on which subset of the dimensions of the embeddings is examined. This embedding model achieves state-of-the-art performance on the SemEval 2022 Task 8 test dataset (Pearson $ρ$ = 0.816). Once trained, we develop an efficient hierarchical clustering algorithm that leverages the hierarchical nature of Matryoshka embeddings to identify unique news stories, narratives, and themes. We conclude by illustrating how our approach can identify and cluster stories, narratives, and overarching themes within real-world news datasets.