AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
作者: Feng Luo, Yu-Neng Chuang, Guanchu Wang, Hoang Anh Duy Le, Shaochen Zhong, Hongyi Liu, Jiayi Yuan, Yang Sui, Vladimir Braverman, Vipin Chaudhary, Xia Hu
分类: cs.CL, cs.LG
发布日期: 2025-05-28 (更新: 2026-01-08)
💡 一句话要点
提出AutoL2S框架,通过自适应长短推理提升大语言模型效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理效率 长短推理 蒸馏学习 自适应推理
📋 核心要点
- 现有大语言模型蒸馏后存在过度推理问题,导致推理成本高昂,但直接缩短推理长度会降低精度。
- AutoL2S框架通过学习切换token,实现实例级别的长短推理选择,从而自适应地调整推理长度。
- 实验表明,AutoL2S能有效减少推理长度,同时保持精度,在推理效率和准确性之间取得良好平衡。
📝 摘要(中文)
具备推理能力的大语言模型(LLMs)在复杂任务上表现出色,但经过蒸馏后常出现过度思考,即使对于简单输入也会生成不必要的长链式思考(CoT)推理,导致高昂的推理成本。然而,简单地缩短推理长度会降低推理精度,因为简洁的推理可能不足以应对某些输入,并且缺乏显式监督。我们提出了Auto Long-Short Reasoning (AutoL2S),一个蒸馏框架,使非推理LLMs能够进行彻底的思考,但仅在必要时才这样做。AutoL2S首先学习一个轻量级的切换token,该token具有经过验证的长短CoT,以实现实例级的长短推理选择。然后,它利用切换token在GRPO风格的损失中诱导的长短推理rollout,以提高推理效率,同时保持准确性。实验表明,AutoL2S有效地减少了高达71%的推理长度,同时精度损失最小,从而在token长度和推理时间方面实现了明显更好的权衡,同时保持了准确性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在蒸馏后出现的过度推理问题。即使对于简单的输入,蒸馏后的模型也会生成过长的推理链,导致不必要的计算开销。直接缩短推理链虽然可以降低成本,但会牺牲推理的准确性,因为某些复杂问题需要更长的推理过程。因此,如何在保证准确性的前提下,减少不必要的推理长度,是本文要解决的核心问题。
核心思路:AutoL2S的核心思路是让模型学会根据输入的不同,自适应地选择长推理或短推理。对于简单的问题,模型应该能够快速给出答案,而对于复杂的问题,则需要进行更深入的思考。为了实现这一目标,论文引入了一个切换token,用于控制推理的长度。
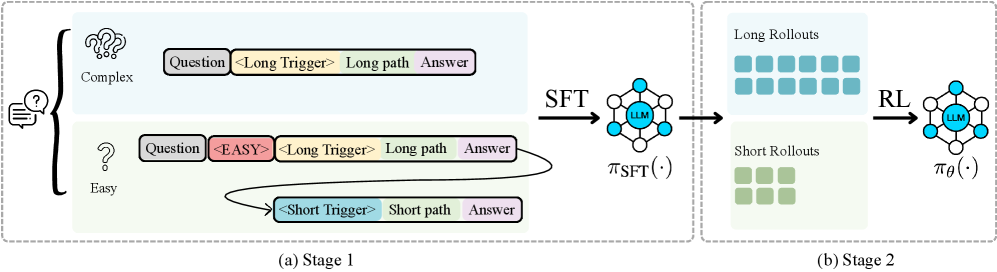
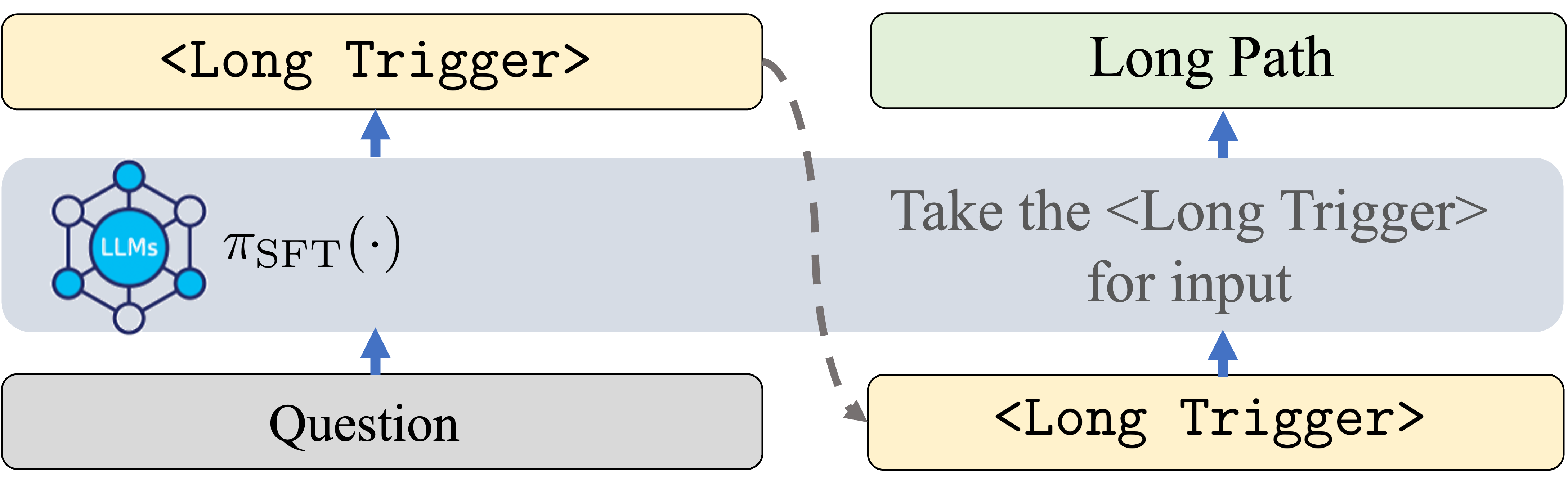
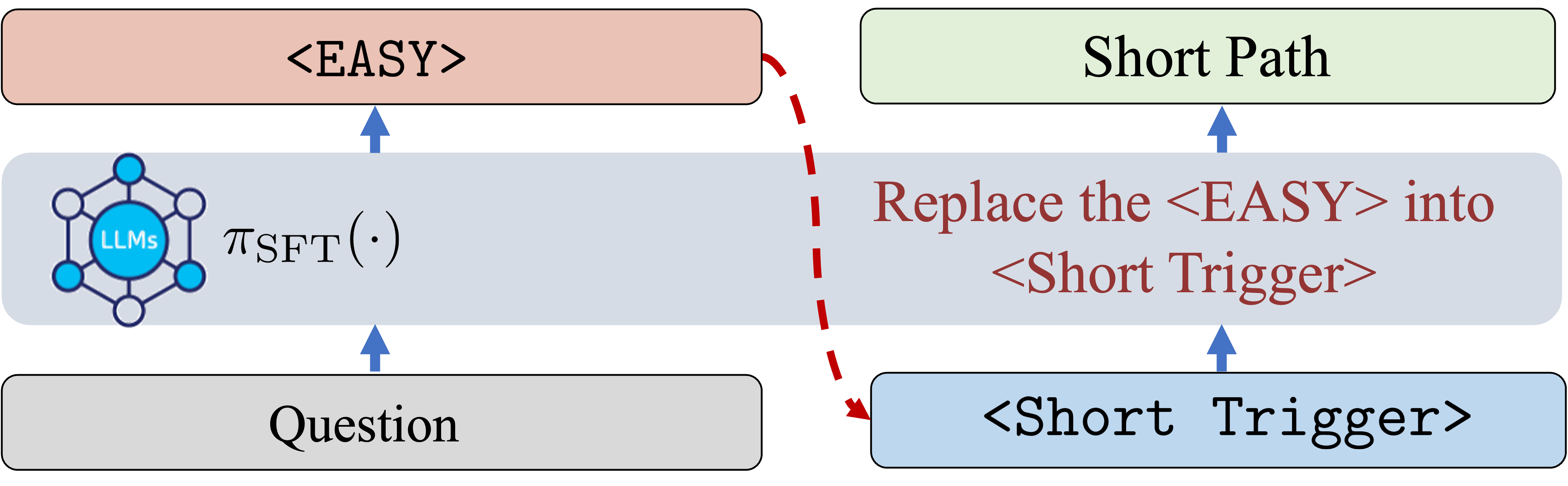
技术框架:AutoL2S框架主要包含两个阶段:首先,学习一个轻量级的切换token,该token能够根据输入选择长推理或短推理。论文通过验证长短CoT来训练这个切换token。其次,利用切换token在GRPO风格的损失函数中诱导长短推理rollout,从而提高推理效率,同时保持准确性。GRPO (Gradient Ratio Policy Optimization) 是一种策略优化方法,用于平衡推理的效率和准确性。
