Disentangling Language and Culture for Evaluating Multilingual Large Language Models
作者: Jiahao Ying, Wei Tang, Yiran Zhao, Yixin Cao, Yu Rong, Wenxuan Zhang
分类: cs.CL
发布日期: 2025-05-30
备注: Accepted to ACL 2025 (Main Conference)
💡 一句话要点
提出双重评估框架,解耦语言和文化因素,更全面评估多语言大模型的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言大模型 评估框架 文化理解 语言理解 跨文化 神经元激活 可解释性
📋 核心要点
- 现有评估方法未能充分区分语言能力和文化理解能力,导致对多语言大模型的评估不够全面。
- 提出双重评估框架,将评估分解为语言媒介和文化背景两个维度,实现更细粒度的性能分析。
- 实验揭示“文化-语言协同”现象,并发现神经元激活比例与文化背景相关,为模型训练提供新指标。
📝 摘要(中文)
本文提出了一种双重评估框架,旨在全面评估多语言大模型的性能。该框架通过将评估分解为语言媒介和文化背景两个维度,从而能够细致地分析大模型在母语和跨文化语境中处理问题的能力。对大量模型进行了广泛的评估,揭示了一种显著的“文化-语言协同”现象,即当问题在文化上与语言对齐时,模型表现更好。通过可解释性探究进一步研究了这种现象,结果表明,在一种语言的文化背景下,特定神经元的激活比例更高。这种激活比例可以作为模型训练期间评估多语言性能的潜在指标。我们的发现挑战了主要在英语数据上训练的大模型在所有语言上表现一致的普遍观念,并强调了进行文化和语言模型评估的必要性。代码可在https://yingjiahao14.github.io/Dual-Evaluation/找到。
🔬 方法详解
问题定义:现有的大语言模型评估方法通常将语言能力和文化理解能力混为一谈,无法准确评估模型在不同文化背景下的表现。尤其是在跨语言场景中,模型可能因为文化差异而产生偏差,导致评估结果失真。因此,需要一种能够解耦语言和文化因素的评估方法,以便更全面地了解多语言大模型的真实能力。
核心思路:本文的核心思路是将多语言大模型的评估分解为两个独立的维度:语言媒介和文化背景。通过控制这两个维度,可以分别评估模型在不同语言和文化环境下的表现,从而揭示模型在跨文化场景中的潜在问题。这种解耦的思想有助于更准确地诊断模型的弱点,并为改进模型提供指导。
技术框架:该双重评估框架包含以下主要步骤:1)构建包含不同语言和文化背景的问题集;2)使用多语言大模型回答问题;3)根据语言媒介和文化背景对答案进行分类;4)使用评估指标(如准确率、BLEU等)评估模型在不同类别下的表现;5)进行可解释性分析,例如通过神经元激活分析来探究模型内部的文化理解机制。
关键创新:该框架的关键创新在于其双重评估的设计,能够将语言和文化因素解耦,从而实现更细粒度的性能分析。此外,通过可解释性分析,可以深入了解模型内部的文化理解机制,为模型改进提供更具体的指导。与传统的评估方法相比,该框架能够更全面地评估多语言大模型的真实能力,并揭示模型在跨文化场景中的潜在问题。
关键设计:在问题集构建方面,需要确保问题在不同语言和文化背景下的语义一致性,避免因翻译或文化差异导致评估结果偏差。在评估指标选择方面,可以根据具体任务选择合适的指标,例如对于生成任务可以使用BLEU、ROUGE等指标,对于分类任务可以使用准确率、F1值等指标。在可解释性分析方面,可以使用神经元激活分析、注意力机制可视化等方法来探究模型内部的文化理解机制。
🖼️ 关键图片


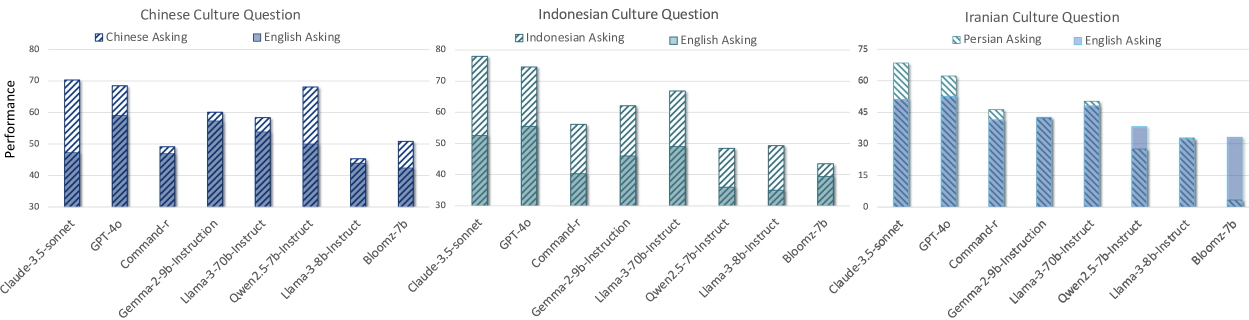
📊 实验亮点
实验结果表明,多语言大模型在文化上与语言对齐时表现更好,即存在“文化-语言协同”现象。例如,模型在回答中文文化背景下的中文问题时,表现优于回答英文文化背景下的中文问题。此外,神经元激活分析表明,在一种语言的文化背景下,特定神经元的激活比例更高,这为评估多语言性能提供了一种新的指标。
🎯 应用场景
该研究成果可应用于多语言大模型的开发和评估,帮助开发者更好地了解模型在不同语言和文化背景下的表现,从而改进模型的设计和训练。此外,该框架还可以用于评估机器翻译系统的质量,以及检测和纠正模型中的文化偏见。在跨文化交流、国际商务等领域具有潜在的应用价值。
📄 摘要(原文)
This paper introduces a Dual Evaluation Framework to comprehensively assess the multilingual capabilities of LLMs. By decomposing the evaluation along the dimensions of linguistic medium and cultural context, this framework enables a nuanced analysis of LLMs' ability to process questions within both native and cross-cultural contexts cross-lingually. Extensive evaluations are conducted on a wide range of models, revealing a notable "CulturalLinguistic Synergy" phenomenon, where models exhibit better performance when questions are culturally aligned with the language. This phenomenon is further explored through interpretability probing, which shows that a higher proportion of specific neurons are activated in a language's cultural context. This activation proportion could serve as a potential indicator for evaluating multilingual performance during model training. Our findings challenge the prevailing notion that LLMs, primarily trained on English data, perform uniformly across languages and highlight the necessity of culturally and linguistically model evaluations. Our code can be found at https://yingjiahao14. github.io/Dual-Evaluation/.