Don't Take the Premise for Granted: Evaluating the Premise Critique Ability of Large Language Models
作者: Jinzhe Li, Gengxu Li, Yi Chang, Yuan Wu
分类: cs.CL
发布日期: 2025-05-29 (更新: 2025-11-24)
备注: EMNLP 2025 Findings camera-ready version
🔗 代码/项目: GITHUB
💡 一句话要点
提出PCBench基准测试,评估大型语言模型对错误前提的批判能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 前提批判 基准测试 错误检测 推理能力
📋 核心要点
- 现有LLMs在面对错误前提时表现出脆弱性,无法有效识别和批判输入中的缺陷。
- 论文提出PCBench基准测试,旨在系统评估LLMs对不同类型和难度错误前提的批判能力。
- 实验结果表明,LLMs在自主前提批判方面能力有限,且易受问题难度和错误类型的影响。
📝 摘要(中文)
大型语言模型(LLMs)取得了快速进展,展现出卓越的能力。然而,一个显著的弱点依然存在:LLMs经常不加批判地接受有缺陷或矛盾的前提,导致低效的推理和不可靠的输出。这突出了LLMs具备“前提批判能力”的重要性,该能力被定义为主动识别和阐明输入前提中错误的能力。现有研究大多在理想环境下评估LLMs的推理能力,很大程度上忽略了它们在面对有缺陷前提时的脆弱性。因此,我们引入了“前提批判基准”(PCBench),通过结合三种难度级别的四种错误类型,并配以多方面的评估指标来设计。我们对15个具有代表性的LLMs进行了系统评估。我们的发现表明:(1)大多数模型严重依赖显式提示来检测错误,自主批判能力有限;(2)前提批判能力取决于问题的难度和错误类型,直接矛盾比复杂或程序性错误更容易检测;(3)推理能力与前提批判能力并不一致相关;(4)有缺陷的前提会触发推理模型中的过度思考,由于反复尝试解决冲突而显着延长响应时间。这些见解强调了迫切需要加强LLMs对输入有效性的主动评估,将前提批判定位为开发可靠的、以人为中心的系统的基础能力。代码可在https://github.com/MLGroupJLU/Premise_Critique获取。
🔬 方法详解
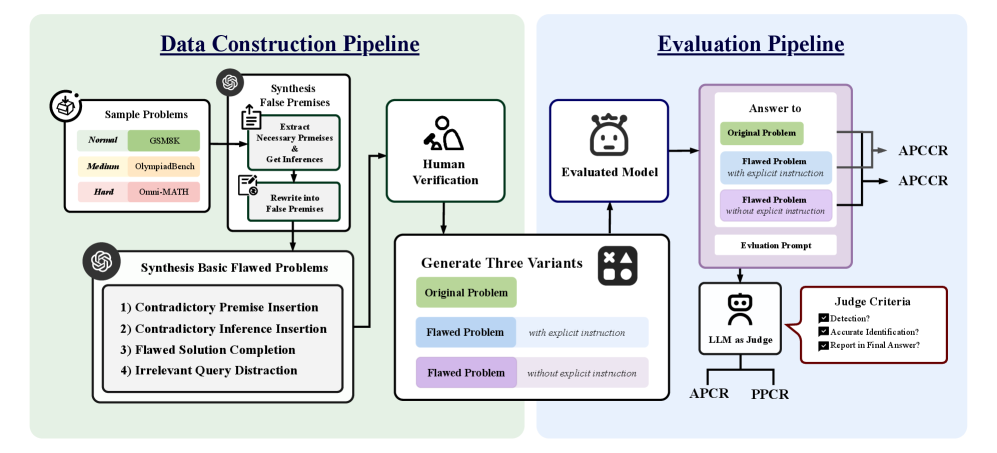
问题定义:论文旨在解决大型语言模型(LLMs)在面对错误或矛盾前提时,无法有效识别和批判这些前提的问题。现有方法主要关注LLMs在理想条件下的推理能力,忽略了其在实际应用中可能遇到的 flawed premise 问题,导致LLMs可能基于错误信息进行推理,产生不可靠的输出。
核心思路:论文的核心思路是构建一个专门用于评估LLMs前提批判能力的基准测试集(PCBench)。通过设计包含不同类型和难度级别错误前提的问题,来考察LLMs是否能够主动识别并指出这些错误,从而评估其对输入有效性的判断能力。这种设计旨在模拟真实世界中LLMs可能遇到的复杂情况,并促使LLMs发展更强的鲁棒性和可靠性。
技术框架:PCBench基准测试包含以下几个关键组成部分: 1. 错误类型定义:定义了四种不同类型的错误,例如直接矛盾、复杂错误、程序性错误等,以全面评估LLMs对不同类型错误的识别能力。 2. 难度级别设计:针对每种错误类型,设计了三种不同的难度级别,以考察LLMs在不同难度下的批判能力。 3. 评估指标:设计了多方面的评估指标,用于衡量LLMs在识别和批判错误前提方面的性能。 4. 实验评估:使用PCBench对15个具有代表性的LLMs进行了系统评估,并分析了实验结果。
关键创新:该论文的关键创新在于提出了一个专门用于评估LLMs前提批判能力的基准测试集PCBench。与以往主要关注LLMs推理能力的评估方法不同,PCBench侧重于考察LLMs对输入前提有效性的判断能力,这对于提高LLMs在实际应用中的可靠性至关重要。此外,PCBench还定义了多种错误类型和难度级别,以及多方面的评估指标,从而能够更全面地评估LLMs的前提批判能力。
