AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
作者: Jiaxin Bai, Wei Fan, Qi Hu, Qing Zong, Chunyang Li, Hong Ting Tsang, Hongyu Luo, Yauwai Yim, Haoyu Huang, Xiao Zhou, Feng Qin, Tianshi Zheng, Xi Peng, Xin Yao, Huiwen Yang, Leijie Wu, Yi Ji, Gong Zhang, Renhai Chen, Yangqiu Song
分类: cs.CL, cs.AI
发布日期: 2025-05-29 (更新: 2025-08-01)
备注: 9 pages, preprint, code: https://github.com/HKUST-KnowComp/AutoSchemaKG
💡 一句话要点
AutoSchemaKG:通过动态模式归纳从Web规模语料库中自主构建知识图谱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱构建 自主学习 模式归纳 大型语言模型 多跳问答
📋 核心要点
- 现有知识图谱构建依赖预定义模式,限制了其灵活性和覆盖范围,难以适应快速变化的知识。
- AutoSchemaKG利用大型语言模型,从海量文本中自动提取三元组并归纳模式,实现知识图谱的自主构建。
- 实验表明,AutoSchemaKG构建的ATLAS知识图谱在多跳问答任务上表现出色,且模式与人工模式高度对齐。
📝 摘要(中文)
本文提出AutoSchemaKG,一个完全自主的知识图谱构建框架,无需预定义的模式。该系统利用大型语言模型同时从文本中提取知识三元组并归纳全面的模式,对实体和事件进行建模,并采用概念化将实例组织成语义类别。通过处理超过5000万份文档,我们构建了ATLAS(自动三元组链接和模式归纳)知识图谱系列,包含超过9亿个节点和59亿条边。该方法在多跳问答任务上优于最先进的基线,并提高了LLM的事实性。值得注意的是,我们的模式归纳在零人工干预的情况下,实现了与人工设计的模式92%的语义对齐,表明具有动态归纳模式的十亿级知识图谱可以有效地补充大型语言模型中的参数知识。
🔬 方法详解
问题定义:现有知识图谱构建方法通常需要预定义的模式(Schema),这限制了知识图谱的灵活性和覆盖范围。人工定义模式成本高昂且难以维护,无法适应快速变化的知识。此外,现有方法在处理大规模、多样化的Web文本时,难以有效地提取和组织知识。
