Cross-Attention Speculative Decoding
作者: Wei Zhong, Manasa Bharadwaj, Yixiao Wang, Nikhil Verma, Yipeng Ji, Chul Lee
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2025-09-22)
💡 一句话要点
提出基于交叉注意力的推测解码模型Beagle,简化架构并提升训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 交叉注意力 大型语言模型 模型加速 Transformer解码器
📋 核心要点
- 现有推测解码方法依赖复杂的自注意力Transformer解码器,泛化能力受限且训练成本高昂。
- Beagle采用交叉注意力机制,简化了模型架构,无需额外的池化或融合层,降低了复杂度。
- 实验表明,Beagle在推理速度上与现有方法相当,同时显著提升了训练效率,并保持内存稳定。
📝 摘要(中文)
推测解码(SD)是加速大型语言模型(LLM)推理的常用方法,尤其是在草稿模型和目标模型对齐良好的情况下。然而,目前最先进的SD方法通常依赖于紧密耦合的、基于自注意力的Transformer解码器,并经常辅以辅助池化或融合层。这种耦合使得它们越来越复杂,并且更难在不同的模型中推广。我们提出了Budget EAGLE (Beagle),据我们所知,它是第一个基于交叉注意力的Transformer解码器SD模型,它在性能上与领先的自注意力SD模型(EAGLE-v2)相当,同时消除了对池化或辅助组件的需求,简化了架构,提高了训练效率,并在训练时模拟期间保持了稳定的内存使用。为了实现这种新型架构的有效训练,我们提出了一种新的两阶段块注意力训练方法,该方法在块级注意力场景中实现了训练稳定性和收敛效率。在多个LLM和数据集上的大量实验表明,Beagle实现了与EAGLE-v2相比具有竞争力的推理加速和更高的训练效率,为推测解码中的架构提供了一个强大的替代方案。
🔬 方法详解
问题定义:现有推测解码方法,如EAGLE-v2,依赖于复杂的自注意力Transformer解码器,这些解码器通常需要额外的池化或融合层。这种复杂性使得模型难以泛化到不同的架构,并且训练成本较高。此外,训练过程中内存占用不稳定也是一个挑战。
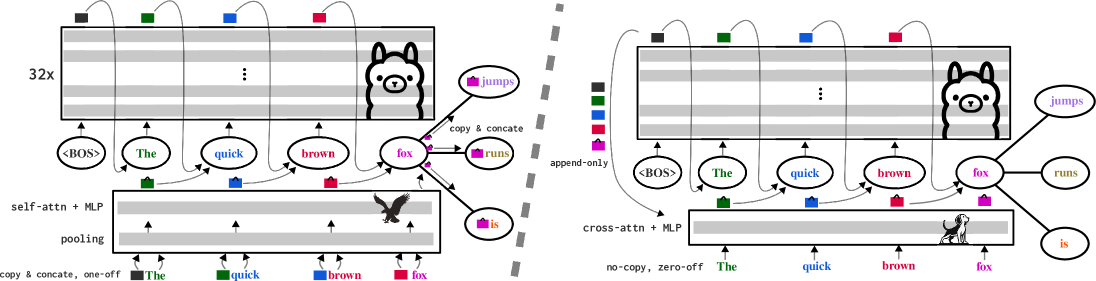
核心思路:Beagle的核心思路是使用交叉注意力机制来替代传统的自注意力机制,从而简化模型架构。通过解耦草稿模型和目标模型,Beagle能够更灵活地适应不同的模型,并降低训练的复杂性。交叉注意力允许模型在生成草稿时关注目标模型的上下文信息,从而提高草稿的质量。
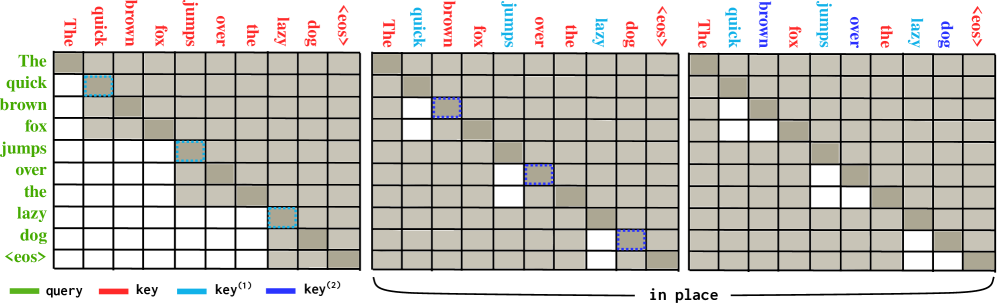
技术框架:Beagle的整体架构包括一个草稿模型和一个目标模型。草稿模型使用交叉注意力机制生成草稿序列,目标模型验证草稿序列并进行修正。训练过程分为两个阶段:首先,使用两阶段块注意力训练方法预训练草稿模型,以提高其生成高质量草稿的能力;然后,联合训练草稿模型和目标模型,以优化整体性能。
关键创新:Beagle的关键创新在于使用交叉注意力机制进行推测解码,这是首个基于交叉注意力的Transformer解码器SD模型。此外,提出的两阶段块注意力训练方法能够有效解决块级注意力场景下的训练稳定性和收敛效率问题。
关键设计:Beagle的关键设计包括:1) 使用交叉注意力层替代自注意力层;2) 采用两阶段块注意力训练方法,包括预训练阶段和联合训练阶段;3) 设计合适的损失函数,以优化草稿模型的生成质量和目标模型的验证准确率。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
