Speech as a Multimodal Digital Phenotype for Multi-Task LLM-based Mental Health Prediction
作者: Mai Ali, Christopher Lucasius, Tanmay P. Patel, Madison Aitken, Jacob Vorstman, Peter Szatmari, Marco Battaglia, Deepa Kundur
分类: cs.CL, cs.MM
发布日期: 2025-05-28 (更新: 2025-07-23)
备注: 6 pages, 1 figure, 3 tables. The corresponding author is Mai Ali (maia dot ali at mail dot utoronto dot ca). Christopher Lucasius and Tanmay P. Patel contributed equally
💡 一句话要点
提出基于多模态LLM的语音数字表型方法,用于多任务心理健康预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 心理健康预测 语音分析 多任务学习 纵向分析 抑郁症检测
📋 核心要点
- 现有方法通常将语音视为单一模态,忽略了语音中蕴含的多模态信息,限制了心理健康预测的准确性。
- 论文提出将语音数据视为文本、声学特征和声音生物标志物的三模态数据,并结合多任务学习和纵向分析,提升预测性能。
- 实验结果表明,该方法在抑郁症早期预警数据集上取得了显著的性能提升,平衡准确率达到70.8%。
📝 摘要(中文)
本研究提出了一种将患者语音数据视为三模态多媒体数据源的方法,用于抑郁症检测。该方法探索了基于大型语言模型的架构在基于语音的抑郁症预测中的潜力,该架构集成了语音衍生的文本、声学特征和声音生物标志物。考虑到青少年抑郁症通常与多种疾病(如自杀意念和睡眠障碍)共病,本研究还通过同时预测抑郁症、自杀意念和睡眠障碍,将多任务学习(MTL)整合到研究中。此外,提出了一种纵向分析策略,该策略对多次临床交互中的时间变化进行建模,从而全面了解病情的发展。所提出的三模态、纵向MTL方法在抑郁症早期预警数据集上进行了评估,实现了70.8%的平衡准确率,高于所有单模态、单任务和非纵向方法。
🔬 方法详解
问题定义:现有方法在利用语音进行心理健康预测时,通常只关注语音的单一模态特征,例如文本或声学特征,忽略了语音中蕴含的丰富信息。此外,传统的单任务学习方法无法有效利用不同心理健康问题之间的关联性。同时,缺乏对患者随时间变化的纵向数据的分析,难以捕捉疾病的发展趋势。
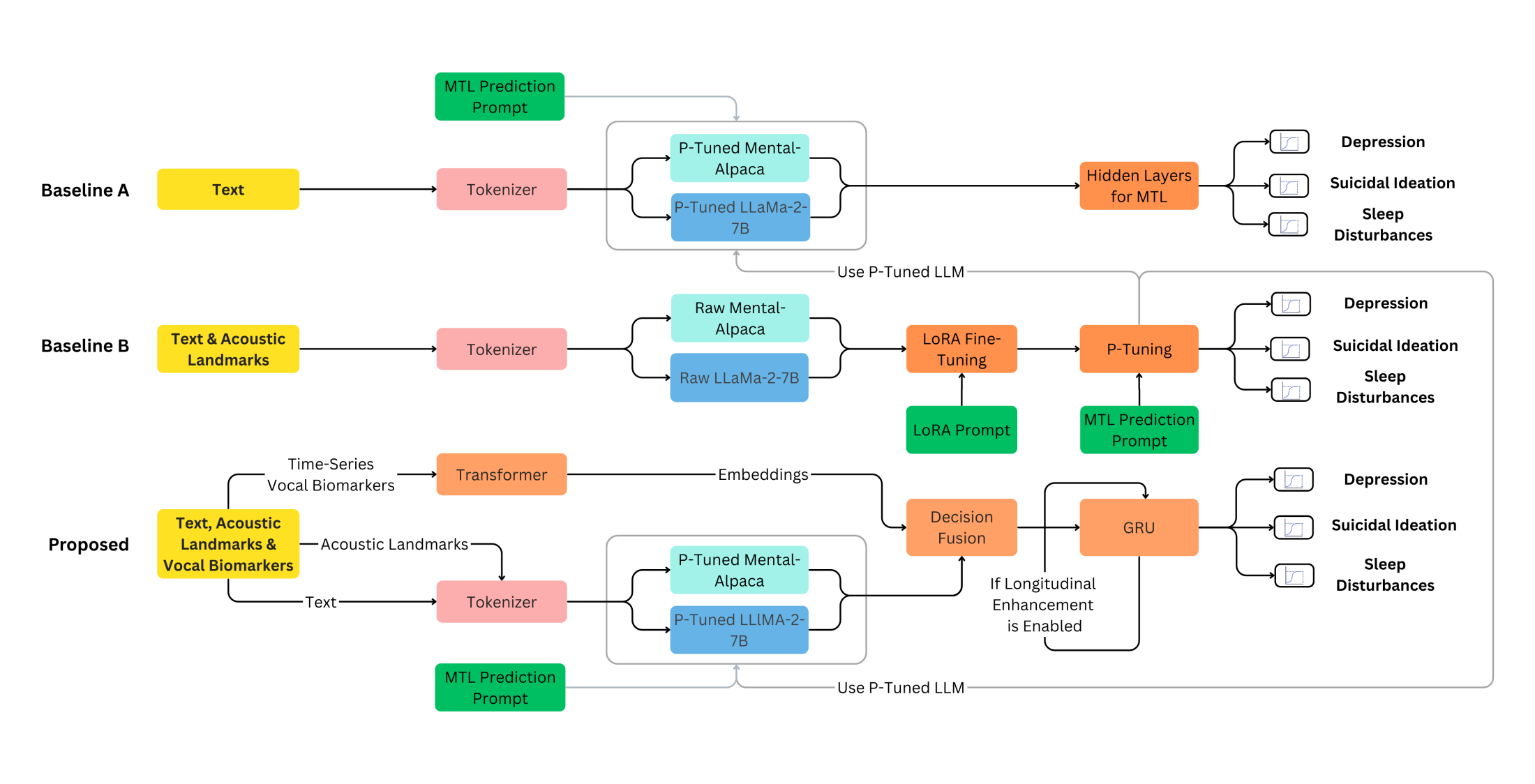
核心思路:论文的核心思路是将语音数据视为一种多模态的数字表型,包含文本、声学特征和声音生物标志物三种模态。通过融合这三种模态的信息,可以更全面地了解患者的心理状态。同时,采用多任务学习方法,同时预测抑郁症、自杀意念和睡眠障碍等多个相关问题,利用它们之间的关联性来提高预测准确率。此外,通过纵向分析,对患者在不同时间点的语音数据进行建模,捕捉疾病的发展趋势。
技术框架:整体框架包含以下几个主要模块:1) 语音特征提取模块,用于提取语音中的文本、声学特征和声音生物标志物;2) 多模态融合模块,用于将三种模态的信息进行融合;3) 多任务学习模块,用于同时预测抑郁症、自杀意念和睡眠障碍;4) 纵向分析模块,用于对患者在不同时间点的语音数据进行建模。具体流程是:首先,对语音数据进行预处理,然后提取三种模态的特征。接着,将这些特征输入到多模态融合模块中进行融合。然后,将融合后的特征输入到多任务学习模块中,同时预测多个心理健康问题。最后,利用纵向分析模块对患者在不同时间点的预测结果进行建模,捕捉疾病的发展趋势。
关键创新:论文的关键创新在于:1) 将语音数据视为一种多模态的数字表型,充分利用了语音中蕴含的丰富信息;2) 采用多任务学习方法,同时预测多个相关问题,利用它们之间的关联性来提高预测准确率;3) 提出了一种纵向分析策略,对患者在不同时间点的语音数据进行建模,捕捉疾病的发展趋势。
