Bench4KE: Benchmarking Automated Competency Question Generation
作者: Anna Sofia Lippolis, Minh Davide Ragagni, Paolo Ciancarini, Andrea Giovanni Nuzzolese, Valentina Presutti
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2025-12-09)
💡 一句话要点
Bench4KE:用于自动胜任力问题生成的基准测试系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识工程 胜任力问题生成 基准测试 大型语言模型 本体工程
📋 核心要点
- 现有胜任力问题(CQ)生成工具的评估缺乏标准化,阻碍了研究的复现和比较。
- Bench4KE提供了一个API驱动的基准测试系统,用于评估和比较自动CQ生成工具。
- 通过对6个LLM驱动的CQ生成系统进行分析,Bench4KE为未来研究建立了性能基线。
📝 摘要(中文)
大型语言模型(LLM)的出现为知识工程(KE)自动化研究带来了独特的机会。目前已经涌现出许多基于LLM的方法和工具,用于自动生成胜任力问题(CQ),这些问题是本体工程师用来定义本体功能需求的自然语言问题。然而,这些工具的评估缺乏标准化,这削弱了方法论的严谨性,并阻碍了结果的复制和比较。为了解决这个问题,我们推出了Bench4KE,一个基于API的可扩展的KE自动化基准测试系统。本次发布侧重于评估自动生成CQ的工具。Bench4KE提供了一个精心策划的黄金标准,包含来自17个真实世界本体工程项目的CQ数据集,并使用一套相似性指标来评估生成的CQ的质量。我们对6个基于LLM的最新CQ生成系统进行了比较分析,为未来的研究建立了基线。Bench4KE还被设计用于适应其他的KE自动化任务,例如SPARQL查询生成、本体测试和草拟。代码和数据集已根据Apache 2.0许可证公开。
🔬 方法详解
问题定义:论文旨在解决知识工程领域中,自动胜任力问题(CQ)生成工具缺乏标准化评估的问题。现有方法难以进行公平比较和复现,阻碍了该领域的发展。
核心思路:论文的核心思路是构建一个可扩展的基准测试系统Bench4KE,该系统提供标准化的数据集和评估指标,以便对不同的CQ生成工具进行客观、一致的评估。通过提供统一的评估平台,促进该领域的研究进展。
