GATE: General Arabic Text Embedding for Enhanced Semantic Textual Similarity with Matryoshka Representation Learning and Hybrid Loss Training
作者: Omer Nacar, Anis Koubaa, Serry Sibaee, Yasser Al-Habashi, Adel Ammar, Wadii Boulila
分类: cs.CL
发布日期: 2025-05-30
💡 一句话要点
GATE:面向阿拉伯语的通用文本嵌入,通过Matryoshka表示学习和混合损失训练提升语义文本相似度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 阿拉伯语 语义文本相似度 文本嵌入 Matryoshka表示学习 混合损失训练 自然语言推理 预训练模型
📋 核心要点
- 阿拉伯语语义文本相似度研究受限于高质量数据集和预训练模型的匮乏,阻碍了相关任务的性能提升。
- GATE模型采用Matryoshka表示学习和混合损失训练,利用阿拉伯语三元组数据集进行自然语言推理,提升模型语义理解能力。
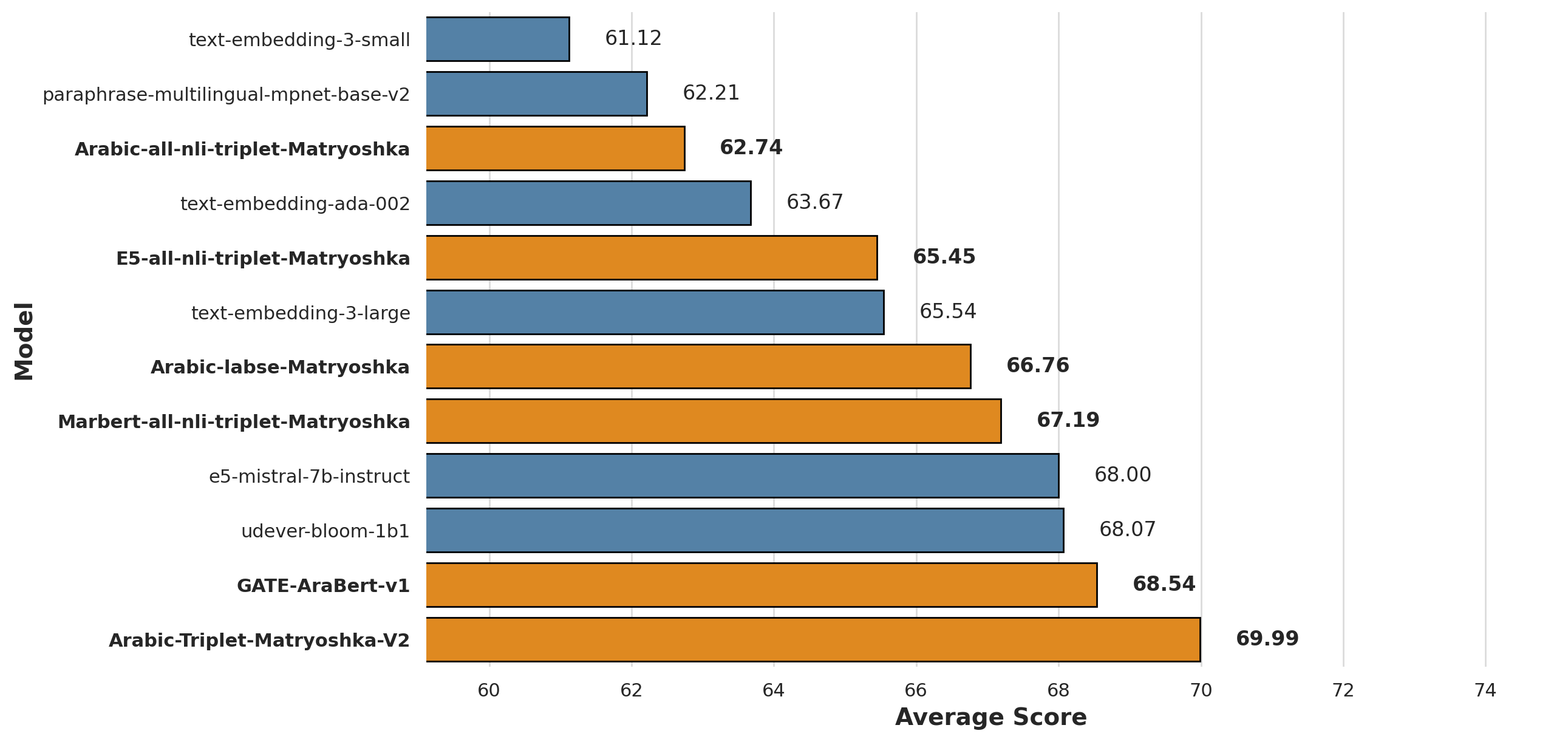
- 实验结果表明,GATE模型在STS基准测试中显著优于现有模型,包括OpenAI,性能提升达20-25%。
📝 摘要(中文)
语义文本相似度(STS)是自然语言处理(NLP)中的一项关键任务,它支持检索、聚类和理解文本之间语义关系等应用。然而,由于缺乏高质量的数据集和预训练模型,阿拉伯语在该领域的研究仍然有限。这种资源的稀缺限制了阿拉伯语文本中语义相似度的准确评估和发展。本文介绍了通用阿拉伯语文本嵌入(GATE)模型,该模型在MTEB基准测试中的语义文本相似度任务上实现了最先进的性能。GATE利用Matryoshka表示学习和带有阿拉伯语三元组数据集的混合损失训练方法,用于自然语言推理,这对于提高模型在需要细粒度语义理解的任务中的性能至关重要。GATE优于包括OpenAI在内的大型模型,在STS基准测试中性能提高了20-25%,有效地捕捉了阿拉伯语独特的语义细微差别。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语语义文本相似度(STS)任务中,由于缺乏高质量数据集和预训练模型而导致的性能瓶颈问题。现有方法难以准确捕捉阿拉伯语的语义细微差别,限制了STS在阿拉伯语NLP应用中的发展。
核心思路:论文的核心思路是利用Matryoshka表示学习和混合损失训练,结合阿拉伯语自然语言推理(NLI)三元组数据集,从而提升模型对阿拉伯语语义的理解能力。Matryoshka表示学习允许模型学习不同维度的文本表示,混合损失训练则结合了多种损失函数,以优化模型的不同方面。
技术框架:GATE模型的整体框架包括以下几个主要模块:1) 文本编码器:使用预训练的阿拉伯语Transformer模型作为文本编码器,将输入的阿拉伯语文本转换为向量表示。2) Matryoshka表示学习:通过调整编码器的输出维度,学习不同粒度的文本表示。3) 混合损失训练:结合多种损失函数,例如对比损失、三元组损失等,以优化模型的语义表示能力。4) 自然语言推理数据集:使用阿拉伯语NLI数据集进行训练,以提高模型对语义关系的理解。
关键创新:GATE模型的关键创新在于将Matryoshka表示学习和混合损失训练应用于阿拉伯语语义文本相似度任务。Matryoshka表示学习允许模型学习多尺度的文本表示,从而更好地捕捉阿拉伯语的语义细微差别。混合损失训练则结合了多种损失函数的优点,从而优化模型的整体性能。与现有方法相比,GATE模型能够更有效地利用有限的阿拉伯语资源,并取得更好的性能。
