What Has Been Lost with Synthetic Evaluation?
作者: Alexander Gill, Abhilasha Ravichander, Ana Marasović
分类: cs.CL, cs.AI
发布日期: 2025-05-28 (更新: 2025-10-03)
备注: v3: Camera Ready
💡 一句话要点
评估LLM生成基准的有效性:揭示合成评估中信息损失
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准测试 阅读理解 数据生成 评估方法
📋 核心要点
- 现有评估基准构建成本高昂,且难以保证针对特定推理能力。
- 利用LLM生成评估数据,降低成本,但可能引入新的偏差和问题。
- 研究表明,LLM生成的基准在有效性上可行,但在难度上低于人工基准。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地用于数据生成。然而,创建评估基准对这种新兴范式提出了更高的要求。基准必须针对特定现象,惩罚利用捷径的行为,并且具有挑战性。通过两个案例研究,我们调查了LLM是否能够满足这些需求,即生成基于文本的推理基准,并将其与通过精心众包创建的基准进行比较。具体来说,我们评估了LLM生成的两个高质量阅读理解数据集(CondaQA和DROP)的有效性和难度。CondaQA评估关于否定的推理,而DROP针对关于数量的推理。我们发现,提示LLM可以生成这些数据集的变体,这些变体通常根据注释指南是有效的,而且成本仅为原始众包工作的一小部分。然而,我们表明,与人类编写的对应数据集相比,它们对LLM来说挑战性更低。这一发现揭示了使用LLM生成评估数据可能造成的损失,并呼吁批判性地重新评估这种日益普遍的基准创建方法的直接使用。
🔬 方法详解
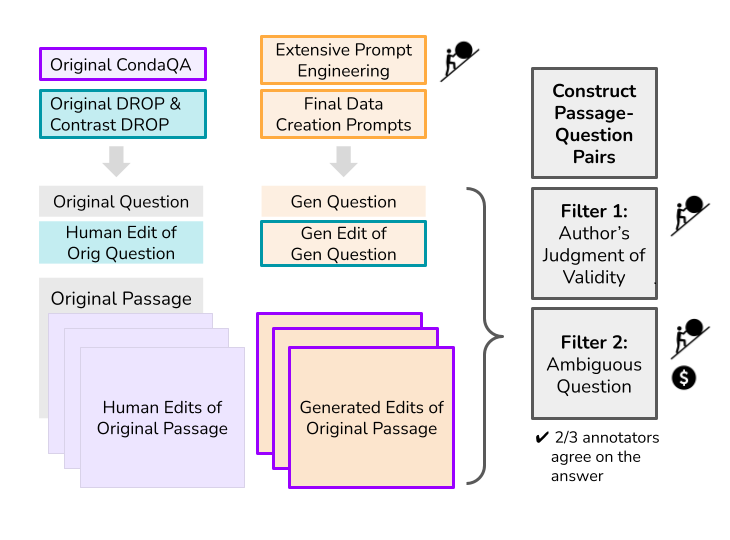
问题定义:论文旨在研究使用大型语言模型(LLMs)自动生成阅读理解评估基准的有效性。现有的人工构建基准方法成本高昂,且难以保证覆盖所有类型的推理能力。然而,直接使用LLM生成的数据集进行评估可能存在问题,因为这些数据集可能无法充分挑战LLM,或者包含LLM容易利用的捷径。
核心思路:论文的核心思路是通过对比LLM生成的基准和人工构建的基准,来评估LLM生成基准的质量。具体来说,论文关注两个关键方面:有效性(即生成的数据是否符合预期的注释指南)和难度(即LLM在生成的数据集上的表现是否与在人工数据集上的表现相当)。
技术框架:论文采用了案例研究的方法,选择了两个现有的高质量阅读理解数据集:CondaQA(侧重于否定推理)和DROP(侧重于数量推理)。然后,论文使用LLM生成了这两个数据集的变体。最后,论文在原始数据集和LLM生成的数据集上评估了LLM的性能,并比较了结果。
关键创新:论文的关键创新在于对LLM生成基准的有效性和难度进行了系统的评估。以往的研究主要关注LLM生成数据的流畅性和多样性,而忽略了其作为评估基准的质量。论文通过对比实验,揭示了LLM生成基准可能存在的局限性,并提出了对这种方法的批判性思考。
关键设计:论文使用了prompting的方式来指导LLM生成数据集。具体的prompt设计未知,但目标是让LLM生成与原始数据集具有相似结构和推理要求的问题。论文使用了标准的阅读理解模型来评估数据集的难度,并使用了标准的评估指标(如F1 score)来衡量模型的性能。具体的模型架构和训练细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM可以生成在有效性上与人工数据集相当的阅读理解基准,但这些基准对LLM来说难度更低。这意味着使用LLM生成的基准可能会高估LLM的实际性能。具体性能数据和提升幅度在论文中未明确给出。
🎯 应用场景
该研究成果对自然语言处理领域的基准测试和模型评估具有重要意义。它可以帮助研究人员更好地理解LLM生成数据的局限性,并指导他们更有效地使用LLM来构建评估基准。此外,该研究还可以应用于其他领域,例如数据增强和合成数据生成。
📄 摘要(原文)
Large language models (LLMs) are increasingly used for data generation. However, creating evaluation benchmarks raises the bar for this emerging paradigm. Benchmarks must target specific phenomena, penalize exploiting shortcuts, and be challenging. Through two case studies, we investigate whether LLMs can meet these demands by generating reasoning over-text benchmarks and comparing them to those created through careful crowdsourcing. Specifically, we evaluate both the validity and difficulty of LLM-generated versions of two high-quality reading comprehension datasets: CondaQA, which evaluates reasoning about negation, and DROP, which targets reasoning about quantities. We find that prompting LLMs can produce variants of these datasets that are often valid according to the annotation guidelines, at a fraction of the cost of the original crowdsourcing effort. However, we show that they are less challenging for LLMs than their human-authored counterparts. This finding sheds light on what may have been lost by generating evaluation data with LLMs, and calls for critically reassessing the immediate use of this increasingly prevalent approach to benchmark creation.