LoLA: Low-Rank Linear Attention With Sparse Caching
作者: Luke McDermott, Robert W. Heath, Rahul Parhi
分类: cs.CL, cs.LG
发布日期: 2025-05-29 (更新: 2025-09-30)
💡 一句话要点
LoLA:低秩线性注意力与稀疏缓存,提升终身学习中的关联记忆
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 稀疏缓存 终身学习 关联记忆 长序列建模
📋 核心要点
- Transformer推理成本随上下文长度增加,限制了其在终身学习中的应用,需要更高效的注意力机制。
- LoLA通过引入低秩线性注意力和稀疏缓存机制,将记忆分配到不同系统,提升关联回忆能力。
- 实验表明,LoLA在pass-key检索任务中显著提升性能,并在常识推理任务中优于其他模型。
📝 摘要(中文)
Transformer的推理成本随上下文长度增加而线性增长,限制了其在终身上下文学习中的应用。线性注意力是一种高效的替代方案,即使在无限上下文长度下也能保持恒定的内存占用。虽然它有潜力应用于终身学习,但在记忆容量方面存在不足。本文提出了LoLA,一种无需训练的线性注意力增强方法,旨在提升关联回忆能力。LoLA将上下文中的过去键值对分配到三个记忆系统中:(i)本地滑动窗口缓存中的最近键值对;(ii)稀疏全局缓存中难以记忆的键值对;(iii)线性注意力的循环隐藏状态中的通用键值对。通过消融实验表明,我们的自回忆误差指标对于有效管理长期关联记忆至关重要。在pass-key检索任务中,LoLA将基础模型的性能从0.6%提高到97.4%的准确率。在4K上下文长度下,这比Llama-3.1 8B的缓存小4.6倍。LoLA在zero-shot常识推理任务上也优于其他1B和8B参数的亚二次模型。
🔬 方法详解
问题定义:Transformer模型在处理长序列时,计算复杂度呈平方级增长,导致推理成本过高,难以应用于终身学习。线性注意力虽然降低了计算复杂度,但其记忆容量有限,无法有效存储和检索长期信息。因此,如何提升线性注意力的记忆容量,使其能够处理更长的上下文,是本文要解决的问题。
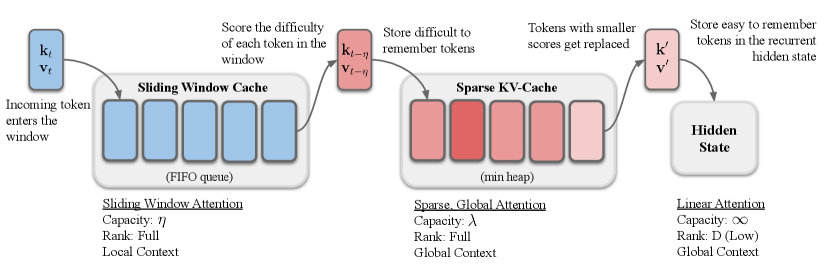
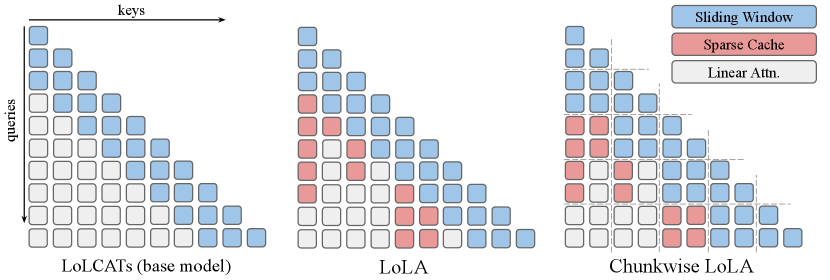
核心思路:LoLA的核心思路是将上下文中的键值对分散存储到三个不同的记忆系统中:本地滑动窗口缓存、稀疏全局缓存和循环隐藏状态。这种多级缓存结构能够更有效地管理不同类型的记忆,从而提升整体的关联回忆能力。通过自回忆误差指标来指导稀疏全局缓存的更新,保证缓存中存储的是难以记忆的关键信息。
技术框架:LoLA在标准的线性注意力机制基础上,增加了两个额外的缓存模块:本地滑动窗口缓存和稀疏全局缓存。本地滑动窗口缓存存储最近的键值对,用于快速访问。稀疏全局缓存存储难以记忆的键值对,用于长期记忆。循环隐藏状态则存储通用的键值对。在计算注意力权重时,同时考虑这三个记忆系统中的键值对。整体流程包括:输入序列经过线性注意力层,然后根据自回忆误差指标将部分键值对存储到稀疏全局缓存中,同时更新本地滑动窗口缓存和循环隐藏状态。
关键创新:LoLA的关键创新在于提出了一个多级缓存结构,并使用自回忆误差指标来指导稀疏全局缓存的更新。这种方法能够更有效地管理不同类型的记忆,从而提升整体的关联回忆能力。与传统的线性注意力相比,LoLA能够存储和检索更多的长期信息,从而更好地处理长序列任务。
关键设计:LoLA的关键设计包括:(1) 使用低秩线性注意力来降低计算复杂度;(2) 使用滑动窗口缓存来存储最近的键值对;(3) 使用稀疏全局缓存来存储难以记忆的键值对,并通过自回忆误差指标来更新缓存;(4) 使用循环隐藏状态来存储通用的键值对。自回忆误差指标的计算方式未知,论文中可能未详细描述。
🖼️ 关键图片

📊 实验亮点
LoLA在pass-key检索任务中取得了显著的性能提升,将基础模型的准确率从0.6%提高到97.4%。在4K上下文长度下,LoLA的缓存大小比Llama-3.1 8B小4.6倍。此外,LoLA在zero-shot常识推理任务上也优于其他1B和8B参数的亚二次模型,表明其具有良好的泛化能力。
🎯 应用场景
LoLA具有广泛的应用前景,尤其是在需要处理长序列和长期记忆的任务中,例如:对话系统、机器翻译、文本摘要、知识图谱推理等。该研究有望推动终身学习和持续学习领域的发展,使AI系统能够更好地适应不断变化的环境和任务。
📄 摘要(原文)
The per-token cost of transformer inference scales with context length, preventing its application to lifelong in-context learning. Linear attention is an efficient alternative that maintains a constant memory footprint, even on infinite context lengths. While this is a potential candidate for lifelong learning, it falls short in memory capacity. In this paper, we propose LoLA, a training-free augmentation to linear attention that boosts associative recall. LoLA distributes past key-value pairs from context into three memory systems: (i) recent pairs in a local sliding window cache; (ii) difficult-to-memorize pairs in a sparse, global cache; and (iii) generic pairs in the recurrent hidden state of linear attention. We show through ablations that our self-recall error metric is crucial to efficiently manage long-term associative memories. On pass-key retrieval tasks, LoLA improves the base model's performance from 0.6% to 97.4% accuracy. This is achieved with a 4.6x smaller cache than Llama-3.1 8B on 4K context length. LoLA also outperforms other 1B and 8B parameter subquadratic models on zero-shot commonsense reasoning tasks.