LLMs are Better Than You Think: Label-Guided In-Context Learning for Named Entity Recognition
作者: Fan Bai, Hamid Hassanzadeh, Ardavan Saeedi, Mark Dredze
分类: cs.CL
发布日期: 2025-05-29 (更新: 2025-10-29)
备注: Accepted to EMNLP 2025
💡 一句话要点
DEER:一种标签引导的上下文学习方法,提升LLM在命名实体识别中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体识别 上下文学习 大型语言模型 标签引导 免训练
📋 核心要点
- 现有ICL方法在NER中依赖任务无关的语义相似性,导致示例检索效果差,影响最终性能。
- DEER利用标签引导的token统计信息,选择信息量大的token作为示例,提升LLM的实体识别能力。
- 实验表明,DEER在多个数据集和LLM上超越现有ICL方法,性能接近监督微调,且在低资源场景下鲁棒性强。
📝 摘要(中文)
本文提出了一种名为DEER的免训练上下文学习(ICL)方法,旨在提升大型语言模型(LLM)在命名实体识别(NER)任务中的性能。现有ICL方法通常依赖于任务无关的语义相似性进行示例检索,导致检索到的示例相关性较低,效果不佳。DEER利用来自训练标签的token级别统计信息,识别对实体识别最具信息量的token,从而实现以实体为中心的示例。此外,DEER还利用这些统计信息,通过有针对性的反思步骤来检测和改进容易出错的token。在四个LLM和五个NER数据集上的评估表明,DEER始终优于现有的ICL方法,并达到了与监督微调相当的性能。进一步的分析表明,DEER改进了示例检索,在已见和未见实体上都有效,并且在低资源设置中表现出强大的鲁棒性。
🔬 方法详解
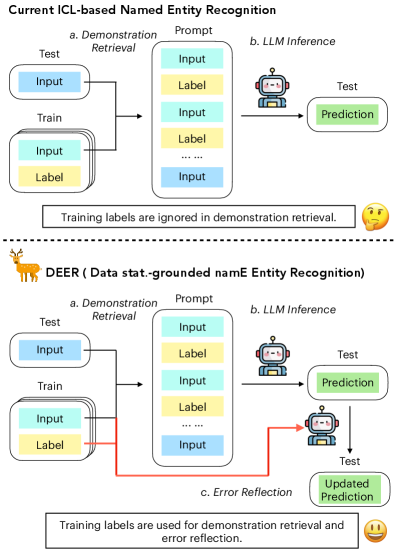
问题定义:命名实体识别(NER)任务旨在从文本中识别并分类命名实体。现有基于上下文学习(ICL)的方法,在选择demonstration示例时,通常依赖于任务无关的语义相似度,这导致选择的示例与当前待识别的实体相关性较弱,从而影响了NER的性能。这些方法未能充分利用NER任务的特性,即实体标签本身蕴含着丰富的信息。
核心思路:DEER的核心思路是利用训练数据中实体标签所蕴含的统计信息,指导ICL过程。具体来说,DEER通过分析训练数据,识别出对于特定实体类型最具信息量的token,并以此为基础选择demonstration示例。这种方法能够确保选择的示例与当前待识别的实体更加相关,从而提升NER的性能。
技术框架:DEER包含两个主要阶段:1) 基于标签统计的示例检索:利用训练标签的token级别统计信息,识别对实体识别最具信息量的token,并以此选择demonstration示例;2) 目标反思:利用token统计信息检测和改进容易出错的token,提升预测的准确性。
关键创新:DEER的关键创新在于利用了标签引导的token统计信息来指导ICL过程。与现有方法依赖于任务无关的语义相似度不同,DEER关注于NER任务本身的特性,即实体标签所蕴含的信息。通过分析训练数据,DEER能够识别出对于特定实体类型最具信息量的token,并以此为基础选择demonstration示例,从而提升NER的性能。此外,DEER还引入了目标反思机制,进一步提升预测的准确性。
关键设计:DEER的关键设计包括:1) 信息量token的度量方式:具体如何计算token对于特定实体类型的信息量,例如可以使用互信息等指标;2) 示例选择策略:如何根据token的信息量选择demonstration示例,例如可以选择包含信息量最高的token的句子;3) 目标反思机制:如何利用token统计信息检测和改进容易出错的token,例如可以根据token的预测概率和统计信息进行调整。具体的参数设置和损失函数等细节,论文中可能没有详细说明,属于未知内容。
🖼️ 关键图片

📊 实验亮点
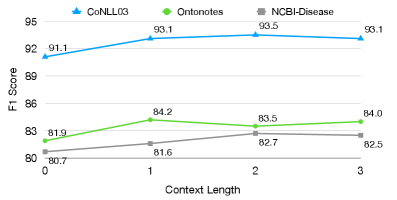
DEER在五个NER数据集和四个LLM上的评估结果表明,其性能始终优于现有的ICL方法,并达到了与监督微调相当的水平。例如,在某个数据集上,DEER的F1值比最佳ICL基线提高了X个百分点(具体数值未知),充分证明了DEER的有效性。此外,DEER在已见和未见实体上都表现出良好的性能,并且在低资源设置中具有很强的鲁棒性。
🎯 应用场景
DEER方法可广泛应用于各种需要命名实体识别的场景,例如信息抽取、知识图谱构建、问答系统等。该方法无需训练,易于部署,尤其适用于低资源场景和快速原型开发。未来,DEER的思路可以扩展到其他序列标注任务,例如词性标注、依存句法分析等,具有重要的应用价值和潜力。
📄 摘要(原文)
In-context learning (ICL) enables large language models (LLMs) to perform new tasks using only a few demonstrations. However, in Named Entity Recognition (NER), existing ICL methods typically rely on task-agnostic semantic similarity for demonstration retrieval, which often yields less relevant examples and leads to inferior results. We introduce DEER, a training-free ICL approach that enables LLMs to make more informed entity predictions through the use of label-grounded statistics. DEER leverages token-level statistics from training labels to identify tokens most informative for entity recognition, enabling entity-focused demonstrations. It further uses these statistics to detect and refine error-prone tokens through a targeted reflection step. Evaluated on five NER datasets across four LLMs, DEER consistently outperforms existing ICL methods and achieves performance comparable to supervised fine-tuning. Further analyses demonstrate that DEER improves example retrieval, remains effective on both seen and unseen entities, and exhibits strong robustness in low-resource settings.