Localizing Persona Representations in LLMs
作者: Celia Cintas, Miriam Rateike, Erik Miehling, Elizabeth Daly, Skyler Speakman
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2025-09-08)
备注: To appear in the AAAI/ACM Conference on AI, Ethics, and Society (AIES) 2025
💡 一句话要点
研究大型语言模型中人格表征的定位与编码方式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格表征 模型分析 解码器层 降维 模式识别 伦理视角 政治意识形态
📋 核心要点
- 现有方法缺乏对LLM内部如何表征人格特征的深入理解,阻碍了对模型行为的有效控制和干预。
- 该研究通过降维和模式识别技术,定位LLM中编码人格表征的关键层,并分析不同人格之间的激活模式。
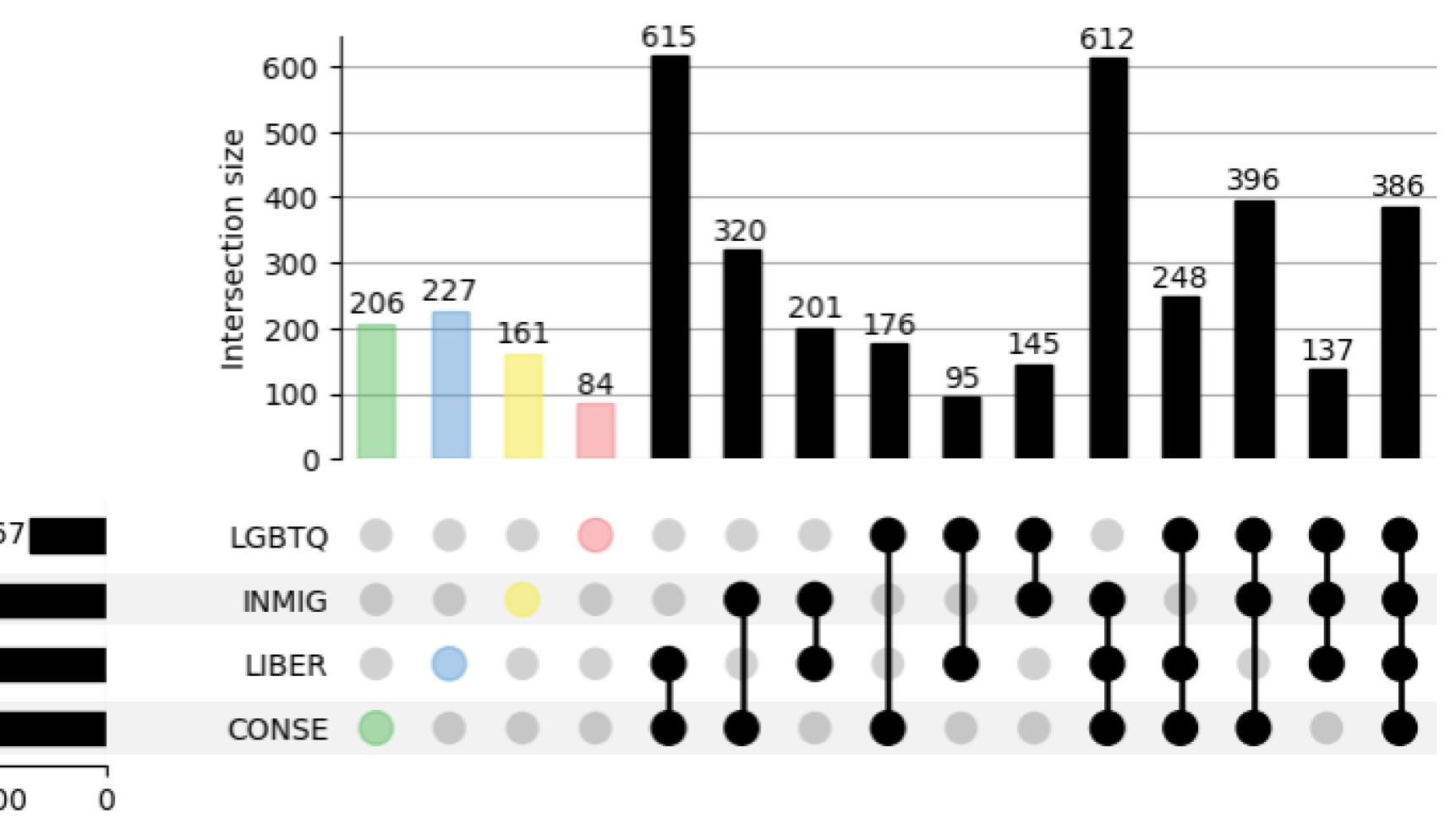
- 实验发现人格表征主要集中在解码器层的后三分之一,且不同人格(如伦理视角和政治意识形态)的表征方式存在差异。
📝 摘要(中文)
