LegalEval-Q: A New Benchmark for The Quality Evaluation of LLM-Generated Legal Text
作者: Li yunhan, Wu gengshen
分类: cs.CL, cs.CV
发布日期: 2025-05-30 (更新: 2025-11-10)
备注: 10 pages, 11 figures
🔗 代码/项目: GITHUB
💡 一句话要点
LegalEval-Q:提出法律领域LLM质量评估基准,关注清晰度、连贯性和术语准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律LLM评估 语言质量评估 清晰度 连贯性 术语准确性 回归模型 LegalEval-Q
📋 核心要点
- 现有法律领域LLM评估侧重事实准确性,忽略了清晰度、连贯性和术语等语言质量维度。
- 构建回归模型评估法律文本质量,关注清晰度、连贯性和术语,并创建专业法律问题集。
- 实验表明模型质量在140亿参数后提升有限,推理模型优于基础模型,Qwen3系列性价比高。
📝 摘要(中文)
随着大型语言模型(LLMs)在法律应用中日益普及,现有的评估基准往往主要关注事实准确性,而很大程度上忽略了重要的语言质量方面,如清晰度、连贯性和术语。为了解决这一差距,我们提出了三个步骤:首先,我们开发了一个回归模型,用于评估法律文本的质量,该模型基于清晰度、连贯性和术语。其次,我们创建了一套专门的法律问题。第三,我们使用这个评估框架分析了49个LLM。我们的分析确定了三个关键发现:首先,模型质量在140亿参数时趋于稳定,在720亿参数时仅观察到2.7%的边际改进。其次,量化和上下文长度等工程选择的影响可以忽略不计,统计显著性阈值高于0.016。第三,推理模型始终优于基础架构。我们研究的一个重要成果是发布了一个排名列表和帕累托分析,其中强调了Qwen3系列是性价比的最佳选择。这项工作不仅为法律LLM建立了标准化评估协议,而且揭示了当前训练数据改进方法的基本局限性。代码和模型可在https://github.com/lyxx3rd/LegalEval-Q获取。
🔬 方法详解
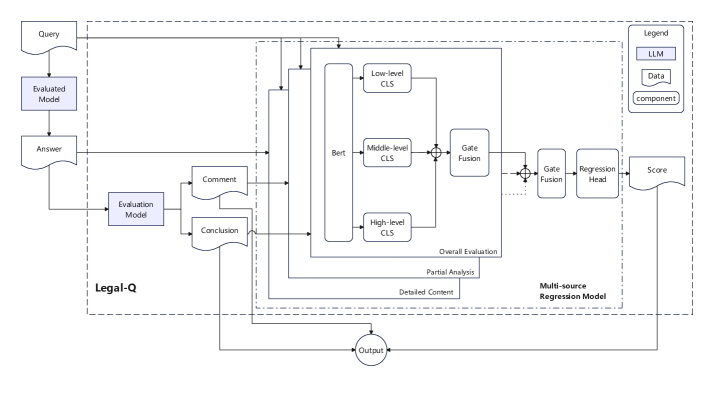
问题定义:现有法律领域的大型语言模型(LLMs)评估主要集中在事实准确性上,而忽略了法律文本中至关重要的语言质量,例如清晰度、连贯性和专业术语的准确使用。这种片面的评估方式无法全面反映LLM在法律领域的实际应用能力,阻碍了模型在该领域的进一步优化和发展。现有方法缺乏对法律文本语言质量的细致评估标准和工具。
核心思路:该论文的核心思路是构建一个专门用于评估LLM生成法律文本质量的基准,该基准不仅关注事实准确性,更侧重于清晰度、连贯性和术语的准确性。通过构建回归模型来量化这些语言质量指标,并设计一套专业的法律问题集,从而对LLM进行更全面、更细致的评估。这种设计旨在弥补现有评估体系的不足,推动LLM在法律领域的应用。
技术框架:该研究的技术框架主要包含三个阶段:1. 回归模型构建:开发一个回归模型,用于评估法律文本的质量,该模型以清晰度、连贯性和术语作为评估指标。2. 法律问题集创建:构建一套专门的法律问题集,用于测试LLM在法律领域的理解和生成能力。3. LLM评估与分析:使用构建的评估框架对49个LLM进行评估,并分析其在不同语言质量指标上的表现。最终,生成一个排名列表和帕累托分析,以突出性价比最高的模型。
关键创新:该论文的关键创新在于提出了一个专门针对法律领域LLM的质量评估基准LegalEval-Q,该基准不仅关注事实准确性,更侧重于清晰度、连贯性和术语的准确性。与现有方法相比,LegalEval-Q能够更全面、更细致地评估LLM在法律领域的应用能力,为模型的优化和发展提供了更有效的指导。此外,该研究还揭示了当前训练数据改进方法的局限性。
关键设计:回归模型的具体参数设置、损失函数和网络结构等技术细节未知。法律问题集的设计侧重于考察LLM对法律概念的理解、法律推理能力以及法律术语的运用。实验中,作者分析了不同参数规模、量化方法和上下文长度对模型性能的影响,并比较了推理模型和基础模型的表现。统计显著性阈值设置为0.016,用于判断工程选择的影响是否显著。
🖼️ 关键图片


📊 实验亮点
实验结果表明,模型质量在140亿参数时趋于稳定,720亿参数时仅提升2.7%。量化和上下文长度等工程选择的影响不显著(p > 0.016)。推理模型始终优于基础架构。Qwen3系列在性价比方面表现突出,被认为是法律领域LLM的最佳选择。
🎯 应用场景
该研究成果可应用于法律咨询、法律文书生成、法律教育等领域。通过LegalEval-Q基准,可以更准确地评估和选择适合特定法律任务的LLM,提高法律服务的效率和质量。此外,该研究还可以指导LLM在法律领域的训练和优化,推动法律人工智能的发展。
📄 摘要(原文)
As large language models (LLMs) are increasingly used in legal applications, current evaluation benchmarks tend to focus mainly on factual accuracy while largely neglecting important linguistic quality aspects such as clarity, coherence, and terminology. To address this gap, we propose three steps: First, we develop a regression model to evaluate the quality of legal texts based on clarity, coherence, and terminology. Second, we create a specialized set of legal questions. Third, we analyze 49 LLMs using this evaluation framework. Our analysis identifies three key findings: First, model quality levels off at 14 billion parameters, with only a marginal improvement of $2.7\%$ noted at 72 billion parameters. Second, engineering choices such as quantization and context length have a negligible impact, as indicated by statistical significance thresholds above 0.016. Third, reasoning models consistently outperform base architectures. A significant outcome of our research is the release of a ranking list and Pareto analysis, which highlight the Qwen3 series as the optimal choice for cost-performance tradeoffs. This work not only establishes standardized evaluation protocols for legal LLMs but also uncovers fundamental limitations in current training data refinement approaches. Code and models are available at: https://github.com/lyxx3rd/LegalEval-Q.