关键设计:PCBench的关键设计包括: 1. 错误类型选择:选择了具有代表性的四种错误类型,以覆盖LLMs可能遇到的各种 flawed premise 情况。 2. 难度级别划分:通过调整问题的复杂度和上下文信息,设计了三种不同的难度级别,以考察LLMs在不同难度下的批判能力。 3. 评估指标设计:设计了包括准确率、召回率、F1值等多种评估指标,以全面衡量LLMs在识别和批判错误前提方面的性能。 4. 提示工程:在实验中,研究人员还探索了不同的提示策略,以考察提示对LLMs前提批判能力的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,大多数LLMs在自主前提批判方面能力有限,严重依赖显式提示来检测错误。前提批判能力受问题难度和错误类型的影响,直接矛盾更容易被检测。推理能力与前提批判能力并不一致相关。有缺陷的前提会触发推理模型的过度思考,导致响应时间延长。例如,在某些复杂错误类型上,模型的准确率低于50%。
🎯 应用场景
该研究成果可应用于提升LLMs在信息检索、问答系统、对话系统等领域的可靠性。通过提高LLMs对输入前提的批判能力,可以减少其基于错误信息进行推理的可能性,从而提高输出结果的准确性和可信度。未来,该研究可促进开发更可靠、以人为本的AI系统。
📄 摘要(原文)
Large language models (LLMs) have witnessed rapid advancements, demonstrating remarkable capabilities. However, a notable vulnerability persists: LLMs often uncritically accept flawed or contradictory premises, leading to inefficient reasoning and unreliable outputs. This emphasizes the significance of possessing the \textbf{Premise Critique Ability} for LLMs, defined as the capacity to proactively identify and articulate errors in input premises. Most existing studies assess LLMs' reasoning ability in ideal settings, largely ignoring their vulnerabilities when faced with flawed premises. Thus, we introduce the \textbf{Premise Critique Bench (PCBench)}, designed by incorporating four error types across three difficulty levels, paired with multi-faceted evaluation metrics. We conducted systematic evaluations of 15 representative LLMs. Our findings reveal: (1) Most models rely heavily on explicit prompts to detect errors, with limited autonomous critique; (2) Premise critique ability depends on question difficulty and error type, with direct contradictions being easier to detect than complex or procedural errors; (3) Reasoning ability does not consistently correlate with the premise critique ability; (4) Flawed premises trigger overthinking in reasoning models, markedly lengthening responses due to repeated attempts at resolving conflicts. These insights underscore the urgent need to enhance LLMs' proactive evaluation of input validity, positioning premise critique as a foundational capability for developing reliable, human-centric systems. The code is available at https://github.com/MLGroupJLU/Premise_Critique.