R-KV: Redundancy-aware KV Cache Compression for Reasoning Models
作者: Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, Zhen Dong, Anima Anandkumar, Abedelkadir Asi, Junjie Hu
分类: cs.CL, cs.AI
发布日期: 2025-05-30 (更新: 2026-01-22)
💡 一句话要点
R-KV:面向推理模型,提出冗余感知的KV缓存压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 推理模型 冗余感知 思维链推理 模型优化
📋 核心要点
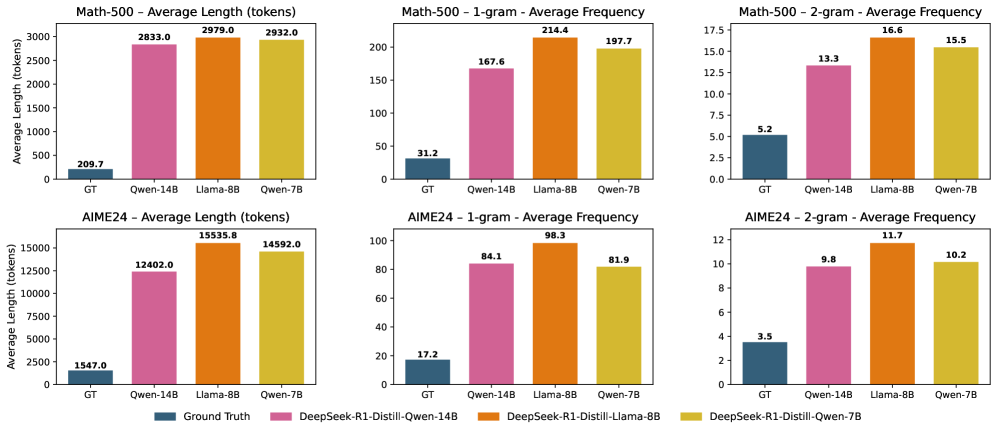
- 现有KV缓存压缩方法在思维链推理中易导致推理失败,无法有效处理冗余token。
- R-KV通过冗余感知机制,选择性地保留关键token的KV缓存,从而实现高效压缩。
- 实验表明,R-KV仅用10%的KV缓存即可达到接近100%的性能,并显著提升吞吐量。
📝 摘要(中文)
推理模型在自我反思和思维链推理方面表现出令人印象深刻的性能。然而,它们通常会产生过长的输出,导致推理过程中产生过大的键值(KV)缓存。虽然思维链推理显著提高了复杂推理任务的性能,但当与现有的KV缓存压缩方法一起部署时,也可能导致推理失败。为了解决这个问题,我们提出了一种面向推理模型的冗余感知KV缓存压缩方法(R-KV),该方法专门针对推理模型中的冗余token。我们的方法仅使用10%的KV缓存即可保留几乎100%的完整KV缓存性能,大大优于现有的KV缓存基线,后者仅达到60%的性能。值得注意的是,R-KV甚至可以使用16%的KV缓存达到完整KV缓存性能的105%。这种KV缓存减少还带来了90%的内存节省和6.6倍于标准思维链推理的吞吐量。实验结果表明,R-KV在两个数学推理数据集上始终优于现有的KV缓存压缩基线。
🔬 方法详解
问题定义:论文旨在解决推理模型中KV缓存过大的问题,尤其是在思维链推理场景下。现有KV缓存压缩方法在处理冗余token时表现不佳,容易导致推理性能下降甚至失败。这些方法无法有效区分重要token和冗余token,导致压缩过程中关键信息丢失。
核心思路:论文的核心思路是利用推理模型输出中的冗余性,设计一种冗余感知的KV缓存压缩方法。通过识别和过滤掉不重要的冗余token,只保留对推理结果有关键影响的token的KV缓存,从而在大幅减少KV缓存大小的同时,保持甚至提升推理性能。
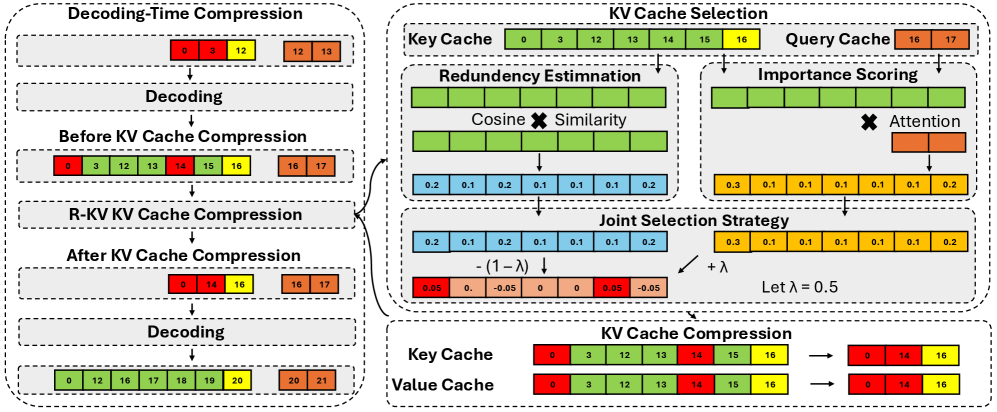
技术框架:R-KV方法的整体框架包含以下几个主要步骤:1) Token重要性评估:使用某种指标(具体细节未知)评估每个token对于最终推理结果的重要性。2) 冗余token识别:基于token重要性评估结果,识别出冗余的、不重要的token。3) KV缓存选择性保留:只保留重要token的KV缓存,丢弃冗余token的KV缓存。4) 推理执行:使用压缩后的KV缓存进行推理。
关键创新:R-KV的关键创新在于其冗余感知机制。与现有方法不同,R-KV不是简单地对KV缓存进行均匀采样或压缩,而是根据token的重要性进行选择性保留。这种方法能够更有效地利用有限的KV缓存空间,从而在压缩率和性能之间取得更好的平衡。
关键设计:论文中关于token重要性评估的具体方法、冗余token的识别阈值、以及如何将压缩后的KV缓存集成到推理过程中等技术细节,摘要中没有明确说明,属于未知信息。这些细节对于R-KV的实际性能至关重要,需要在阅读完整论文后才能了解。
🖼️ 关键图片

📊 实验亮点
R-KV在数学推理数据集上取得了显著的性能提升。实验结果表明,R-KV仅使用10%的KV缓存即可保留接近100%的完整KV缓存性能,远超现有基线方法(仅达到60%)。更令人惊讶的是,R-KV使用16%的KV缓存甚至达到了完整KV缓存性能的105%。此外,R-KV还实现了90%的内存节省和6.6倍的吞吐量提升。
🎯 应用场景
R-KV具有广泛的应用前景,可以应用于各种需要进行大规模推理的场景,例如自然语言处理、知识图谱推理、代码生成等。通过减少KV缓存的大小,R-KV可以显著降低推理成本,提高推理速度,并使得在资源受限的设备上部署大型推理模型成为可能。此外,R-KV还可以与其他模型压缩技术相结合,进一步提升推理效率。
📄 摘要(原文)
Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.