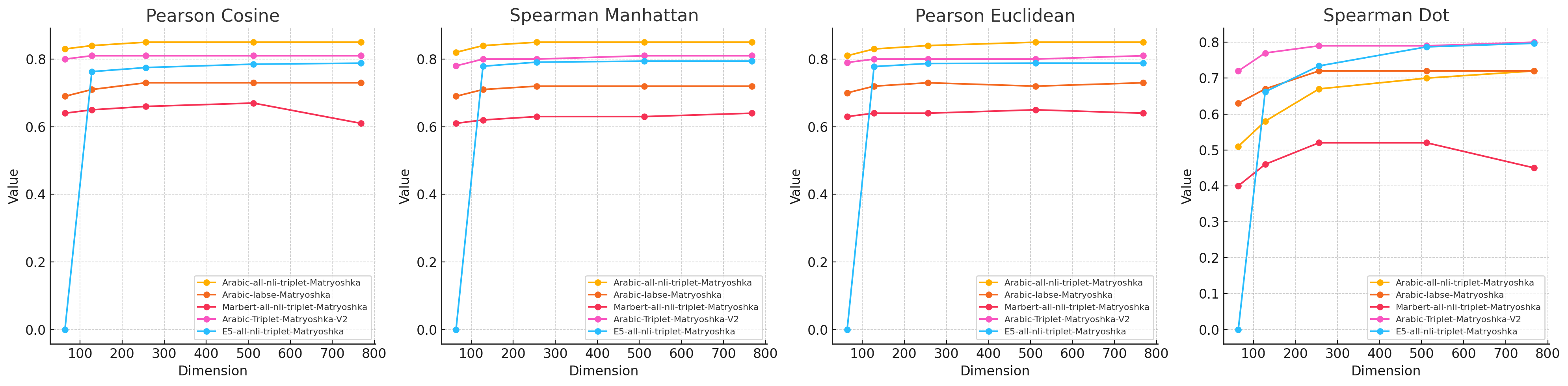
关键设计:GATE模型的关键设计包括:1) 使用预训练的阿拉伯语Transformer模型,例如AraBERT,作为文本编码器。2) 采用Matryoshka表示学习,学习不同维度的文本表示,例如128维、256维、512维等。3) 使用混合损失函数,包括对比损失、三元组损失和交叉熵损失等。4) 使用阿拉伯语NLI数据集进行训练,以提高模型对语义关系的理解。具体的损失函数权重和训练参数需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
GATE模型在MTEB基准测试的STS任务上取得了最先进的性能,显著优于现有模型,包括OpenAI的模型。具体而言,GATE模型在STS基准测试中实现了20-25%的性能提升,表明其能够更有效地捕捉阿拉伯语的语义细微差别。这些实验结果证明了GATE模型在阿拉伯语语义文本相似度任务中的有效性和优越性。
🎯 应用场景
GATE模型在信息检索、文本聚类、问答系统、机器翻译等领域具有广泛的应用前景。它可以用于提高阿拉伯语文本检索的准确性,改进阿拉伯语文本聚类的效果,提升阿拉伯语问答系统的性能,以及改善阿拉伯语机器翻译的质量。该研究有助于推动阿拉伯语自然语言处理技术的发展,并为相关应用提供更强大的支持。
📄 摘要(原文)
Semantic textual similarity (STS) is a critical task in natural language processing (NLP), enabling applications in retrieval, clustering, and understanding semantic relationships between texts. However, research in this area for the Arabic language remains limited due to the lack of high-quality datasets and pre-trained models. This scarcity of resources has restricted the accurate evaluation and advance of semantic similarity in Arabic text. This paper introduces General Arabic Text Embedding (GATE) models that achieve state-of-the-art performance on the Semantic Textual Similarity task within the MTEB benchmark. GATE leverages Matryoshka Representation Learning and a hybrid loss training approach with Arabic triplet datasets for Natural Language Inference, which are essential for enhancing model performance in tasks that demand fine-grained semantic understanding. GATE outperforms larger models, including OpenAI, with a 20-25% performance improvement on STS benchmarks, effectively capturing the unique semantic nuances of Arabic.