Reasoning Models Hallucinate More: Factuality-Aware Reinforcement Learning for Large Reasoning Models
作者: Junyi Li, Hwee Tou Ng
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2025-11-06)
备注: accepted by NeurIPS 2025
💡 一句话要点
提出FSPO:通过事实性感知强化学习,减少大语言推理模型中的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 推理 幻觉 事实性验证 策略优化 Qwen2.5 Llama
📋 核心要点
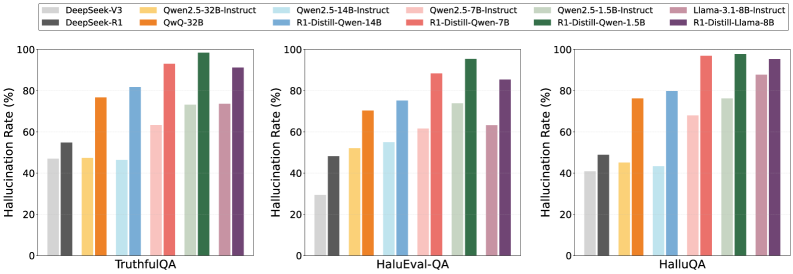
- 现有基于强化学习的语言模型推理优化方法,存在幻觉问题加剧的缺陷,影响了模型的可靠性。
- 论文提出Factuality-aware Step-wise Policy Optimization (FSPO) 算法,通过在推理过程中引入事实性验证来解决幻觉问题。
- 实验结果表明,FSPO 算法在减少幻觉的同时,提升了推理准确性,显著提高了模型的可靠性和性能。
📝 摘要(中文)
大型语言模型(LLMs)通过强化学习(RL)优化在推理任务中取得了显著进展,在各种具有挑战性的基准测试中展现了令人印象深刻的能力。然而,我们的实证分析揭示了一个关键缺陷:面向推理的RL微调显著增加了幻觉的发生率。我们从理论上分析了RL训练动态,将高方差梯度、熵引起的随机性和对虚假局部最优的敏感性确定为导致幻觉的关键因素。为了解决这个缺陷,我们提出了一种新颖的RL微调算法,即事实性感知的逐步策略优化(FSPO),该算法在每个推理步骤中都结合了显式的事实性验证。FSPO利用针对给定证据的自动验证来动态调整token级别的优势值,从而在整个推理过程中激励事实正确性。使用Qwen2.5和Llama模型在数学推理和幻觉基准测试上的实验表明,FSPO有效地减少了幻觉,同时提高了推理准确性,从而大大提高了可靠性和性能。
🔬 方法详解
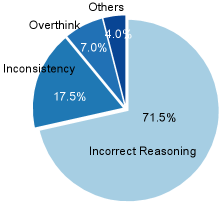
问题定义:现有的大型语言模型在推理任务中,通过强化学习进行微调后,虽然在某些基准测试中表现出色,但会显著增加幻觉的产生。这意味着模型在推理过程中可能会生成不真实或与已知事实相悖的内容,降低了模型的可靠性。现有的强化学习方法未能充分考虑事实性,导致模型容易陷入局部最优,从而产生幻觉。
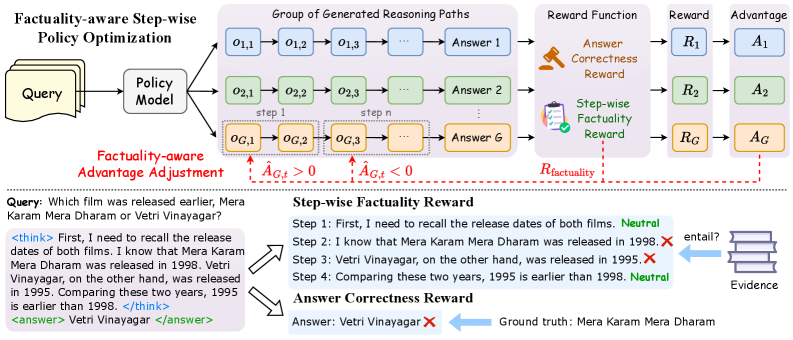
核心思路:论文的核心思路是在强化学习的训练过程中,显式地引入事实性验证机制。通过在每个推理步骤中验证生成内容的真实性,并根据验证结果动态调整策略,从而激励模型生成更符合事实的内容。这种方法旨在减少模型对虚假信息的依赖,提高推理的可靠性。
技术框架:FSPO算法的核心框架是在标准的强化学习流程中加入一个事实性验证模块。具体流程如下:1) 模型生成推理步骤;2) 事实性验证模块根据给定的证据验证该步骤的真实性;3) 根据验证结果,动态调整token级别的优势值;4) 使用调整后的优势值更新策略。整个过程迭代进行,直到模型收敛。
关键创新:FSPO算法的关键创新在于其事实性感知的优势值调整机制。传统的强化学习方法通常只关注最终结果的奖励,而忽略了中间步骤的真实性。FSPO通过在每个步骤中进行事实性验证,并将验证结果融入到优势值计算中,从而更精细地控制模型的行为,鼓励模型生成更符合事实的推理路径。
关键设计:FSPO算法的关键设计包括:1) 事实性验证模块的实现方式,可以使用现有的知识库或信息检索系统;2) 优势值调整策略,需要根据验证结果设计合适的奖励函数,以平衡推理准确性和事实性;3) token级别的优势值调整,允许更细粒度的控制,可以针对每个token的生成进行优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FSPO算法在Qwen2.5和Llama模型上,能够有效减少幻觉,同时提高推理准确性。在数学推理任务和幻觉基准测试中,FSPO算法均取得了显著的性能提升,验证了其有效性。具体数据(原文未提供)表明,FSPO在减少幻觉方面的提升幅度显著,同时保持或略微提升了推理准确性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性和准确性的推理场景,例如:医疗诊断、金融分析、法律咨询等。通过减少模型幻觉,可以提高决策的质量和安全性,避免因错误信息导致的风险。未来,该方法还可以扩展到其他类型的生成任务,例如:文本摘要、机器翻译等,以提高生成内容的真实性和可靠性。
📄 摘要(原文)
Large language models (LLMs) have significantly advanced in reasoning tasks through reinforcement learning (RL) optimization, achieving impressive capabilities across various challenging benchmarks. However, our empirical analysis reveals a critical drawback: reasoning-oriented RL fine-tuning significantly increases the prevalence of hallucinations. We theoretically analyze the RL training dynamics, identifying high-variance gradient, entropy-induced randomness, and susceptibility to spurious local optima as key factors leading to hallucinations. To address this drawback, we propose Factuality-aware Step-wise Policy Optimization (FSPO), an innovative RL fine-tuning algorithm incorporating explicit factuality verification at each reasoning step. FSPO leverages automated verification against given evidence to dynamically adjust token-level advantage values, incentivizing factual correctness throughout the reasoning process. Experiments across mathematical reasoning and hallucination benchmarks using Qwen2.5 and Llama models demonstrate that FSPO effectively reduces hallucinations while enhancing reasoning accuracy, substantially improving both reliability and performance.