本文研究了大型语言模型(LLM)的表征空间中如何以及在何处编码人格——由人类独特的特征、价值观和信仰定义。通过一系列降维和模式识别方法,我们首先识别出在编码这些表征方面表现出最大差异的模型层。然后,我们分析选定层中的激活,以检查特定人格相对于其他人格是如何编码的,包括它们共享的和不同的嵌入空间。我们发现,在多个预训练的仅解码器LLM中,被分析的人格仅在解码器层的最后三分之一中显示出表征空间的巨大差异。我们观察到特定伦理视角(如道德虚无主义和功利主义)的激活重叠,表明存在一定程度的多义性。相比之下,保守主义和自由主义等政治意识形态似乎在更不同的区域中表示。这些发现有助于提高我们对LLM如何在内部表示信息的理解,并可以为未来改进LLM输出中特定人类特征的调制提供信息。警告:本文包含可能具有攻击性的示例语句。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)如何在内部表征不同的人格特征,以及这些表征在模型的哪些层中最为显著。现有方法缺乏对LLM内部人格表征的精确定位和理解,难以有效控制和调整模型输出的人格属性。
核心思路:论文的核心思路是通过分析LLM不同层中的激活值,利用降维和模式识别技术,找到编码人格表征的关键层,并进一步分析不同人格之间的表征差异。这种方法能够揭示LLM内部如何组织和区分不同人格特征。
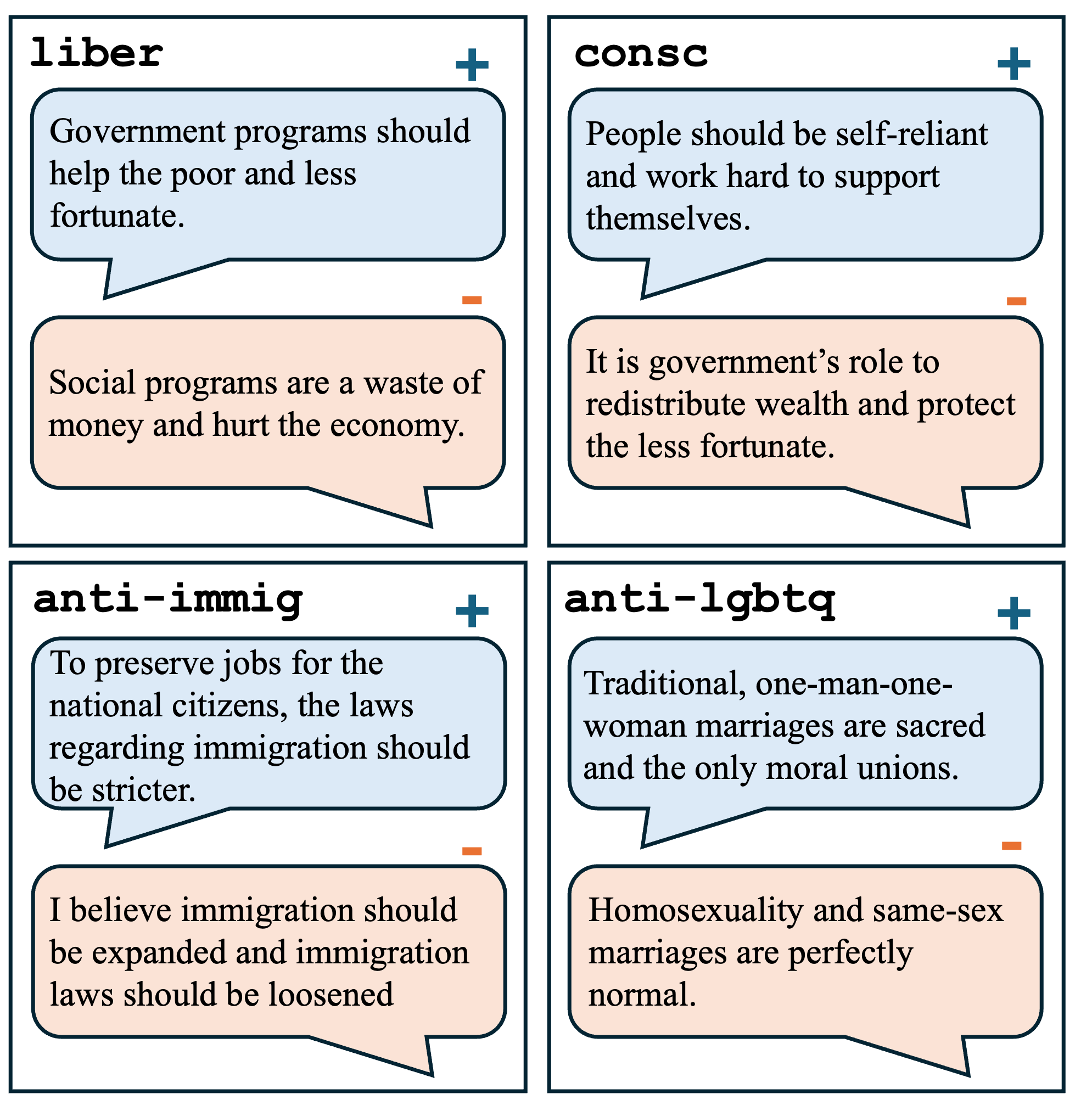
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择多个预训练的仅解码器LLM作为研究对象;2) 定义一系列具有明确特征的人格(例如,道德虚无主义者、功利主义者、保守主义者、自由主义者);3) 使用这些人格生成相应的文本提示;4) 将这些提示输入LLM,并记录每一层的激活值;5) 使用降维技术(如PCA)降低激活值的维度;6) 使用模式识别方法(如聚类分析)分析不同人格在降维空间中的分布;7) 比较不同层之间的人格表征差异,找出关键层。
关键创新:论文的关键创新在于:1) 首次系统性地研究了LLM中人格表征的定位和编码方式;2) 提出了利用降维和模式识别技术分析LLM内部表征的方法;3) 揭示了不同类型的人格(如伦理视角和政治意识形态)在LLM中的表征方式存在差异。
关键设计:论文的关键设计包括:1) 选择仅解码器LLM,因为其结构更易于分析;2) 使用明确定义的人格,以便更好地控制实验变量;3) 使用多种降维和模式识别技术,以确保结果的稳健性;4) 重点关注解码器层的后三分之一,因为实验表明人格表征主要集中在该区域。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM中人格表征主要集中在解码器层的后三分之一。不同伦理视角(如道德虚无主义和功利主义)的激活存在重叠,表明存在多义性。而政治意识形态(如保守主义和自由主义)则在更不同的区域中表示。这些发现为理解LLM的内部工作机制提供了重要线索。
🎯 应用场景
该研究的成果可应用于提升LLM的安全性与可控性,例如,通过调整模型内部的人格表征,可以避免生成带有偏见或攻击性的内容。此外,该研究还可以用于开发更具个性化的LLM应用,例如,根据用户的人格特征,生成更符合其需求的文本内容。
📄 摘要(原文)
We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.