Act-Adaptive Margin: Dynamically Calibrating Reward Models for Subjective Ambiguity
作者: Feiteng Fang, Dingwei Chen, Xiang Huang, Ting-En Lin, Yuchuan Wu, Xiong Liu, Xinge Ye, Ziqiang Liu, Haonan Zhang, Liang Zhu, Hamid Alinejad-Rokny, Min Yang, Yongbin Li
分类: cs.CL, cs.AI
发布日期: 2025-05-29 (更新: 2026-01-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Act-Adaptive Margin (AAM)动态校准奖励模型,提升主观任务中奖励建模性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 奖励模型 强化学习 主观偏好 Bradley-Terry模型 动态边距 价值观对齐 角色扮演 偏好学习
📋 核心要点
- 现有奖励模型在主观任务中,尤其是在处理模糊偏好时,面临Bradley-Terry模型固有的挑战,导致对齐效果不佳。
- AAM通过利用模型内部参数知识,动态校准偏好边距,从而更有效地处理主观奖励,无需额外人工标注。
- 实验表明,AAM在RewardBench、JudgeBench和角色扮演任务中显著提升了奖励建模性能,并在下游对齐任务中取得了SOTA结果。
📝 摘要(中文)
目前,大多数强化学习任务集中在数学和编程等领域,这些领域的验证相对简单。然而,在角色扮演等主观任务中,对齐技术难以取得进展,这主要是因为使用Bradley-Terry模型进行主观奖励建模在处理模糊偏好时面临重大挑战。为了改进主观任务中的奖励建模,本文提出了Act-Adaptive Margin (AAM),它通过使用模型的内部参数知识动态校准偏好边距来增强奖励建模。我们设计了AAM的两个版本,它们可以有效地生成上下文相关的偏好差距,而无需额外的人工标注。这种方法从根本上改进了奖励模型处理主观奖励的方式,通过更好地将生成理解与偏好评分相结合。为了验证AAM在主观奖励建模中的有效性,我们在RewardBench、JudgeBench和具有挑战性的角色扮演任务上进行了评估。结果表明,AAM显著提高了主观奖励建模的性能,在一般任务中将Bradley-Terry奖励模型提高了2.95%,在主观角色扮演任务中提高了4.85%。此外,使用AAM训练的奖励模型可以帮助下游对齐任务获得更好的结果。我们的测试结果表明,将AAM增强的RM生成的奖励应用于偏好学习技术(例如,GRPO)可以在CharacterEval和Charm上获得最先进的结果。代码和数据集可在https://github.com/calubkk/AAM获取。
🔬 方法详解
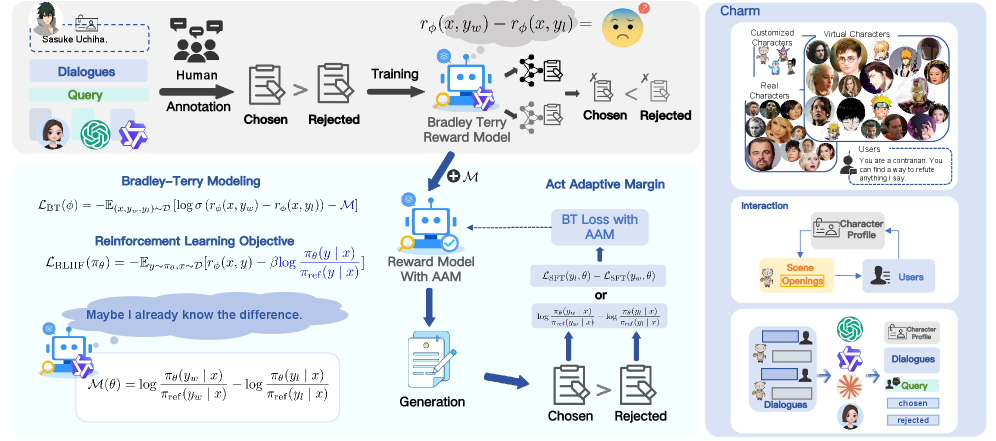
问题定义:论文旨在解决主观任务中奖励建模的难题,特别是当偏好模糊不清时,现有基于Bradley-Terry模型的奖励模型表现不佳。这些模型难以准确捕捉人类主观偏好,导致强化学习智能体在角色扮演等任务中无法有效对齐人类价值观。现有方法的痛点在于无法动态调整偏好边距以适应不同的行为和上下文。
核心思路:论文的核心思路是提出Act-Adaptive Margin (AAM),它根据模型的内部参数知识,动态地校准偏好边距。AAM的核心在于,它能够根据当前的行为(Act)自适应地调整奖励模型对不同偏好的区分度(Margin)。这种动态调整使得模型能够更好地捕捉主观偏好中的细微差别,从而提高奖励建模的准确性。这样设计的目的是为了让奖励模型能够更灵活地适应不同的上下文和行为,从而更好地反映人类的主观偏好。
技术框架:AAM的技术框架主要包括以下几个阶段:1) 行为编码:将智能体的行为编码成向量表示。2) 偏好边距校准:利用模型的内部参数知识,根据行为向量动态地调整偏好边距。论文提出了两种AAM版本,具体实现方式未知。3) 奖励预测:使用校准后的偏好边距,预测不同行为的奖励值。4) 模型训练:使用预测的奖励值训练奖励模型。
关键创新:AAM最重要的技术创新点在于其动态校准偏好边距的能力。与现有方法相比,AAM能够根据当前的行为自适应地调整偏好边距,从而更好地捕捉主观偏好中的细微差别。这种动态调整是现有方法所不具备的,也是AAM能够显著提高奖励建模性能的关键。
