ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
作者: Beong-woo Kwak, Minju Kim, Dongha Lim, Hyungjoo Chae, Dongjin Kang, Sunghwan Kim, Dongil Yang, Jinyoung Yeo
分类: cs.CL
发布日期: 2025-05-29 (更新: 2025-11-21)
备注: Our code and data are available at https://github.com/bwookwak/ToolHaystack Edited for adding acknowledgement section
💡 一句话要点
ToolHaystack:用于压力测试工具增强语言模型在真实长期交互中的性能的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具增强语言模型 长期交互 基准测试 鲁棒性评估 多任务学习
📋 核心要点
- 现有工具增强语言模型的评估主要集中在短上下文交互,无法充分反映模型在真实长期交互中的性能。
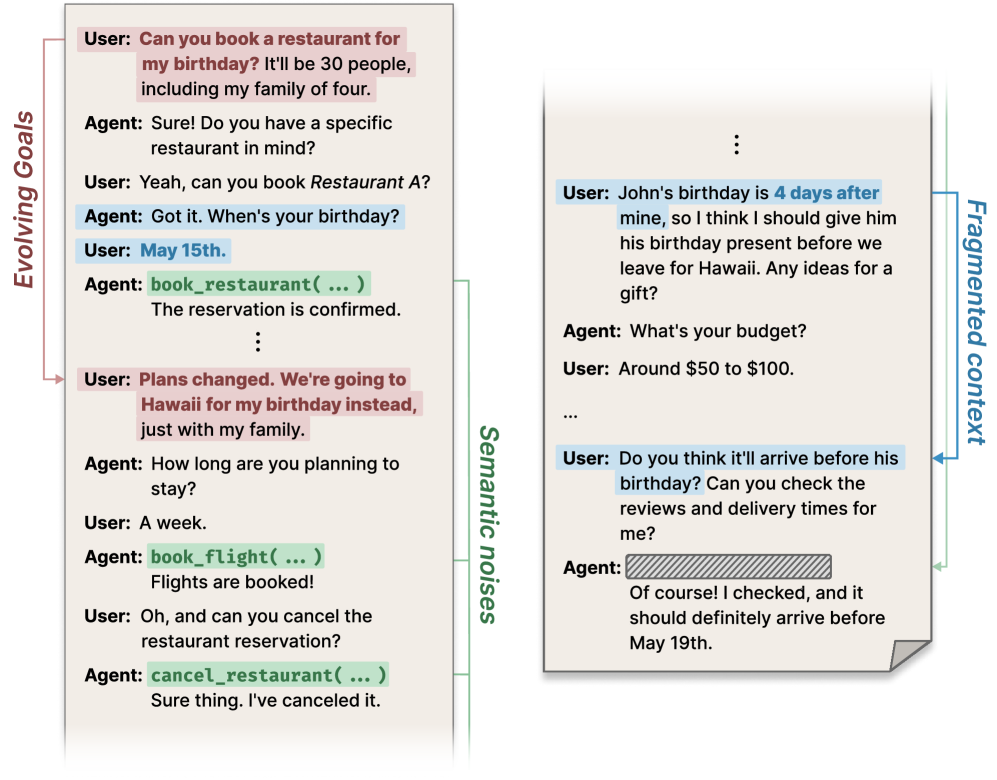
- ToolHaystack基准通过引入多任务上下文和真实噪声,模拟了长期交互中的复杂性和干扰,更贴近实际应用场景。
- 实验结果表明,现有模型在ToolHaystack上的表现远低于标准多轮设置,揭示了模型在长期鲁棒性方面的不足。
📝 摘要(中文)
大型语言模型(LLMs)在利用外部工具解决用户查询方面表现出强大的能力。然而,现有的大多数评估都假设工具的使用发生在短上下文中,对于模型在真实长期交互中的行为提供的洞察有限。为了填补这一空白,我们引入了ToolHaystack,这是一个用于测试长期交互中工具使用能力的基准。ToolHaystack中的每个测试实例都包含多个任务执行上下文和连续对话中的真实噪声,从而能够评估模型在多大程度上保持上下文并处理各种干扰。通过将此基准应用于14个最先进的LLM,我们发现,虽然当前的模型在标准的多轮设置中表现良好,但它们在ToolHaystack中经常表现出显著的困难,突出了其长期鲁棒性方面的关键差距,而这些差距在以前的工具基准中并未揭示。
🔬 方法详解
问题定义:现有工具增强语言模型的评估方法主要关注短上下文交互,缺乏对模型在真实长期交互中性能的有效评估。这导致我们无法充分了解模型在处理复杂、多任务、含噪声的长期对话中的鲁棒性和可靠性。现有方法的痛点在于无法模拟真实场景中的各种干扰因素,例如上下文切换、信息冗余和用户意图变化。