关键设计:论文中关键的设计包括:1) 使用预训练的大型语言模型(LLM)来提取语音中的文本特征;2) 使用深度学习模型来提取语音中的声学特征和声音生物标志物;3) 设计了一种多模态融合策略,将三种模态的信息进行有效融合;4) 设计了一种多任务学习损失函数,同时优化多个预测任务;5) 使用循环神经网络(RNN)或Transformer等模型来进行纵向分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在抑郁症早期预警数据集上取得了显著的性能提升,平衡准确率达到70.8%,高于所有单模态、单任务和非纵向方法。这表明,将语音数据视为多模态数据,并结合多任务学习和纵向分析,可以有效提高心理健康预测的准确性。相比于单模态方法,该方法能够更全面地捕捉患者的心理状态,从而做出更准确的判断。
🎯 应用场景
该研究成果可应用于心理健康领域的早期筛查和诊断,通过分析患者的语音数据,可以辅助医生进行抑郁症、自杀意念和睡眠障碍等疾病的诊断和风险评估。此外,该方法还可以用于远程心理健康监测,为患者提供个性化的治疗方案,并跟踪治疗效果。未来,该技术有望在心理健康领域发挥更大的作用,提高诊断效率,降低医疗成本。
📄 摘要(原文)
Speech is a noninvasive digital phenotype that can offer valuable insights into mental health conditions, but it is often treated as a single modality. In contrast, we propose the treatment of patient speech data as a trimodal multimedia data source for depression detection. This study explores the potential of large language model-based architectures for speech-based depression prediction in a multimodal regime that integrates speech-derived text, acoustic landmarks, and vocal biomarkers. Adolescent depression presents a significant challenge and is often comorbid with multiple disorders, such as suicidal ideation and sleep disturbances. This presents an additional opportunity to integrate multi-task learning (MTL) into our study by simultaneously predicting depression, suicidal ideation, and sleep disturbances using the multimodal formulation. We also propose a longitudinal analysis strategy that models temporal changes across multiple clinical interactions, allowing for a comprehensive understanding of the conditions' progression. Our proposed approach, featuring trimodal, longitudinal MTL is evaluated on the Depression Early Warning dataset. It achieves a balanced accuracy of 70.8%, which is higher than each of the unimodal, single-task, and non-longitudinal methods.