关键设计:关于AAM的关键设计细节,论文摘要中并未详细说明,例如具体的参数设置、损失函数以及网络结构等。但是,可以推断,AAM的设计重点在于如何有效地利用模型的内部参数知识来动态地校准偏好边距。具体的技术细节(例如,如何将行为编码成向量表示,以及如何利用模型的内部参数知识来调整偏好边距)需要参考论文全文才能进一步了解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AAM在RewardBench和JudgeBench等基准测试中显著提高了奖励建模的性能。具体来说,AAM在一般任务中将Bradley-Terry奖励模型提高了2.95%,在主观角色扮演任务中提高了4.85%。更重要的是,使用AAM训练的奖励模型可以帮助下游对齐任务获得更好的结果,例如在CharacterEval和Charm上取得了SOTA结果。这些结果充分证明了AAM在主观奖励建模方面的有效性。
🎯 应用场景
AAM具有广泛的应用前景,尤其是在需要处理主观偏好的领域,如角色扮演游戏、对话系统、个性化推荐等。通过更准确地建模人类的主观偏好,AAM可以帮助智能体更好地理解人类意图,从而提供更符合人类期望的服务。此外,AAM还可以应用于价值观对齐,帮助智能体更好地与人类价值观对齐,从而避免产生不符合伦理道德的行为。
📄 摘要(原文)
Currently, most reinforcement learning tasks focus on domains like mathematics and programming, where verification is relatively straightforward. However, in subjective tasks such as role-playing, alignment techniques struggle to make progress, primarily because subjective reward modeling using the Bradley-Terry model faces significant challenges when dealing with ambiguous preferences. To improve reward modeling in subjective tasks, this paper proposes AAM (\textbf{\underline{A}}ct-\textbf{\underline{A}}daptive \textbf{\underline{M}}argin), which enhances reward modeling by dynamically calibrating preference margins using the model's internal parameter knowledge. We design two versions of AAM that efficiently generate contextually-appropriate preference gaps without additional human annotation. This approach fundamentally improves how reward models handle subjective rewards by better integrating generative understanding with preference scoring. To validate AAM's effectiveness in subjective reward modeling, we conduct evaluations on RewardBench, JudgeBench, and challenging role-playing tasks. Results show that AAM significantly improves subjective reward modeling performance, enhancing Bradley-Terry reward models by 2.95\% in general tasks and 4.85\% in subjective role-playing tasks. Furthermore, reward models trained with AAM can help downstream alignment tasks achieve better results. Our test results show that applying rewards generated by AAM-Augmented RM to preference learning techniques (e.g., GRPO) achieves state-of-the-art results on CharacterEval and Charm. Code and dataset are available at https://github.com/calubkk/AAM.