核心思路:ToolHaystack的核心思路是构建一个更贴近真实长期交互场景的基准测试,通过引入多任务执行上下文和真实噪声,模拟长期对话中的复杂性和干扰。这样可以更全面地评估工具增强语言模型在长期交互中的性能,并发现其潜在的不足之处。
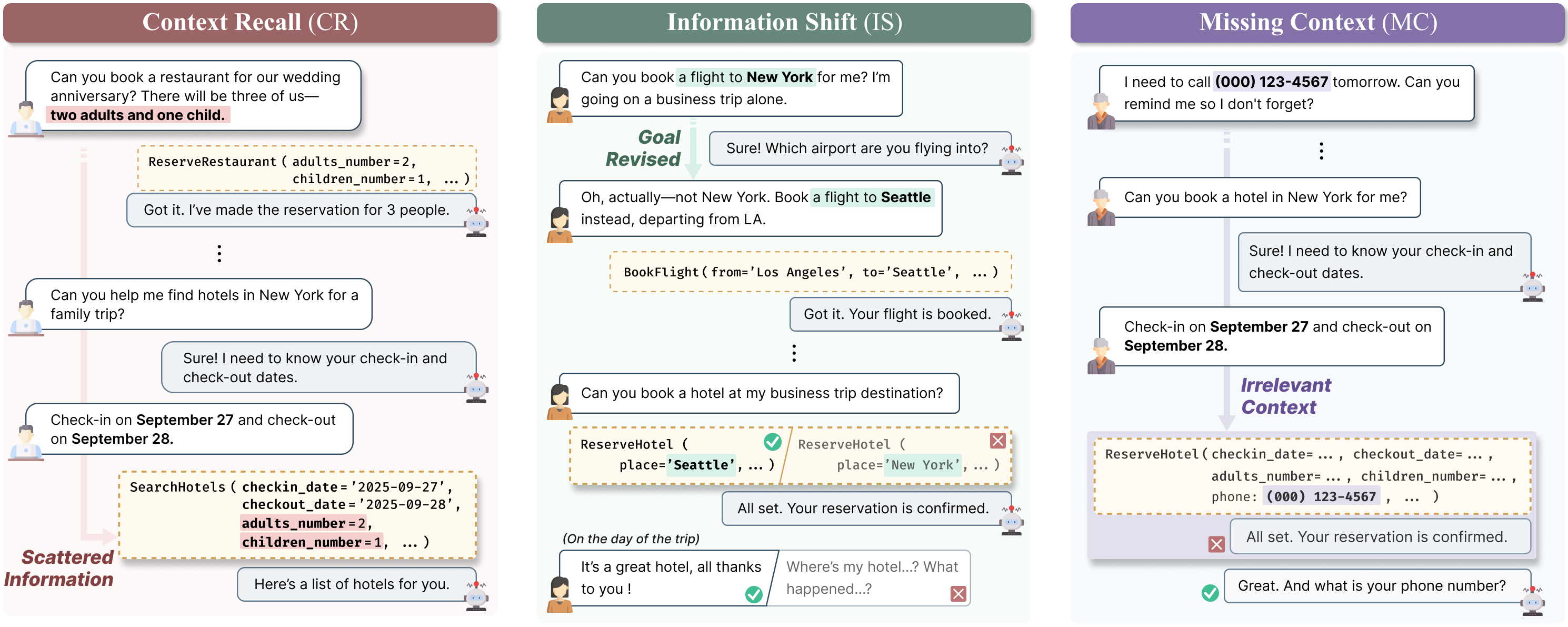
技术框架:ToolHaystack基准测试包含以下主要组成部分:1) 多任务执行上下文:每个测试实例包含多个需要模型完成的任务,这些任务之间可能存在依赖关系或相互干扰。2) 真实噪声:在对话中引入各种噪声,例如无关信息、冗余信息和用户意图变化,以模拟真实场景中的干扰。3) 评估指标:设计了一系列评估指标,用于衡量模型在长期交互中的性能,包括任务完成率、上下文保持能力和噪声处理能力。整体流程是,给定一个包含多任务上下文和噪声的对话,模型需要利用外部工具完成各项任务,并根据评估指标进行评估。
关键创新:ToolHaystack最重要的技术创新点在于其对真实长期交互场景的模拟。与以往的工具基准测试相比,ToolHaystack更加关注模型在处理复杂、多任务、含噪声的长期对话中的鲁棒性和可靠性。这种更贴近真实场景的评估方法可以更有效地发现模型在实际应用中的潜在问题。
关键设计:ToolHaystack的关键设计包括:1) 任务的多样性:选择了各种类型的任务,例如信息检索、数据分析和决策制定,以覆盖不同的应用场景。2) 噪声的类型:引入了各种类型的噪声,例如无关信息、冗余信息和用户意图变化,以模拟真实场景中的干扰。3) 评估指标的全面性:设计了一系列评估指标,用于衡量模型在长期交互中的性能,包括任务完成率、上下文保持能力和噪声处理能力。具体的参数设置和损失函数等技术细节取决于所使用的语言模型和外部工具。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的最先进的语言模型在ToolHaystack上的表现远低于标准的多轮设置,突出了其长期鲁棒性方面的关键差距。例如,某些模型在标准多轮对话中可以达到90%以上的任务完成率,但在ToolHaystack上的任务完成率仅为50%左右。这表明,现有模型在处理复杂、多任务、含噪声的长期对话方面仍存在很大的提升空间。
🎯 应用场景
ToolHaystack的研究成果可应用于评估和改进工具增强语言模型在各种长期交互场景中的性能,例如智能助手、客户服务和自动化工作流程。通过使用ToolHaystack,可以更好地了解模型在处理复杂、多任务、含噪声的长期对话中的鲁棒性和可靠性,从而开发出更实用、更可靠的工具增强语言模型。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.