核心思路:AutoSchemaKG的核心思路是利用大型语言模型(LLM)的强大能力,从海量文本中自动提取知识三元组,并动态地归纳出知识图谱的模式。通过概念化(Conceptualization)将实例组织成语义类别,从而构建一个无需预定义模式的、自主的知识图谱。
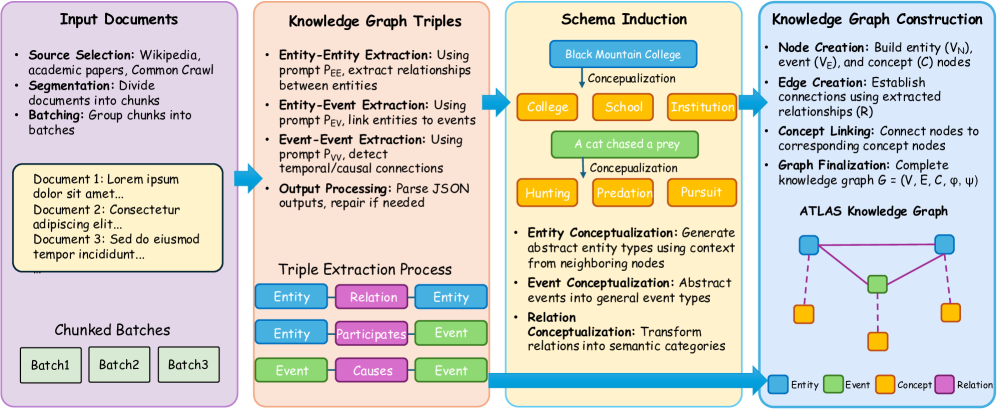
技术框架:AutoSchemaKG的整体框架包含以下主要模块:1) 知识提取模块:利用LLM从文本中提取知识三元组(实体-关系-实体/事件)。2) 模式归纳模块:基于提取的三元组,动态地归纳出知识图谱的模式,包括实体类型、关系类型等。3) 概念化模块:将提取的实例组织成语义类别,形成知识图谱的层次结构。4) 知识图谱构建模块:将提取的知识三元组和归纳的模式整合到知识图谱中。
关键创新:AutoSchemaKG最重要的创新点在于其完全自主的知识图谱构建流程,无需人工干预即可从海量文本中提取知识并构建知识图谱。与现有方法相比,AutoSchemaKG能够动态地适应新的知识和模式,从而构建更加全面和灵活的知识图谱。此外,该方法通过概念化模块,实现了知识图谱的语义组织,提高了知识图谱的可理解性和可利用性。
关键设计:AutoSchemaKG的关键设计包括:1) 使用特定prompt工程来指导LLM进行知识提取和模式归纳。2) 设计了有效的概念化算法,将实例组织成语义类别。3) 采用了高效的知识图谱存储和查询技术,以支持大规模知识图谱的处理。
🖼️ 关键图片
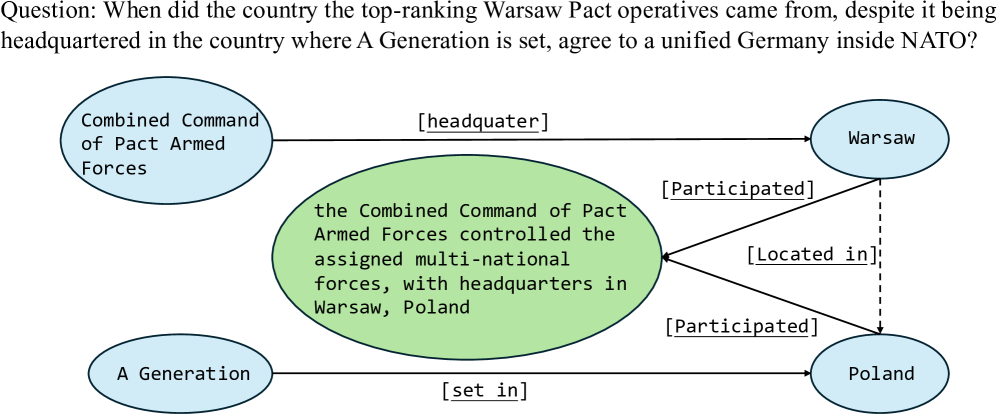
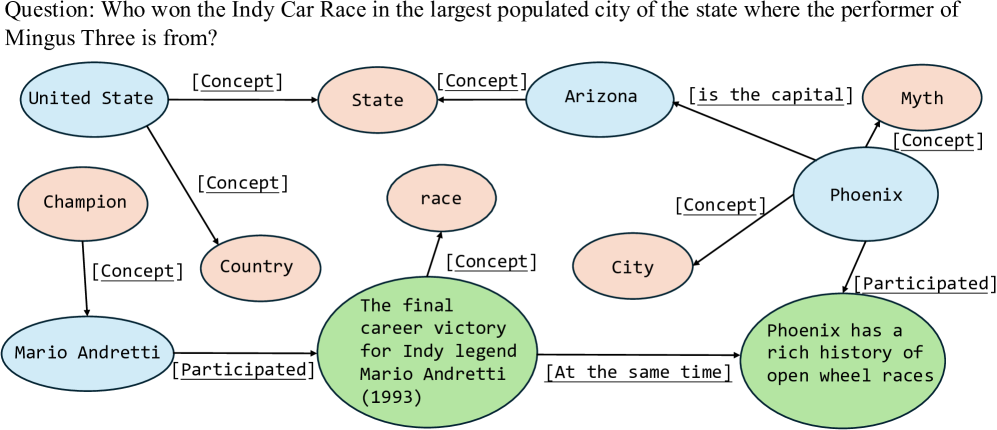
📊 实验亮点
AutoSchemaKG构建的ATLAS知识图谱包含超过9亿个节点和59亿条边。在多跳问答任务上,AutoSchemaKG优于最先进的基线方法。更重要的是,AutoSchemaKG的模式归纳在零人工干预的情况下,实现了与人工设计的模式92%的语义对齐,验证了其有效性和实用性。
🎯 应用场景
AutoSchemaKG在智能问答、信息检索、推荐系统等领域具有广泛的应用前景。它可以用于构建特定领域的知识图谱,为下游任务提供知识支持。此外,AutoSchemaKG还可以用于增强大型语言模型的事实性,提高其生成内容的准确性和可靠性。未来,该技术有望应用于自动化的知识发现和知识管理。
📄 摘要(原文)
We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 92\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.