关键创新:AutoL2S的关键创新在于引入了切换token,实现了实例级别的长短推理选择。与以往的固定推理长度方法不同,AutoL2S能够根据输入的不同,动态地调整推理的长度,从而在推理效率和准确性之间取得更好的平衡。此外,使用GRPO风格的损失函数,能够有效地利用长短推理rollout,进一步提高推理效率。
关键设计:切换token的设计是关键。论文通过对比长短CoT来训练切换token,使其能够准确地判断何时需要长推理,何时需要短推理。GRPO风格的损失函数也至关重要,它能够引导模型学习更有效的推理策略。具体的损失函数设计和参数设置在论文中有详细描述,例如,如何平衡长短推理的损失权重,以及如何调整GRPO的学习率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AutoL2S能够有效减少推理长度,最高可达71%,同时精度损失最小。在多个基准测试中,AutoL2S在token长度和推理时间方面都优于现有方法,实现了更好的效率和准确性权衡。例如,在某些数据集上,AutoL2S在保持精度基本不变的情况下,将推理时间缩短了近一半。
🎯 应用场景
AutoL2S可应用于各种需要高效推理的大语言模型应用场景,例如智能客服、自动问答、文本摘要等。通过减少不必要的推理计算,可以显著降低部署成本,提高响应速度,并提升用户体验。该方法还有潜力应用于边缘设备,使得资源受限的设备也能运行复杂的语言模型。
📄 摘要(原文)
Reasoning-capable large language models (LLMs) achieve strong performance on complex tasks but often exhibit overthinking after distillation, generating unnecessarily long chain-of-thought (CoT) reasoning even for simple inputs and incurring high inference cost. However, naively shortening reasoning length can degrade reasoning accuracy, as concise reasoning may be insufficient for certain inputs and lacks explicit supervision. We propose Auto Long-Short Reasoning (AutoL2S), a distillation framework that empowers non-reasoning LLMs to think thoroughly but only when necessary. AutoL2S first learns a lightweight switching token with verified long-short CoTs to enable instance-wise long-short reasoning selection. Then it leverages long-short reasoning rollouts induced by a switching token in a GRPO-style loss to improve reasoning efficiency while maintaining accuracy. Experiments demonstrate that AutoL2S effectively reduces reasoning length up to 71% with minimal accuracy loss, yielding markedly better trade-off in token length and inference time while preserving accuracy.