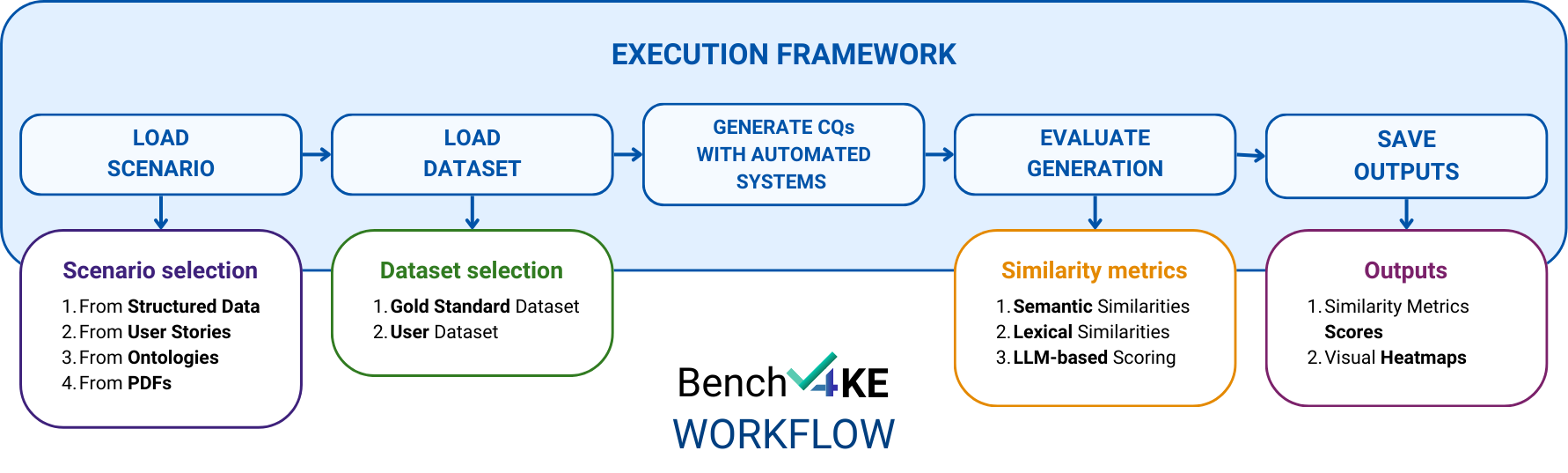
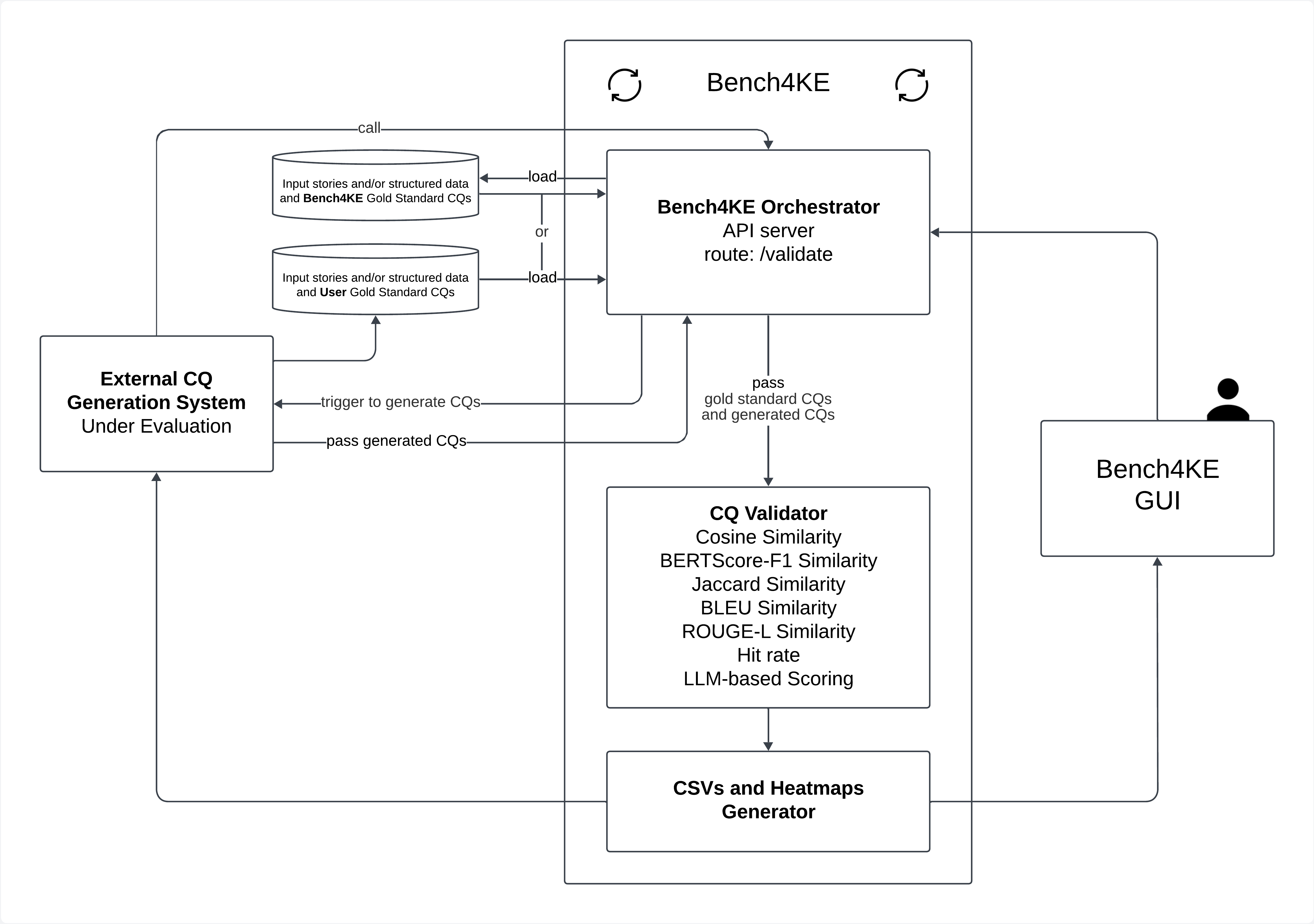
技术框架:Bench4KE是一个基于API的系统,主要包含以下几个模块:1) 数据集管理模块:提供来自17个真实世界本体工程项目的CQ数据集;2) 评估指标模块:包含一套相似性指标,用于评估生成的CQ的质量;3) 系统接口模块:提供API接口,方便用户提交CQ生成结果并进行评估;4) 结果展示模块:展示不同CQ生成工具的评估结果,并进行比较分析。
关键创新:Bench4KE的关键创新在于其提供了一个标准化的、可扩展的基准测试平台,用于评估自动CQ生成工具。与以往研究相比,Bench4KE更加注重评估的客观性和可复现性,并提供了一套全面的评估指标。
关键设计:Bench4KE的关键设计包括:1) 精心策划的CQ数据集,涵盖了不同领域的本体工程项目;2) 多种相似性指标,包括词汇相似度、语义相似度等,以全面评估生成的CQ的质量;3) 可扩展的API接口,方便用户集成自己的CQ生成工具并进行评估;4) 清晰易懂的结果展示界面,方便用户比较不同工具的性能。
🖼️ 关键图片
📊 实验亮点
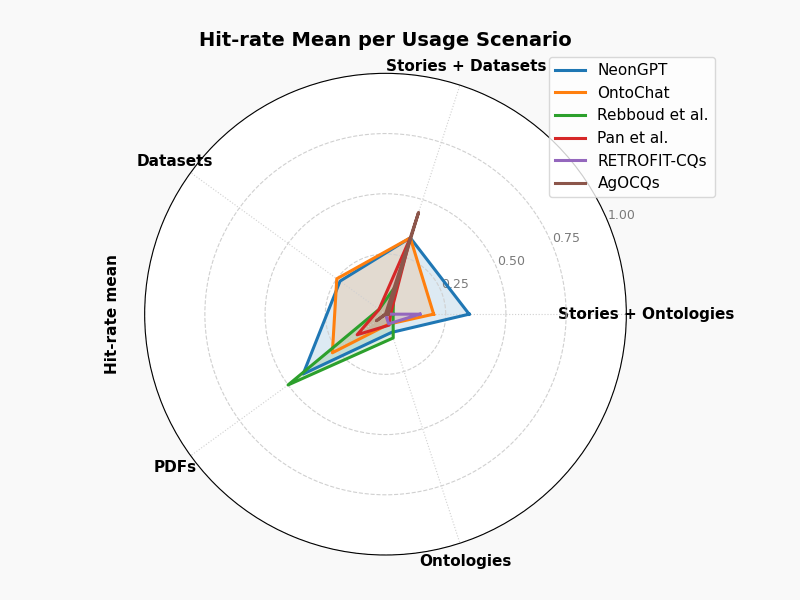
论文通过Bench4KE对6个基于LLM的CQ生成系统进行了比较分析,结果表明不同系统在不同数据集上的性能差异显著。Bench4KE为未来的CQ生成研究提供了一个可靠的基线,并为研究者提供了一个评估和比较新方法的平台。实验结果也揭示了现有CQ生成方法的一些局限性,为未来的研究方向提供了启示。
🎯 应用场景
Bench4KE可应用于知识工程、语义网、本体构建等领域。它可以帮助本体工程师选择合适的CQ生成工具,提高本体构建的效率和质量。此外,Bench4KE还可以促进CQ生成算法的改进和创新,推动知识工程领域的发展。未来,Bench4KE可以扩展到其他知识工程自动化任务,例如SPARQL查询生成和本体测试。
📄 摘要(原文)
The availability of Large Language Models (LLMs) presents a unique opportunity to reinvigorate research on Knowledge Engineering (KE) automation. This trend is already evident in recent efforts developing LLM-based methods and tools for the automatic generation of Competency Questions (CQs), natural language questions used by ontology engineers to define the functional requirements of an ontology. However, the evaluation of these tools lacks standardization. This undermines the methodological rigor and hinders the replication and comparison of results. To address this gap, we introduce Bench4KE, an extensible API-based benchmarking system for KE automation. The presented release focuses on evaluating tools that generate CQs automatically. Bench4KE provides a curated gold standard consisting of CQ datasets from 17 real-world ontology engineering projects and uses a suite of similarity metrics to assess the quality of the CQs generated. We present a comparative analysis of 6 recent CQ generation systems, which are based on LLMs, establishing a baseline for future research. Bench4KE is also designed to accommodate additional KE automation tasks, such as SPARQL query generation, ontology testing and drafting. Code and datasets are publicly available under the Apache 2.0 license.