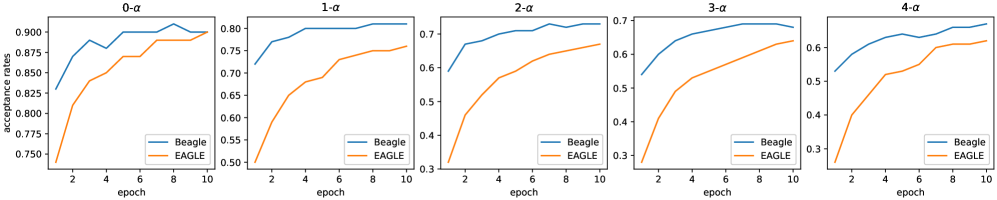
Beagle在多个LLM和数据集上进行了广泛的实验,结果表明,Beagle在推理速度上与EAGLE-v2等领先的自注意力SD模型具有竞争力,同时显著提高了训练效率。具体的性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
Beagle可应用于各种需要加速LLM推理的场景,例如在线对话系统、机器翻译、文本摘要等。其简化的架构和更高的训练效率使其更易于部署和维护,并降低了计算成本。该研究为推测解码架构提供了一个新的选择,并可能促进更高效的LLM应用。
📄 摘要(原文)
Speculative decoding (SD) is a widely adopted approach for accelerating inference in large language models (LLMs), particularly when the draft and target models are well aligned. However, state-of-the-art SD methods typically rely on tightly coupled, self-attention-based Transformer decoders, often augmented with auxiliary pooling or fusion layers. This coupling makes them increasingly complex and harder to generalize across different models. We present Budget EAGLE (Beagle), the first, to our knowledge, cross-attention-based Transformer decoder SD model that achieves performance on par with leading self-attention SD models (EAGLE-v2) while eliminating the need for pooling or auxiliary components, simplifying the architecture, improving training efficiency, and maintaining stable memory usage during training-time simulation. To enable effective training of this novel architecture, we propose Two-Stage Block-Attention Training, a new method that achieves training stability and convergence efficiency in block-level attention scenarios. Extensive experiments across multiple LLMs and datasets show that Beagle achieves competitive inference speedups and higher training efficiency than EAGLE-v2, offering a strong alternative for architectures in speculative decoding.